ANR
ダウンロード
フォーカスモード
フォントサイズ
RUM Pro provides comprehensive ANR analysis capabilities, supporting the collection and reporting of ANR exceptions on both Android and iOS platforms to help users better optimize application quality. This article details the ANR analysis capabilities and features of RUM Pro.
Android
ANR Overview
Android ANR reporting content is similar to crash monitoring. You can refer to the crash overview to view and analyze the data.
ANR Issue List
The content reported for Android ANR is similar to crash monitoring. You can refer to the crash issues list to view and analyze the reported issues.
ANR Issue Details
Case Details
In the ANR case details, the content of Error Details, error stack, on-site data, log, FD info, Symbol Table, and attachment is similar to crash monitoring. You can refer to crash case details to view and analyze the data.
GC details
To view the GC execution time and Java memory allocation information before ANR occurrences.
Garbage Collection (GC): A mechanism in Android virtual machines (such as Dalvik and ART) that automatically reclaims memory occupied by unused objects. When objects are no longer referenced, GC marks and frees their occupied memory to prevent memory leaks.
Block GC: Block Garbage Collection, a phenomenon where application threads are paused (Stop-The-World) during GC execution, causing stuttering in the main thread (UI thread). This is a key issue in Android performance optimization.
heapAllocated: indicates the currently allocated heap memory size of the process, in KB, corresponding to the calculation result of Runtime.totalMemory() - Runtime.freeMemory().
heapMaxMemory: indicates the maximum heap memory size that the current process can allocate, in KB, corresponding to the return value of the Runtime.getMaxMemory() interface.
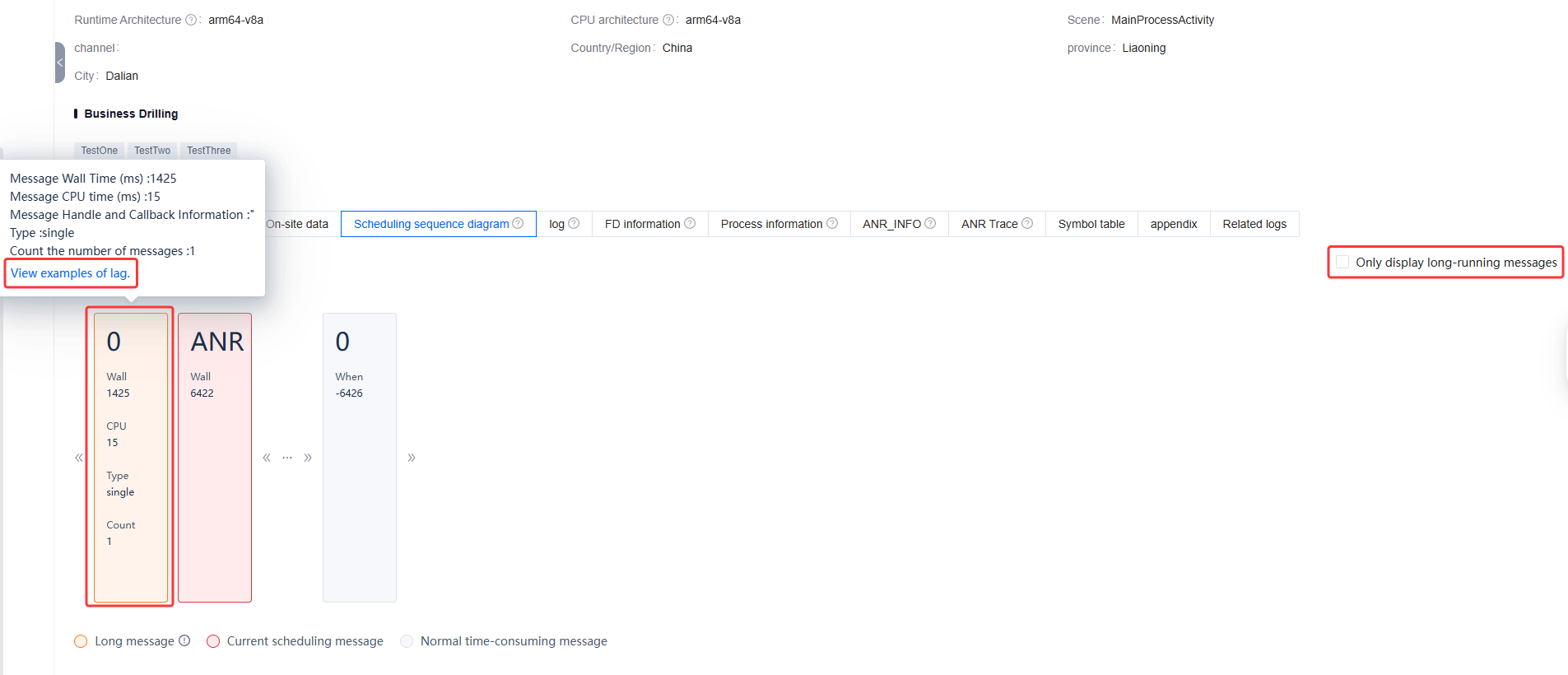
Scheduling sequence diagram
The scheduling sequence diagram displays the message scheduling during ANR occurrences in a sequence diagram format. Click the arrow next to a message to expand details of message scheduling around the ANR occurrence.
Long-duration messages are displayed in yellow cards. Hovering over a message card reveals information such as Wall Time, CPU Time, Message Handler, and Callback for the corresponding message.
Note:
Wall Time: Actual duration, referring to the actual physical time elapsed from the start to the completion of a message's execution (including all time spent on thread blocking, I/O waiting, CPU scheduling delays, etc.).
CPU Time: CPU execution time, referring to the actual time the thread occupies the CPU for computation during message execution (excluding waiting time).
Message Handler: A message processor responsible for dispatching messages to the Looper's message queue and calling the corresponding handling logic upon message execution.
