TDSQL for MySQL is a distributed edition of TencentDB for MariaDB. You can use TDSQL for MySQL if you anticipate that your business will grow so rapidly that the stand-alone edition, i.e. MariaDB, will no longer be able to support it.
Overview
Data sharding
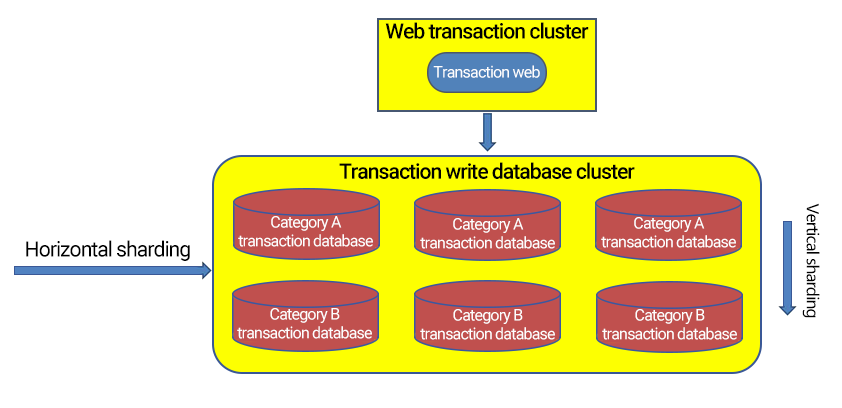
In a high-performance concurrent internet architecture, the performance bottleneck usually occurs in the database server, especially when the number of users of the business reaches more than one million. In this case, you can cope with problems such as database performance and scalability by performing reasonable data sharding at the data layer. Database sharding can be performed in two dimensions: vertical sharding (by feature) and horizontal sharding.
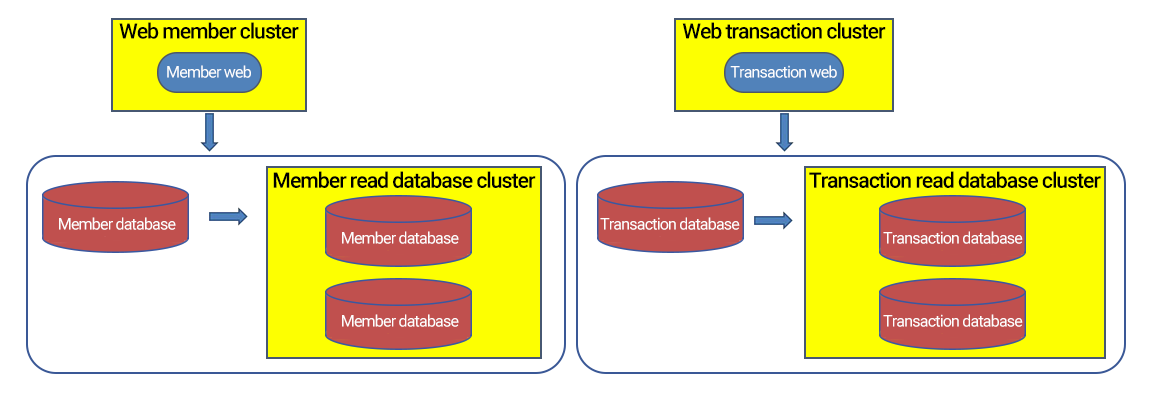
Vertical sharding is sharding by feature, which is closely associated with the business and has direct implementation logic. For example, an ecommerce platform shards data by feature into membership database, commodity database, transaction database, logistics database, etc. However, vertical sharding cannot completely handle the pressure as the load and capacity of a single database server is limited, which will become a bottleneck as the business grows. To deal with these problems, horizontal sharding is commonly used.
Horizontal sharding is to split the data of a table across multiple physically independent database servers according to certain rules to form "separate" database "shards". Multiple shards together form a logically complete database instance.
Sharding rules
A relational database is a two-dimensional model. To shard data, it is usually necessary to find a shardkey field to determine the sharding dimension. Then, a rule needs to be defined to actually shard the database. You need to comprehensively evaluate your business needs to find a suitable sharding rule. Several common sharding rules are described below:
1. Based on date order, such as sharding by year (one shard for 2015 and another for 2016).
Advantages: Simple and easy to query.
Disadvantages: The server performance for the current (e.g., 2016) hot data may be insufficient, while the storage performance for cold data is idle.
2. Based on the modulo of user ID, where the value ranges of the ID field after modulo operation are spread across different databases.
Advantages: The performance is relatively balanced and all data of the same user is in the same database.
Disadvantages: This may lead to data skew (for example, when a merchant system is designed, the data of one merchant of large-scale business mall may be more than that of thousands of merchants of small-scale business).
3. Based on the modulo of primary key, where the value ranges of the primary key field after modulo operation are spread across different databases.
Advantages: The performance is relatively balanced, data skew seldom occurs, and all data of the same primary key is in the same database.
Disadvantages: Data is randomly distributed, and some business logics may require cross-shard join operations that are not supported directly.
In terms of sharded data source management, there are currently two modes:
1. Client mode: The data sources of multiple shards are managed by the configuration in the business program module, and the reading, writing, and data integration of the shards are performed within the business program.
2. Middleware proxy mode: A middleware proxy is built on the frontend of the sharding databases which are imperceptible to the frontend application.
