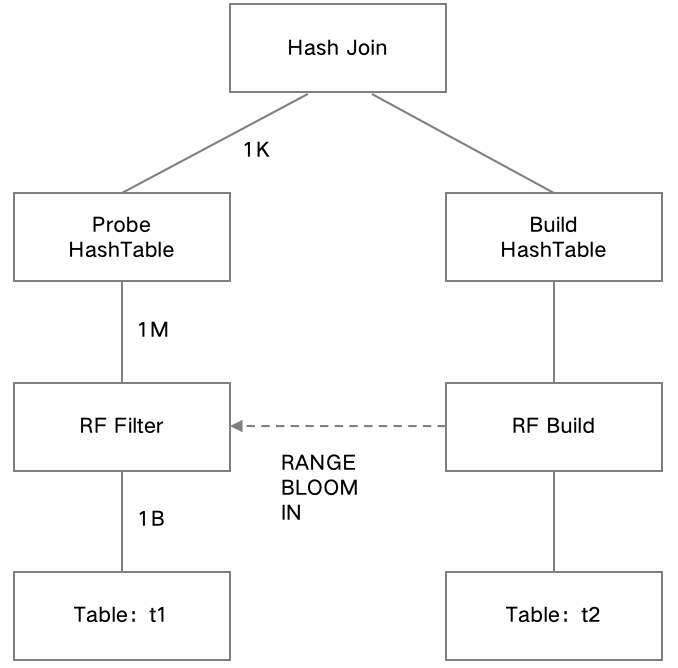
HASH JOIN is a commonly used join algorithm in databases that accelerates the join process by using hash tables. It typically consists of two phases: Build and Probe. When the Probe side has a large volume of data but produces a small output, enabling the Runtime Filter can help pre-filter some of the data, thereby improving performance.
The Runtime Filter in the read-only analysis engine consists of two components: RF Build and RF Filter. RF Build is applied on the Build side of a HASH JOIN to construct the Runtime Filter, while RF Filter is applied on the TableScan of the Probe side of the corresponding HASH JOIN to filter data early and enhance performance.
Runtime Filter Types
Local Runtime Filter
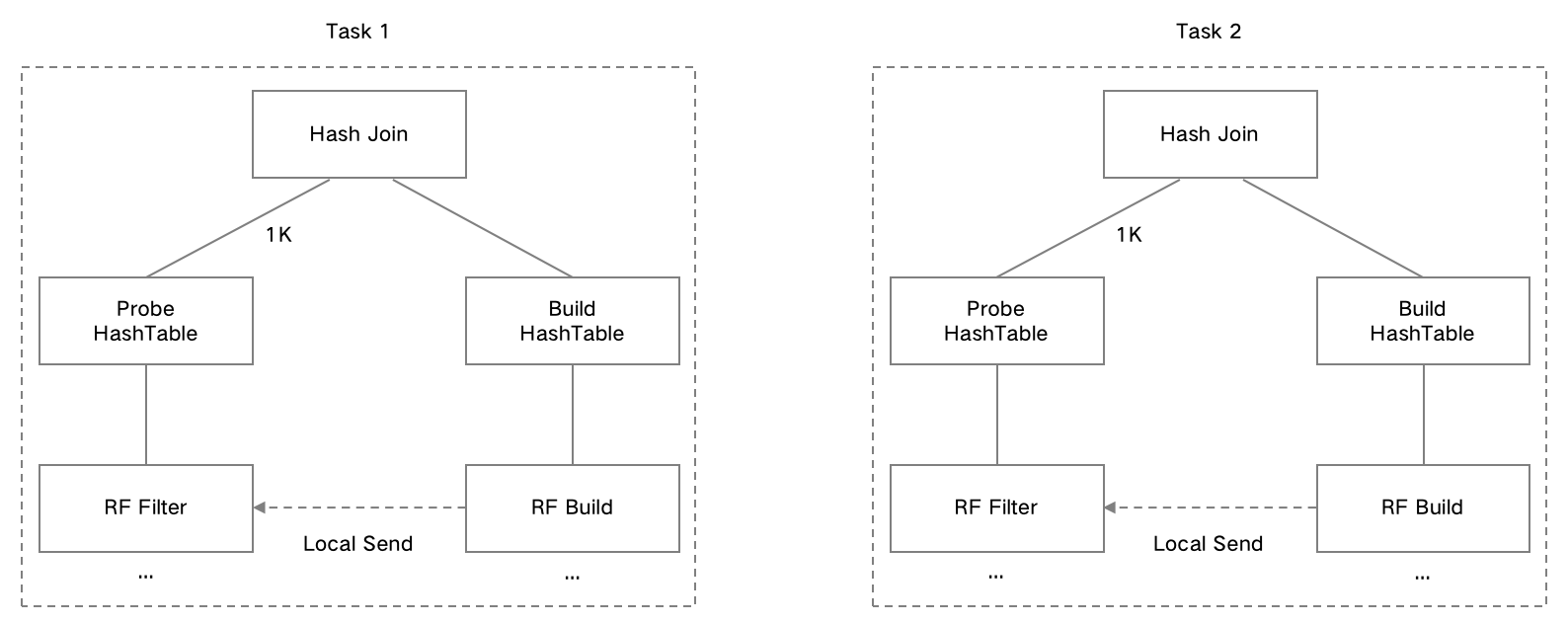
A Local Runtime Filter is typically used in join scenarios where the data is not shuffled. In this case, the Runtime Filter built on the current node is sufficient for the Probe side, eliminating the need for network transmission. The filter data can be passed directly to the Probe side for immediate use.
As shown in the figure above, when a JOIN is performed and the Build table is not shuffled, the Runtime Filter Build operator within the same execution plan sends the constructed filter data directly to the corresponding Filter Probe component in the plan.