Callback: A callback API, which is executable logic attached to a Message, and can be an implementation of either Runnable or the Handler.Callback interface.
When analyzing ANR issues, you can select Only display long-running messages in the upper-right corner of the module to filter long-duration messages. To view detailed stack traces within long-duration messages, click View examples of lag in the specified message card. This will redirect you to the stutter page to view individual stutter reports for the device. Analyze the stack traces in these reports to comprehensively determine the causes of ANR.
Process Information
Process information includes Maps information, Maps Classification, Meminfo infomation, Process state, Thread state, and Thread statistics.
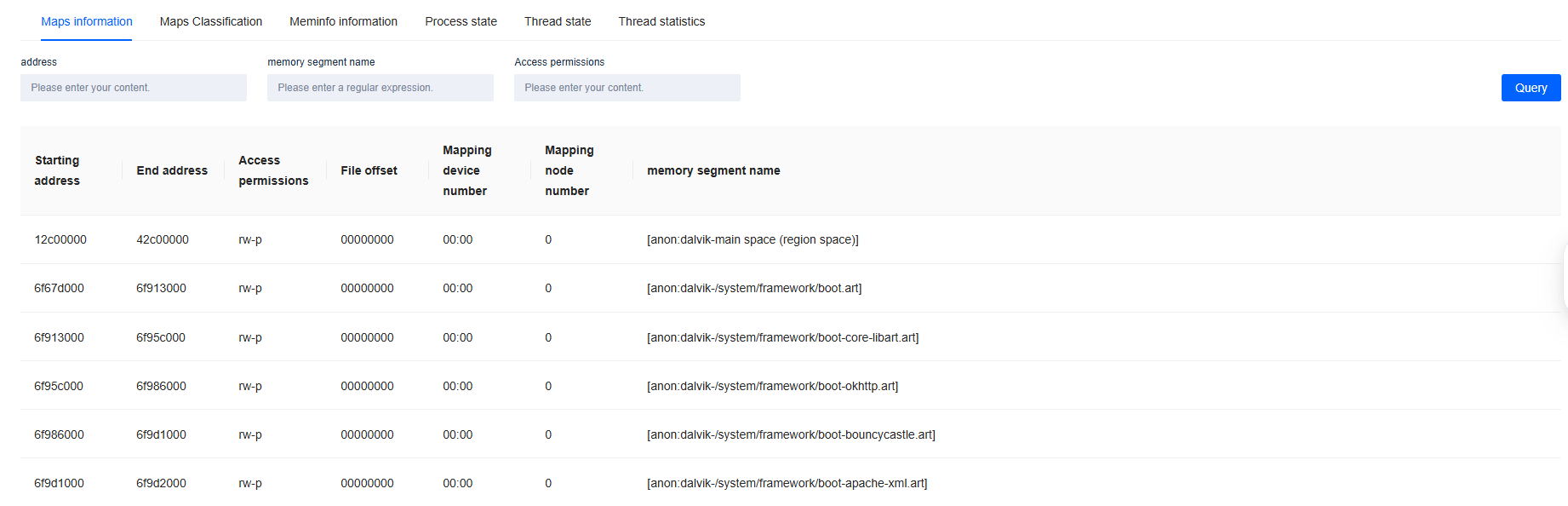
Maps information: Extracted from /proc/[pid]/maps, commonly referred to as Maps information, it records memory mapping details for a specified process. This data reveals the process's virtual memory layout, including loaded libraries, stacks, shared memory regions, and more.
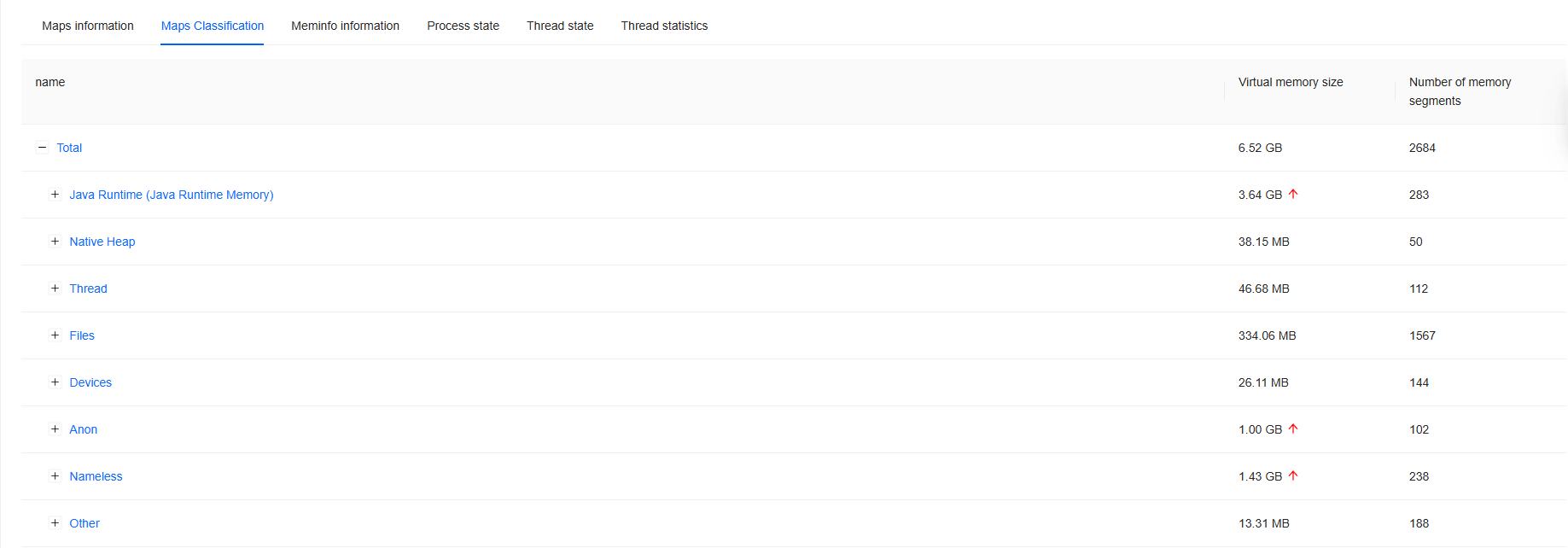
Maps Classification: The classification of Maps information, grouping Maps data of the same type through a tree structure.
