Cloudera's Distribution Including Apache Hadoop (CDH) is a popular Hadoop distribution. This document describes how to use CHDFS on CDH to separate big data computing and storage and provide a flexible big data solution at low costs.
CHDFS supports the following big data components:
Component
Supported by CHDFS
Service Component Restart Required
YARN
Yes
NodeManager
YARN
Yes
NodeManager
Hive
Yes
HiveServer and HiveMetastore
Spark
Yes
NodeManager
Sqoop
Yes
NodeManager
Presto
Yes
HiveServer, HiveMetastore, and Presto
Flink
Yes
No
Impala
Yes
No
EMR
Yes
No
Self-built component
To be supported in the future
No
HBase
Not recommended
No
Version Dependency
The dependent component versions used in this document are as follows:
CDH 5.16.1
Hadoop 2.6.0
Directions
Storage environment configuration
1. Log in to Cloudera Manager (CDH management page).
2. On the system homepage, select Configuration > Service-Wide > Advanced to enter the advanced configuration code snippet page as shown below:
3. Enter the CHDFS configuration in the code box of Cluster-wide Advanced Configuration Snippet (Safety Valve) for core-site.xml.
<!--Temporary directory of the local cache. For data read/write, data will be written to the local disk when the memory cache is insufficient. This path will be created automatically if it does not exist-->
<property>
<name>fs.ofs.tmp.cache.dir</name>
<value>/data/emr/hdfs/tmp/chdfs/</value>
</property>
<!--appId-->
<property>
<name>fs.ofs.user.appid</name>
<value>1250000000</value>
</property>
The following are the required CHDFS configuration items (which need to be added to core-site.xml). For other CHDFS configuration items, please see Mounting CHDFS Instance.
CHDFS Configuration Item
Value
Description
fs.ofs.user.appid
1250000000
User appid
fs.ofs.tmp.cache.dir
/data/emr/hdfs/tmp/chdfs/
Temporary directory of the local cache
fs.ofs.impl
com.qcloud.chdfs.fs.CHDFSHadoopFileSystemAdapter
CHDFS implementation class for FileSystem, which is fixed at com.qcloud.chdfs.fs.CHDFSHadoopFileSystemAdapter
fs.AbstractFileSystem.ofs.impl
com.qcloud.chdfs.fs.CHDFSDelegateFSAdapter
CHDFS implementation class for AbstractFileSystem, which is fixed at com.qcloud.chdfs.fs.CHDFSDelegateFSAdapter
4. Click the HDFS service to deploy the client configuration, and the above core-site.xml configuration will be updated to the servers in the cluster.
5. Place the latest CHDFS SDK package under the JAR package path of the CDH HDFS service as shown below, where the path should be replaced with the actual value:
(1) Configure HDFS as instructed in Data migration and place the CHDFS SDK JAR package in the corresponding directory of HDFS.
(2) On the CDH system homepage, find YARN and restart NodeManager (you don't need to restart NodeManager for TeraGen but need to do so for TeraSort due to internal business logic; therefore, we recommend you restart NodeManager in both cases).
Sample
The following uses TeraGen and TeraSort in a standard Hadoop test as an example:
hadoop jar ./hadoop-mapreduce-examples-2.7.3.jar teragen -Dmapred.map.tasks=41099 cosn://examplebucket-1250000000/teragen_5/
hadoop jar ./hadoop-mapreduce-examples-2.7.3.jar terasort -Dmapred.map.tasks=4 cosn://examplebucket-1250000000/teragen_5/ cosn://examplebucket-1250000000/result14
Note:
Please replace the part after ofs://schema with the mount point path of your CHDFS instance.
2. Hive
2.1 MR engine
Directions
(1) Configure HDFS as instructed in Data migration and place the CHDFS SDK JAR package in the corresponding directory of HDFS.
(2) On the CDH homepage, find Hive and restart the HiveServer2 and HiveMetastore roles.
Sample
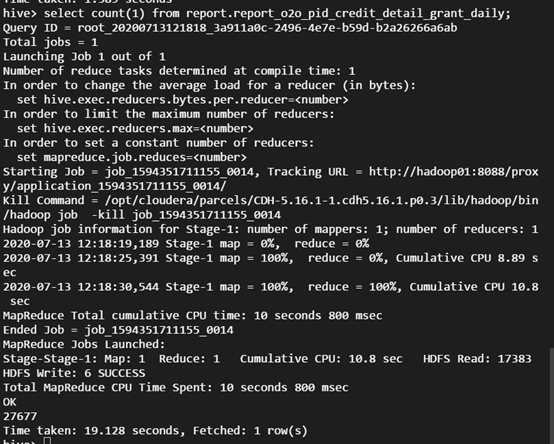
For a user's real business query, for example, run the Hive command line to create a location as a sharded table on CHDFS:
select count(1) from report.report_o2o_pid_credit_detail_grant_daily;
You will see the following results:
2.2 Tez engine
For the Tez engine, you need to import the CHDFS JAR package into the compressed package of Tez. The following takes apache-tez.0.8.5 as an example for description:
Directions
(1) Find the Tez package installed on the CDH cluster and decompress it, such as /usr/local/service/tez/tez-0.8.5.tar.gz.
(2) Place the CHDFS JAR package in the decompressed directory, recompress it, and output a compressed package.
(3) Upload the new compressed package to the path specified by tez.lib.uris (if it already exists, directly replace it).
(4) On the CDH homepage, find Hive and restart HiveServer and HiveMetastore.
3. Spark
Directions
(1) Configure HDFS as instructed in Data migration and place the CHDFS SDK JAR package in the corresponding directory of HDFS.
(2) Restart NodeManager.
Sample
The following takes the Spark example word count test conducted with CHDFS as an example.
(1) Configure HDFS as instructed in Data migration and place the CHDFS SDK JAR package in the corresponding directory of HDFS.
(2) Place the CHDFS SDK JAR package in the presto directory (such as /usr/local/services/cos_presto/plugin/hive-hadoop2).
(3) As Presto doesn't load gson-2.*.*.jar under hadoop common, you also need to place gson-2.*.*.jar in the presto directory (such as /usr/local/services/cos_presto/plugin/hive-hadoop2. Only CHDFS depends on Gson).
(4) Restart HiveServer, HiveMetaStore, and Presto.
Sample
The following takes creating a location with Hive as a CHDFS table query as an example:
select * from chdfs_test_table where bucket is not null limit 1;
Note:
chdfs_test_table is the table whose location is ofs scheme.