Global Runtime Filter
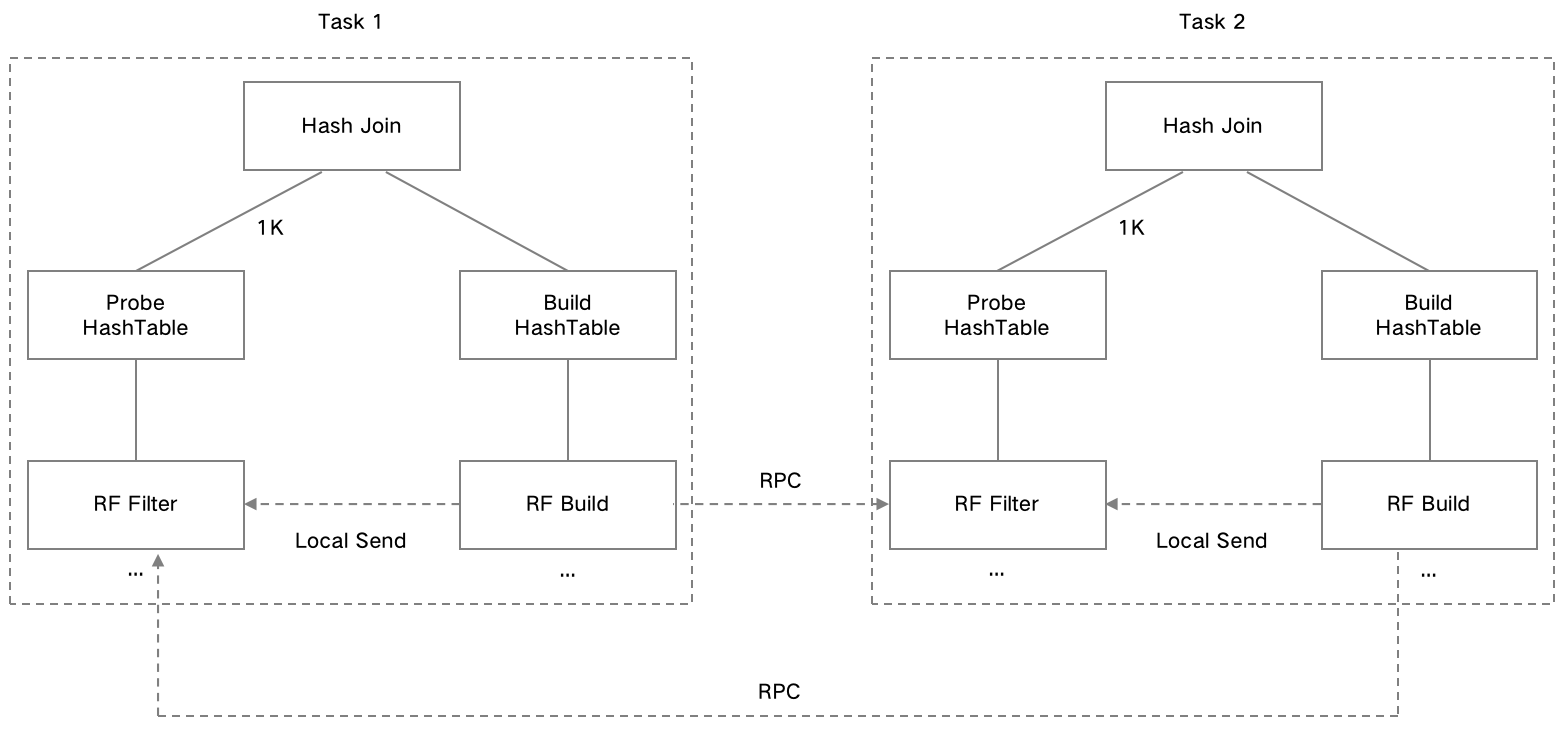
When JOIN data is shuffled across different nodes for construction, the Runtime Filter built by the current node alone is not sufficient to meet the filtering requirements. In this case, the node should receive Runtime Filters from other nodes. After all Runtime Filters from the participating nodes are merged, the filter can then be used.
When a JOIN is performed and the data from the Build table is shuffled, the Runtime Filter built by the Runtime Filter Build operator in the current execution plan is incomplete. In this case, the Runtime Filter should receive and merge filter data not only from the current plan's operator but also from other operators within the same execution plan. Only after the merging is complete can the Runtime Filter be used.
Filter Types
When you select a filter algorithm, one or more of the following filtering methods are typically chosen based on the data distribution.
Bloom Filter
Bloom Filter is a classic filtering algorithm that determines data existence using multiple hash functions. In the Runtime Filter, the size of the Bloom Filter is typically determined by the data's NDV. Although Bloom Filters may produce false positives, meaning some data that should be filtered is not, such data will still be eliminated during the Probe phase of the JOIN.
MIN_MAX Filter
The MIN_MAX Filter collects the maximum and minimum values from the Build side data. During filtering, it checks whether the incoming data falls within this range. If the data is outside the range, it will be filtered out. This type of filter is particularly effective when the Build side data is distributed across a well-defined value range.
IN Filter
The IN Filter is designed for scenarios with a low NDV. In this case, all values of the column are directly sent to the Probe side for matching.
Runtime Filter in the Read-Only Analysis Engine
Enabling or Disabling the Runtime Filter
By default, the Runtime Filter in the read-only analysis engine is enabled. You can use the following settings to enable or disable it.
mysql>setlibra_enable_runtime_filter=ON;
mysql>setlibra_enable_runtime_filter=OFF;
After it is enabled, the optimizer will assess JOIN operations and automatically apply the Runtime Filter when the conditions are met.
If you want to force the Runtime Filter to be enabled for all JOIN operations, you can configure the following parameter in addition to the parameter mentioned above.