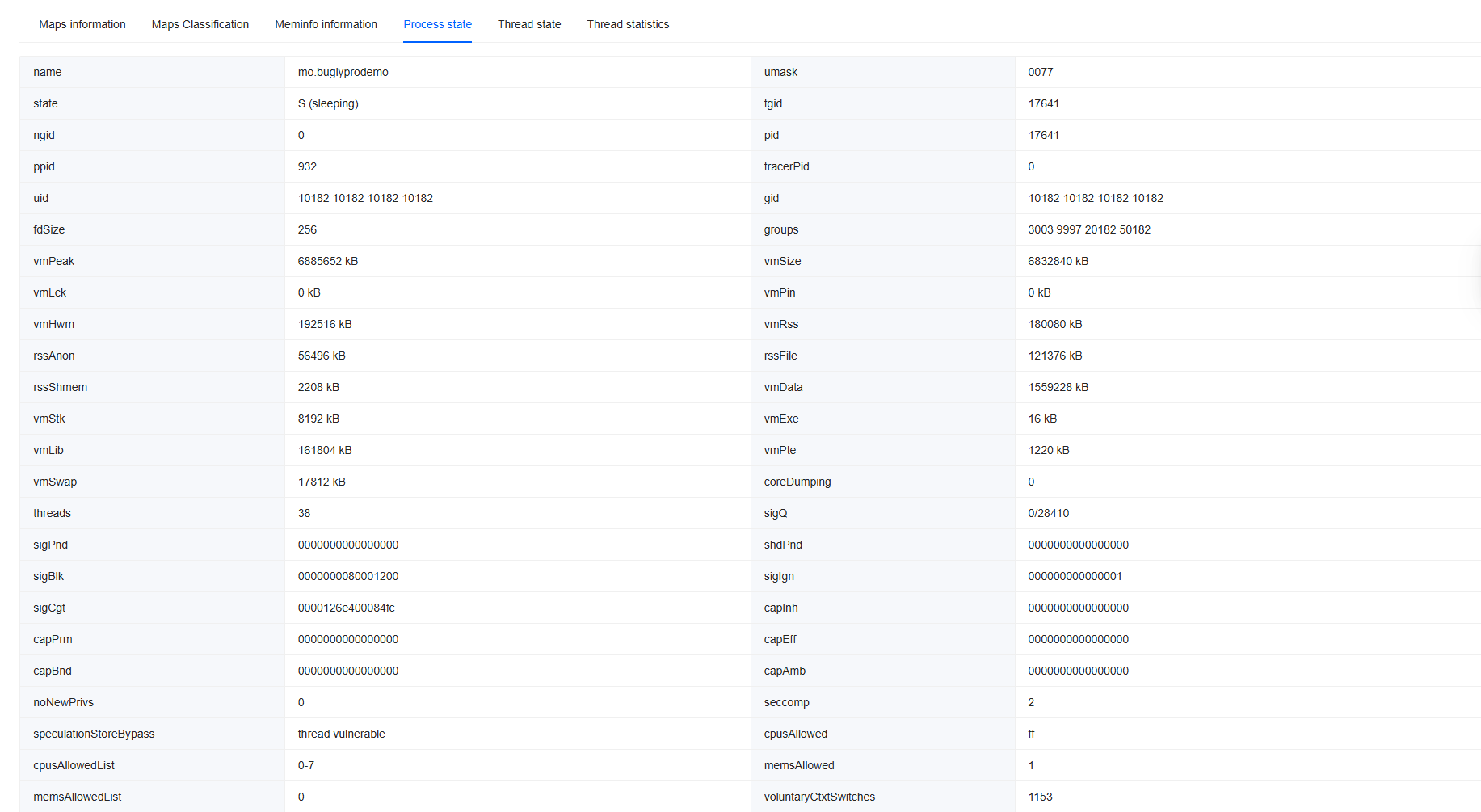
Process state: Extracted from the /proc/[pid]/status file. For details, refer to the Linux kernel official documentation.
Thread state: Extracted from the /proc/[pid]/task/[tid]/stat file, which records runtime statistical information of threads.
