Spark running on Kubernetes can use GooseFS as the data access layer. This article explains how to use GooseFS in Kubernetes environment to speed up Spark data access.
Currently, there are two main ways to use GooseFS in Kubernetes to speed up Spark data access:
Deploy and run GooseFS Runtime Pods and Spark Runtime to accelerate Spark computing applications based on Fluid distributed data orchestration and acceleration engine (Fluid Operator architecture).
Run Spark on GooseFS in Kubernetes (Kubernetes Native deployment architecture).
Running Spark on GooseFS in Kubernetes
Prerequisites
1. Spark on Kubernetes uses the Kubernetes Native deployment and operation architecture recommended by the Spark official website. For detailed deployment methods, see Spark official website document.
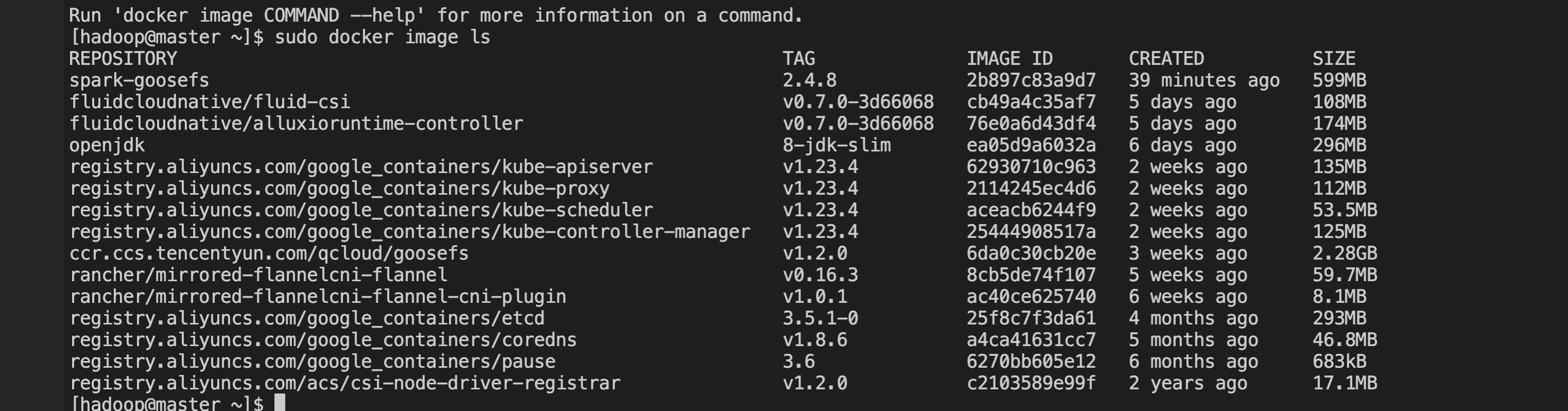
2. The GooseFS cluster is deployed. For GooseFS cluster deployment, see Console quick start.
Notes:
Note: When deploying GooseFS Worker, you need to configure goosefs.worker.hostname=$(hostname -i), otherwise the client in the Spark pod will be unable to resolve the GooseFS Worker host address.
First, ensure the GooseFS cluster has been started and the container can access the GooseFS Master/Worker IP and port, then follow the steps below to conduct test verification.
1. Create a namespace for testing in GooseFS, such as /spark-cosntest, and add test data files.
Note:
We recommend that you avoid using permanent keys in the configuration. Configuring sub-account keys or temporary keys can help improve your business security. When authorizing a sub-account, grant only the permissions of the operations and resources that the sub-account needs, which helps avoid unexpected data leakage.
If you must use a permanent key, it is advisable to limit its permission scope by restricting executable operations, resource scope and conditions (such as access IP) to enhance usage security.
# Use sub-account keys or temporary keys to complete the configuration and enhance security. When authorizing sub-accounts, grant executable operations and resources on demand.