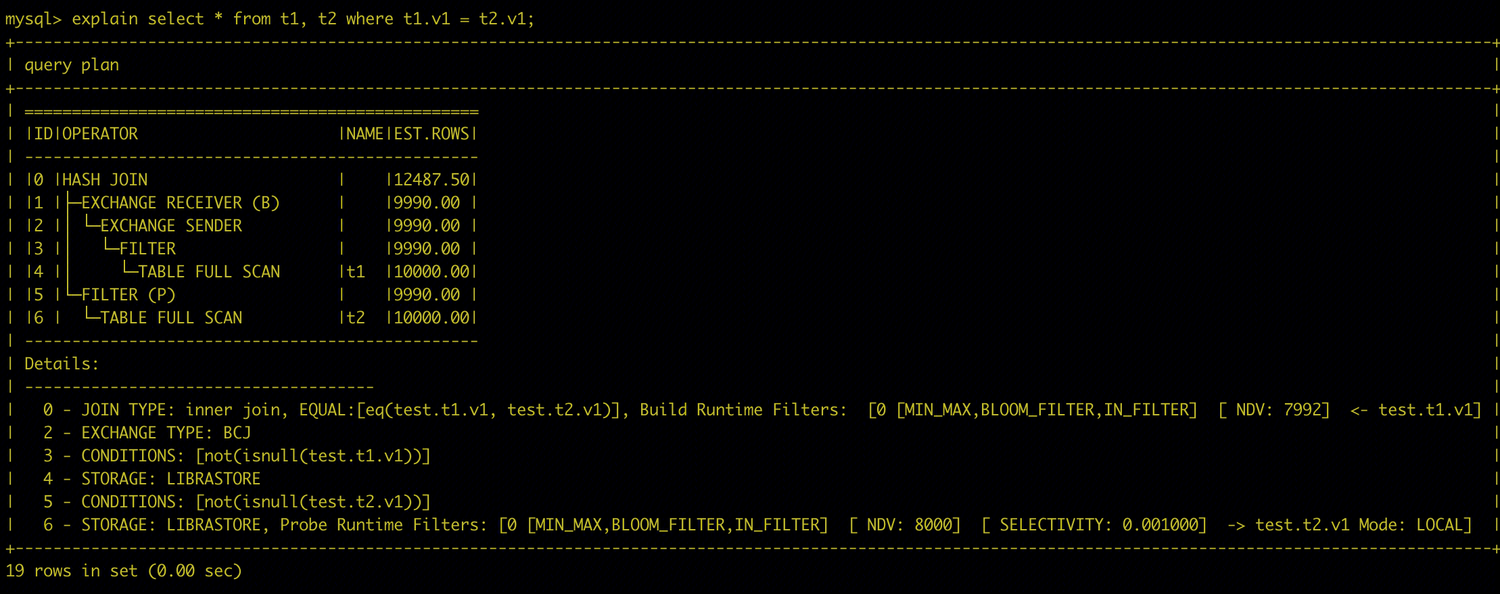
As shown below, this is a Local Runtime Filter plan. Three types of Runtime Filters are assigned to the JOIN operation. In this scenario, there is no data redistribution between the Build side and the Probe side of the HASH JOIN.