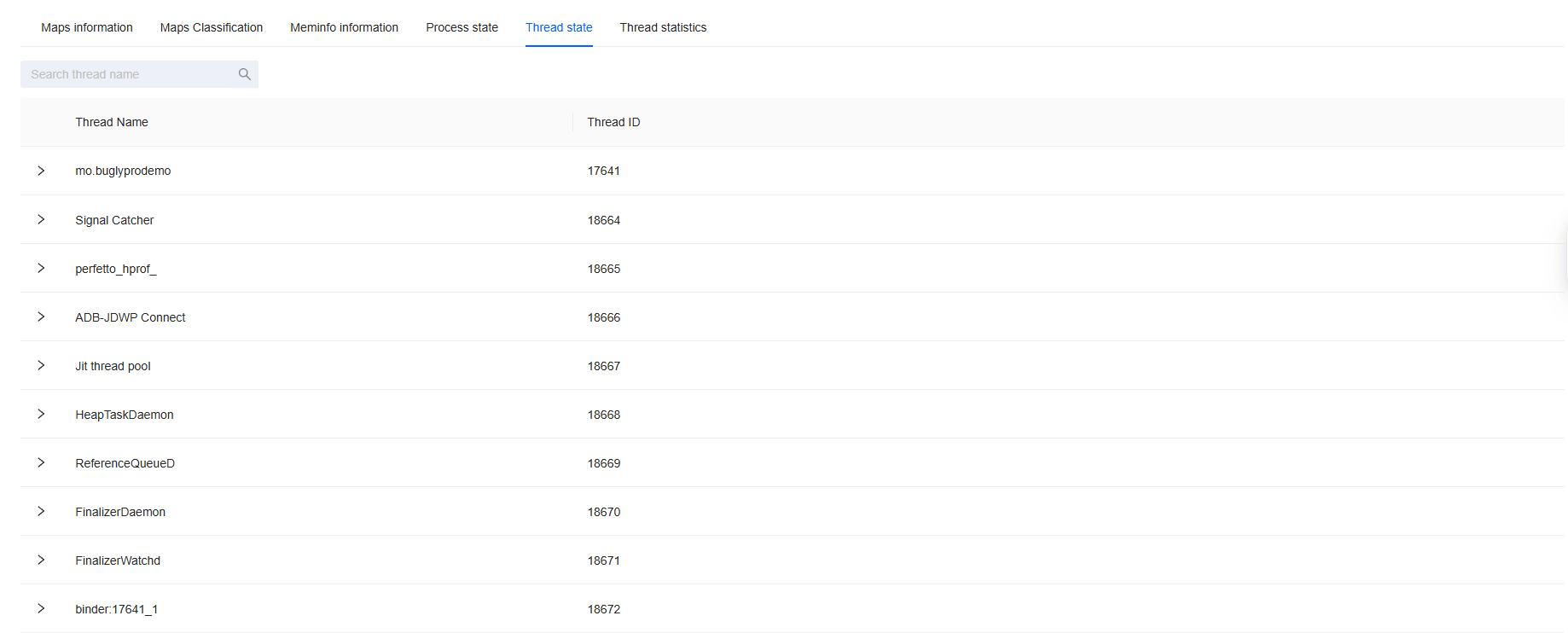
Thread statistics: Categorized statistics of threads by thread name, presented in a tree structure.
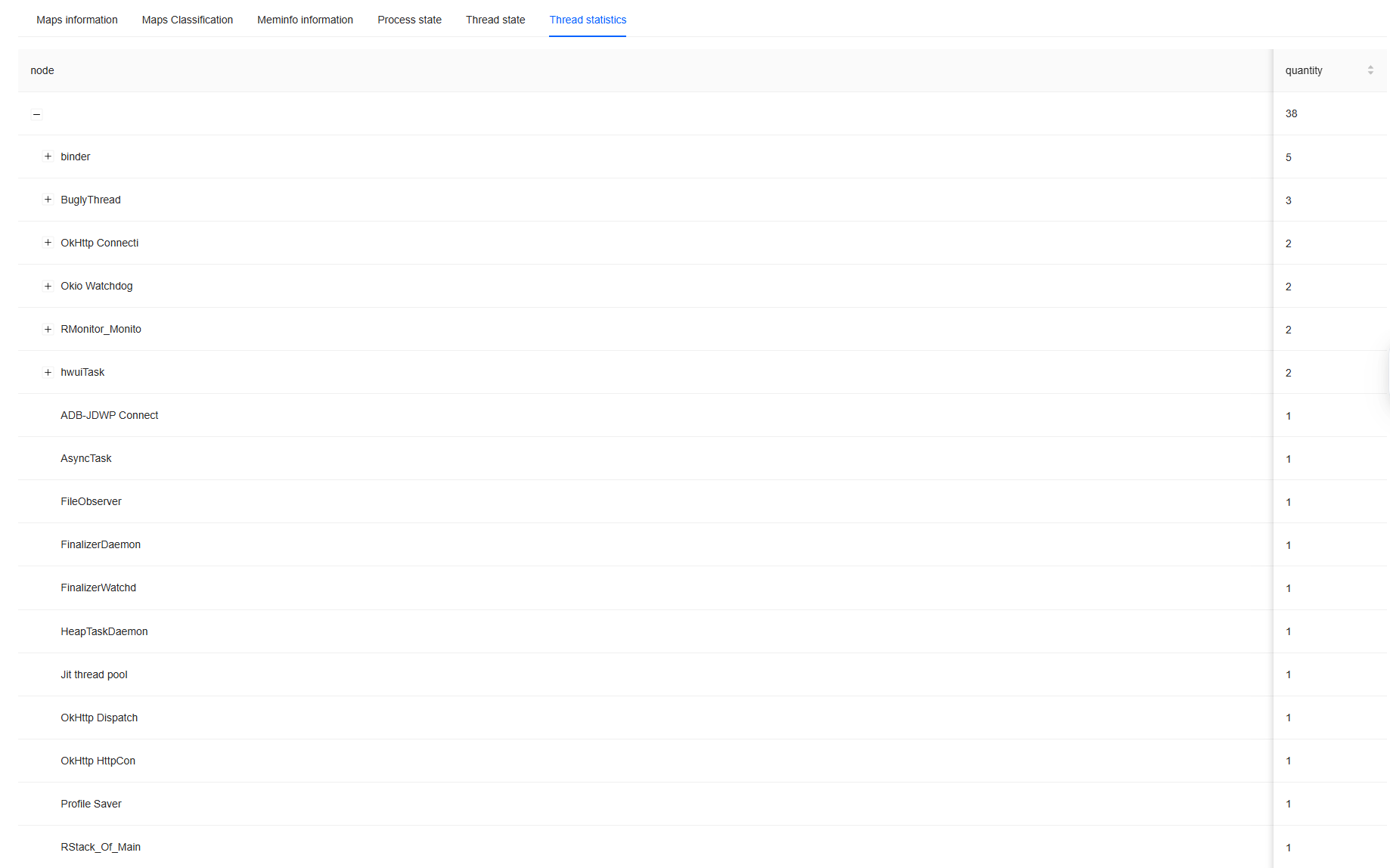
ANR_INFO
ANR_INFO is a system report generated by the application when an ANR occurs, recording the Activity component where the ANR happened, the Process ID of the affected process, and the cause of the ANR.