TDSQL for MySQL
Automatic horizontal sharding (sharding databases and splitting tables)
TDSQL for MySQL is a distributed database service deployed in Tencent Cloud that is compatible with MySQL protocol and syntax and supports automatic sharding (horizontal sharding). With a distributed database, your business obtains a complete logical database table which is split and distributed evenly across multiple physical shard nodes on the backend. Currently, TDSQL deploys the primary-secondary architecture by default and provides a full set of solutions for disaster recovery, backup, restoration, monitoring, and migration, making it ideal for storing terabytes to petabytes of data.
Development of TDSQL can be traced back to 2004, when the internet-based value-added services of Tencent started to burst, which brought huge scaling pressure to the MySQL database. Therefore, the mechanism of database sharding and table splitting was introduced to solve a challenging problem: a huge table is pre-split into multiple subtables by ShardKey, which are spread across different physical server nodes. Nowadays, the volume of data stored on the TDSQL backend is very huge. Taking "Midas" as an example, TDSQL sustains 10 billion accounts in all channels of Midas, where the number of users is close to 900 million, and daily transaction amount exceeds 140 million USD.
TDSQL has the following advantages to easily sustain massive amounts of business requests:
Automatic table splitting: TDSQL supports automatic database sharding and table splitting and implements on-demand capacity scaling together with a unified data scheduling mechanism. As TDSQL blocks internal details of database sharding and table splitting by using a gateway, you do not need to worry about how to shard data and route request waits. You only need to initialize the sharding field (shardkey), develop programs directly for logical tables, and focus on implementation of business logics, which greatly reduces the program complexity.
Automatic failover: For IoT, big data, or payment services, any business with massive amounts of data requires high availability of backend storage databases. As a common solution, failover needs inspection and cooperation of the business and is deeply coupled with the business, which results in a complex switch process that even may require human intervention. After the business is restored, faulty data that may appear during failover has to be repaired manually, which requires much Ops labor. In contrast, TDSQL data nodes and gateways implement multi-point disaster recovery and automatically check the running status of instances. As soon as the primary node fails, primary/secondary failover will be triggered to ensure high database availability in disastrous situations such as primary failure, network failure, and IDC failure. This failover process is totally imperceptible to the business and does not need human intervention, greatly simplifying Ops while ensuring a smooth user experience.
High data consistency: This feature is very helpful if you have zero tolerance for data loss or disorder. TDSQL adopts an innovative multi-thread strong sync replication mechanism based on the original async and semi-sync replication of MySQL, which ensures that there are at least two replicas in a cluster for every and each transaction before a response is returned to user. Then, it uses a series of failover mechanisms to make sure that data will not get lost or disorganized upon failover in case of node failure.
Cluster-based management and auto scaling: The peak number of business requests will surge by several or dozens of times because of launch of new features or promotion campaigns. In the past, you needed to know the business trends and have the DBA manually scale out the database in advance. Generally, the scaling process of most distributed databases is complex and prone to errors as it requires a lot of manual operations. In contrast, TDSQL features automatic deployment, auto scaling, automatic backup and restoration, scheduled data rollback, and multi-dimensional monitoring at the cluster level. When scaling is required, the DBA only needs to click some buttons to initiate the scaling process on the frontend for auto scaling. The cluster-based operation system of TDSQL greatly improves the DBA work efficiency and reduces mistakes caused by manual operations.
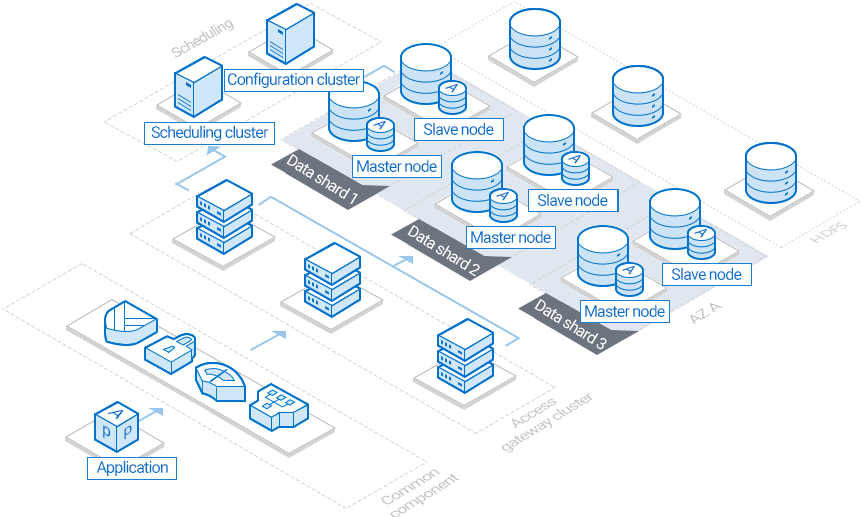
TDSQL architecture
The architecture of a TDSQL instance is as follows:
Data shard: Compatible with open-source MySQL engine and supports the monitoring feature and data collector (Tagent).
Note:
In TDSQL, each shard is configured with two nodes by default, i.e., one primary and one secondary, and each TDSQL instance has at least two shards.
Scheduling cluster: This acts as the cluster management scheduling center and is mainly used to manage the normal operations of SET and record and distribute global database configurations.
Access gateway cluster (TProxy): This manages SQL parsing and assigns routes at the network layer, which can be seen as middleware in an open-source distributed database.
Note:
In order to prevent the proxies from becoming a bottleneck, the number of proxies generally should equal to the number of shards.
Backup cluster: This is a backup cluster of TencentDB data.