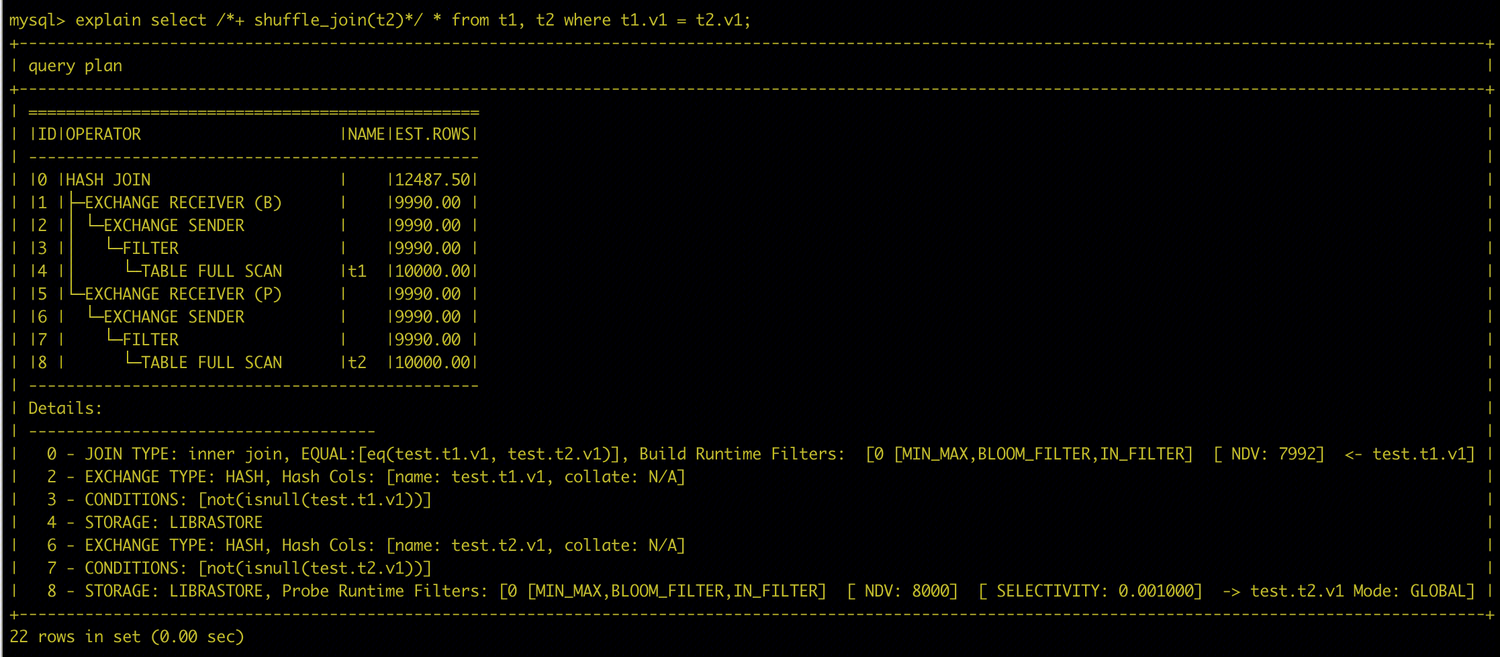
The plan shown below represents a Global Runtime Filter. In this case, data is redistributed between the Build side and the Probe side. The Runtime Filter can be applied before the data is transmitted over the network, reducing network overhead and the cost of subsequent JOIN operations, thereby improving overall performance.
Adjusting Runtime Filter Parameters
The following parameters can be adjusted for the Runtime Filter.
libra_enable_runtime_filter indicates whether the Runtime Filter is enabled.
Attribute
Description
Parameter Type
BOOL.
Default Value
ON.
Value range
ON: Enables the Runtime Filter.
OFF: Disables the Runtime Filter.
Scope
Global & Session.
SET_VAR Hint supported
Yes.
libra_runtime_filter_type specifies the types of Runtime Filters that can be assigned.
Attribute
Description
Parameter Type
VARCHAR.
Default Value
MIN_MAX, BLOOM_FILTER, and IN_FILTER.
Value range
BLOOM_FILTER: Builds a Bloom Filter on the JOIN key from the Build side to filter data on the Probe side.
MIN_MAX: Builds the minimum and maximum values of the JOIN key from the Build side to filter data on the Probe side.
IN: Builds a value list of the JOIN key from the Build side to filter data on the Probe side.
Empty string: Indicates that the Runtime Filter feature is disabled.
Scope
Global & Session.
SET_VAR Hint supported
Yes.
libra_enable_cost_based_runtime_filter indicates whether cost-based Runtime Filter assignment is enabled. If it is disabled, all Runtime Filters will be generated by default.
libra_max_in_runtime_filter_ndv specifies the maximum NDV allowed on the Build side when an IN type Runtime Filter is generated in the cost-based Runtime Filter assignment.