Load represents the system's average load over 1, 5, and 15 minutes when an ANR occurs. The unit of average load is the number of processes, indicating the average count of processes running or waiting for CPU resources during the ANR. CPU Usage indicates detailed CPU utilization during the ANR timeframe. This information can be used to assist in analyzing ANR issues.
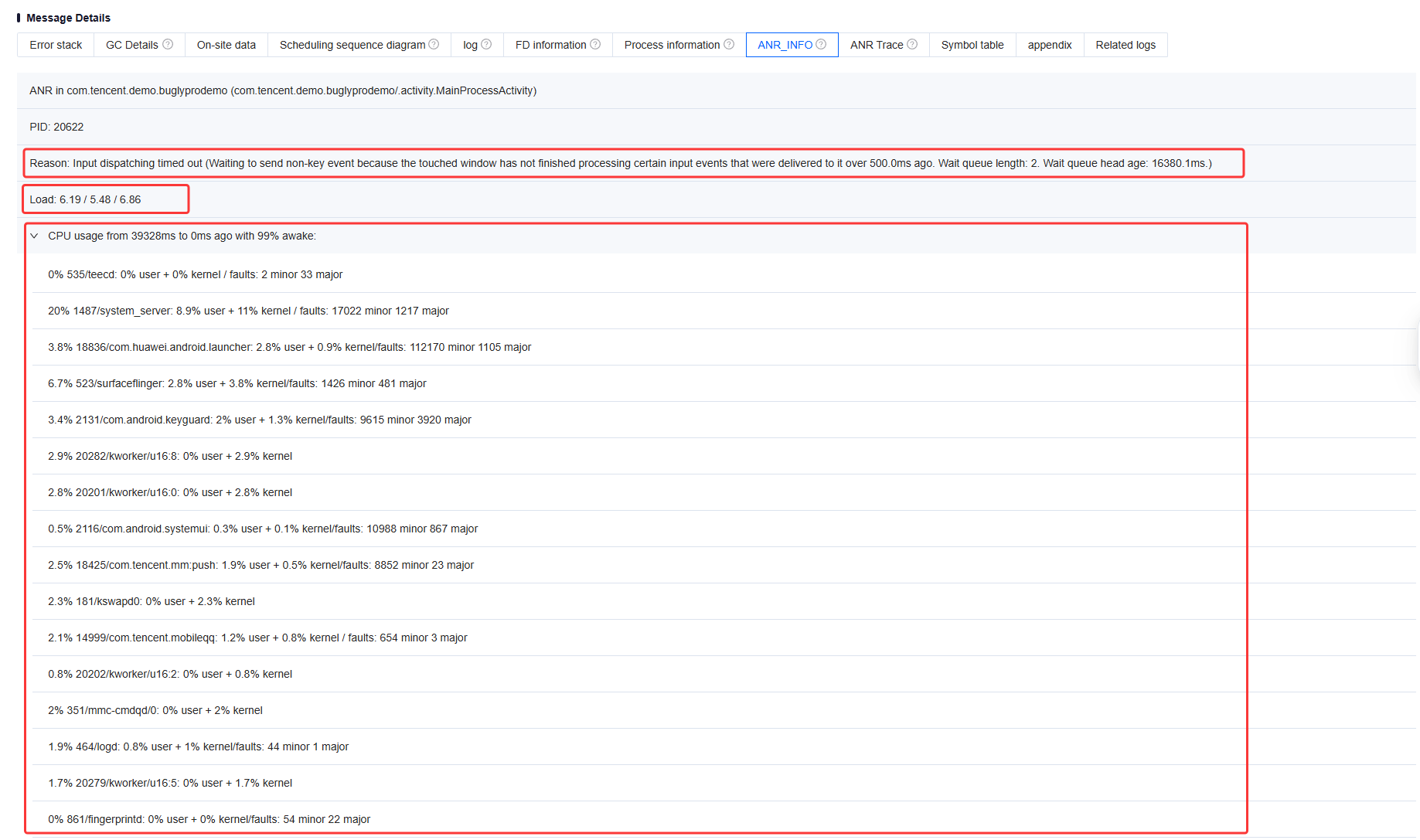
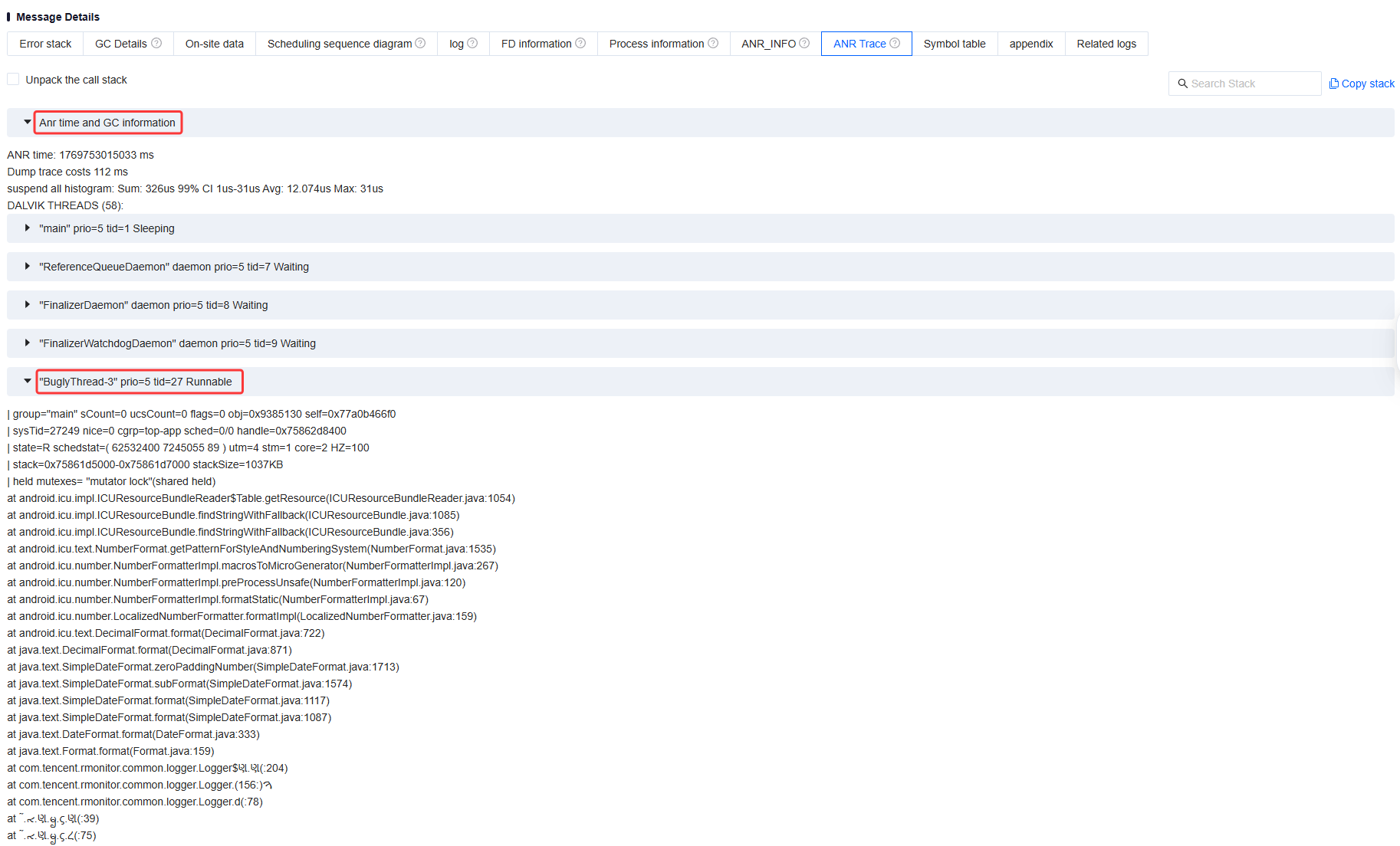
ANR Trace
ANR Trace is a log file that contains events and thread stack traces occurring during ANR in the application, mainly consisting of two parts, as shown in the figure below.
Part 1: ANR Time and GC Information. This section shows the duration of the current ANR issue and the GC operations performed by the system. Part 2: Thread Stack Information. This section lists stack trace information for all threads running during the ANR. In addition to stack details, each thread entry includes status information such as Thread ID (tid), Thread Priority (prio), Thread State (state), Thread Scheduling Statistics (schedstat), and CPU time used by the thread (utm and stm). Combining this information, especially the thread stack traces, can quickly help pinpoint and analyze the root causes of ANR issues.
Drill-down analysis
Android ANR reporting content is similar to crash monitoring. You can refer to the crash drill-down analysis to view and analyze the data.
Associate ANR with Stutter List
Associated freeze: A freeze occurring within 60 seconds before an ANR is defined as an ANR-associated freeze.
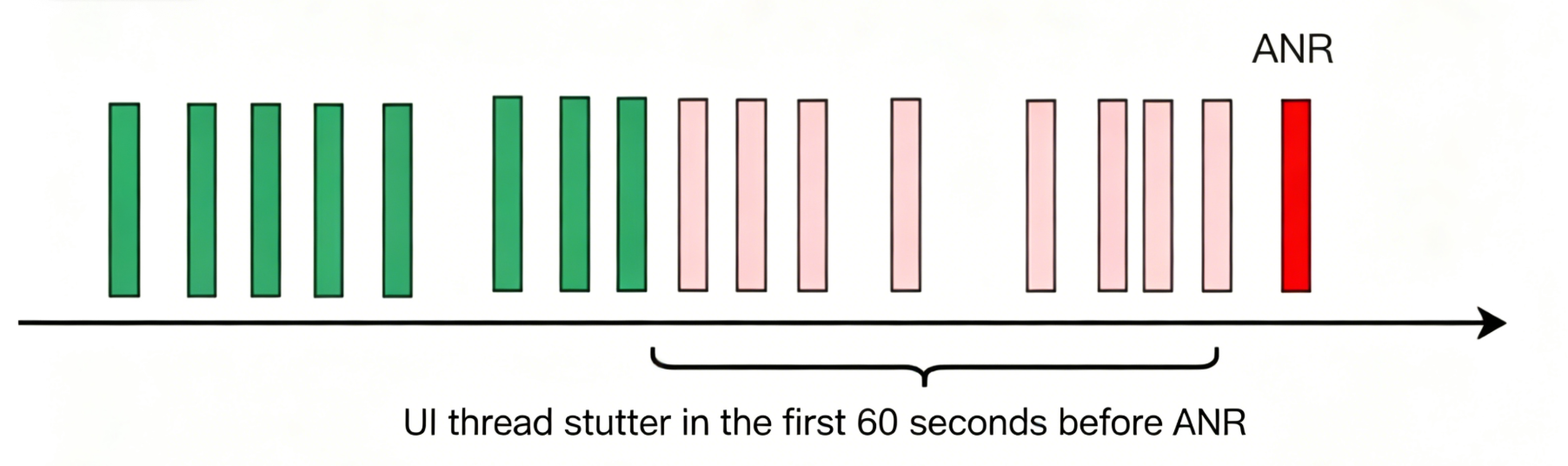
Querying
In the associated freeze list of ANR, RUM Pro supports comprehensive individual case query capabilities, primarily as follows:
Supports drill-down search through multi-dimensional fields such as time range, App version, user ID, device ID, foreground/background state, and Issue ID.
Supports search for custom issue types such as processing status, assignee, Tag, and tag colors.
Supports search for business-reported Custom Fields.
Issue List
The reported content of the Android ANR associated lag list is similar to crash monitoring. You can refer to the Crash Problem List to view and analyze reported issues.
iOS
ANR (Deadlock)
ANR (Application Not Responding) is a term in the Android system that describes a situation where an application fails to respond to user input for a period of time. In the iOS system, it manifests as a SIGKILL with error code 0x8badf00d. On the platform, since it represents the same abnormal behavior, it is collectively referred to as ANR here, facilitating unified understanding across the platform and among developers.
ANR Metric Analysis
The essence of ANR issues lies in the main thread freeze, causing the App to time out in responding to user input. This triggers the system's WatchDog mechanism, thereby terminating the process. The SDK determines whether the main thread has frozen by monitoring the execution cycle of the main thread's Runloop. For freezes exceeding the threshold (default: 5 seconds), it marks them as potential ANR events. Combined with App process exit determination, if the process remains in a potential ANR event state upon its last exit, the previous process termination is concluded to be an ANR.
Based on the above, the platform classifies exit scenarios during prolonged freeze states when a process is terminated by SIGKILL while the App is running in the foreground as ANR exceptions.
Note:
Since the SIGKILL signal directly terminates a process without any signal or notification to the process internally, the platform treats exits after excluding known exits (such as user manually stopping the process, other crashes, etc.) as SIGKILL, which, to some extent, is similar to the FOOM determination method.
To facilitate measuring the severity of ANR events, the platform provides the ratio of ANR rate (ANR exit count to process launch count). Additionally, metrics measured from device and user perspectives are introduced, namely device ANR rate and user ANR rate, both of which are calculated after deduplication by device ID and user ID.
ANR Rate = Exit Count / Launch Count
Device ANR = Exit count after deduplication by device ID / Launch count after deduplication by device ID
ANR-affected Users = Exit count after deduplication by user ID / Launch count after deduplication by user ID
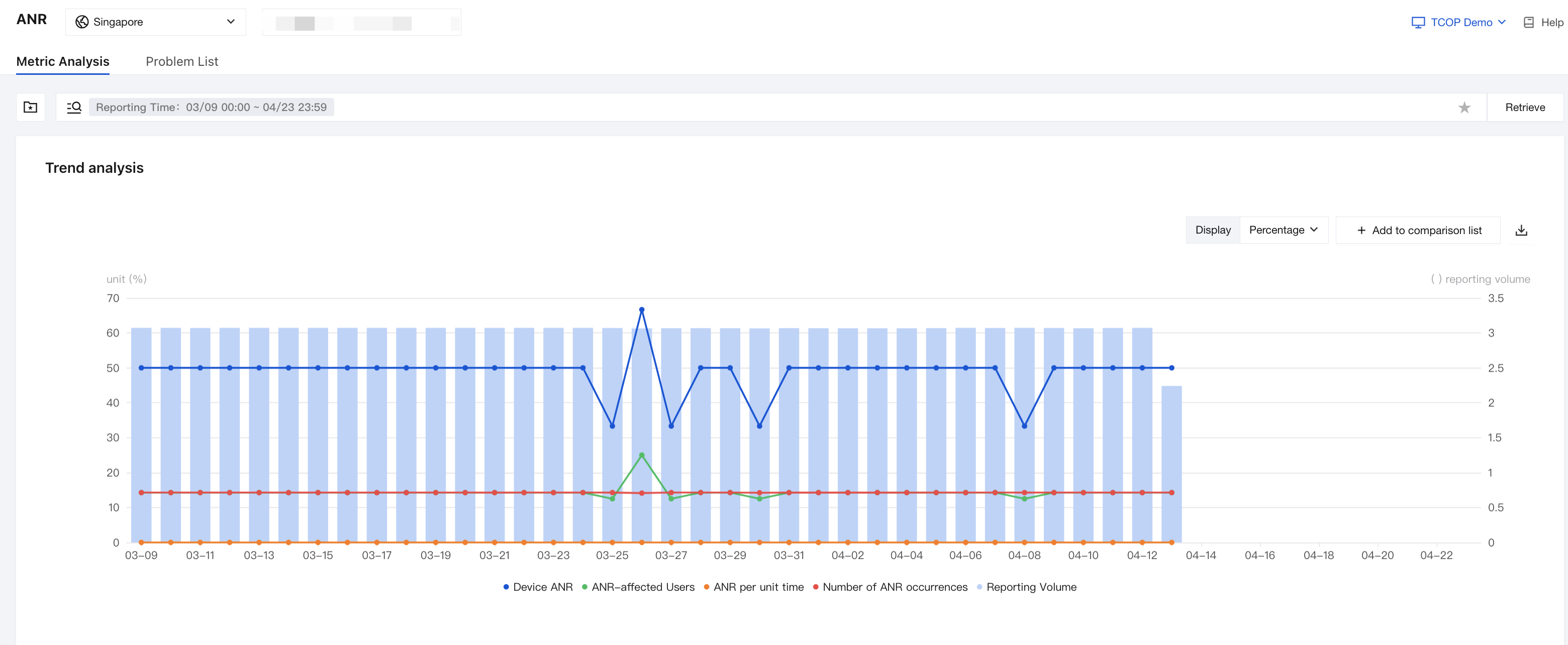
Similar to other metric analyses, it supports filtering and analysis under different conditions to observe metric changes and comparisons.
ANR Problem List
The platform clusters reported ANR cases by the characteristics of the call stacks that caused the exceptions, grouping similar issues into a single issue for statistical tracking. This facilitates business teams in following up and locating problems. For each issue, the problem list displays metrics such as the number of affected devices and the most recent reporting time, consistent with the presentation of other issue lists.
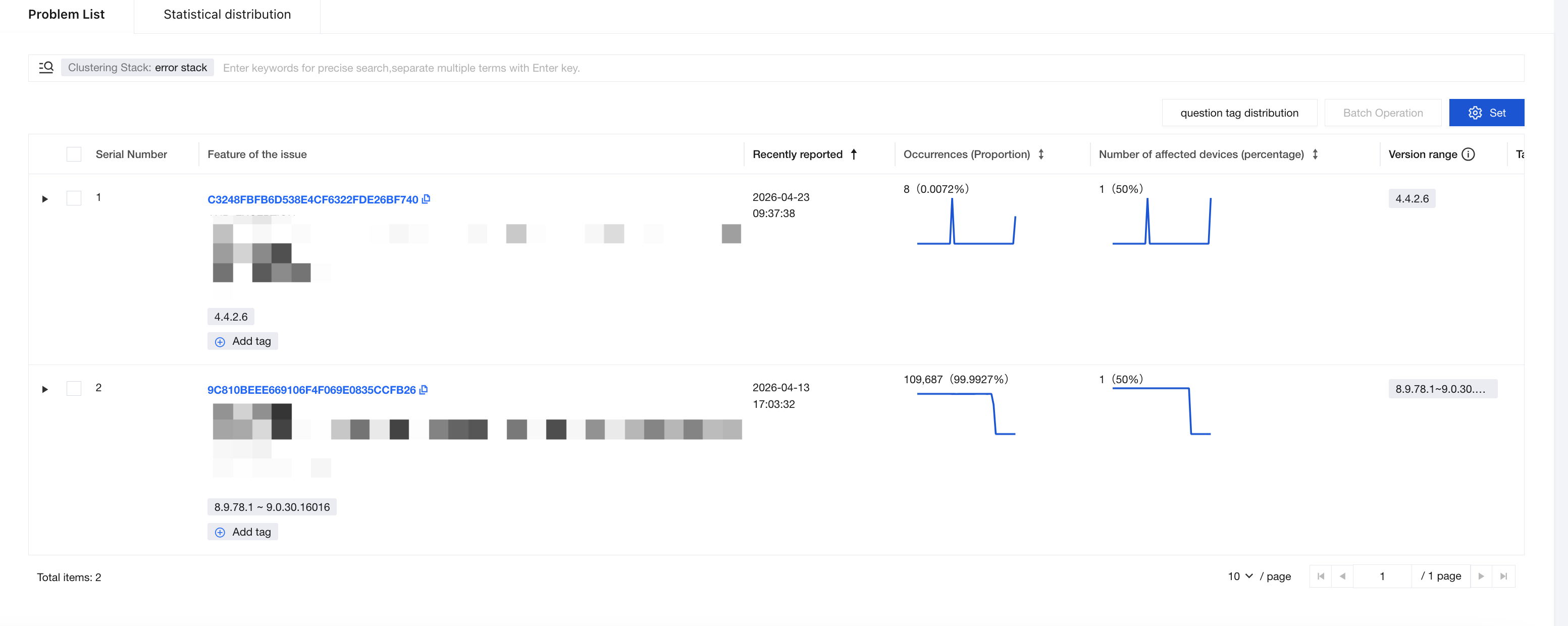
Call stack feature extraction
As mentioned earlier, the SDK reports the call stacks causing ANRs to the backend. To effectively cluster individual issues, the platform uses critical time-consuming methods and takes the top three functions in these critical time-consuming methods as their signature.
Since the call stack captures execution states over a continuous period, adjacent identical frames can be merged from the bottom up, allowing the call stack to be transformed into a call tree where each node represents the time consumption of the corresponding method.
In the stack tree, identify a path with significant time consumption as the critical time-consuming method, then extract the top three levels of this path as its signature for clustering.
Issue list -- No stack issues
In the issue list, there exists a special issue category without a characteristic stack: "Stackless Issues". The occurrence of stackless issues is caused by the platform's sampling mechanism.
For individual cases where stack sampling is not enabled, although they cannot provide corresponding diagnostic stack information, there are scenarios requiring visibility into ANR occurrences for specific users or devices. Therefore, this issue list displays such ANR cases, all grouped under "Stackless Issues".
Note:
When the stack sampling rate is set to 100%, stackless issues may still be reported. This is a known platform issue, more prevalent in earlier versions. The cause is that the SDK experiences a slight delay when persisting the stack. If the process is terminated before stack persistence completes, the stack data is lost. The platform is actively optimizing this mechanism to reduce such occurrences.
ANR Case Analysis
Case analysis serves as a critical basis for resolving ANR issues, providing detailed root causes and effective diagnostic data to pinpoint problems. By selecting an issue from the problem list, users can go to its corresponding case list. Similar to other problem lists and case analyses, it displays basic case information such as occurrence time, reporting time, and user/device IDs, along with relevant filtering criteria. Drill-down analysis is also available, showing trends in case reporting and version distribution for the specific issue.
The message details of individual issues provide information such as the stack trace, full thread dump, operation logs, symbol tables, and scene data. Among these, operation logs, symbol tables, and scene data are consistent with the message details of other issues. For reference, see crash issue details. This section focuses on explaining the stack trace and full thread dump.
error stack
The stack trace refers to the periodically collected main thread call stack mentioned earlier, presented in three visualization formats: time slices, stack tree, and flame graph. These representations are derived from the same dataset but displayed differently for enhanced analysis.
Time slices: The raw data collected is displayed sequentially according to the collection time intervals. Each "TimeSlice: xx~xx" label indicates the call stack details within the corresponding collection interval, which can be viewed by clicking. During collection and reporting, identical call stacks within the same time slice are merged and displayed accordingly. For example, "TimeSlice: 10~20" indicates that the call stack remains consistent throughout the 10-20 time interval, meaning the same logic was continuously executed.
The time intervals shown are relative values, representing the sequence of collections within the final collection window. Since reported stacks are collected within the last 5 seconds before a suspected ANR occurrence, serial numbers follow an "earliest to latest" order. For instance, serial number 1 represents the earliest collected data retained at the time of ANR determination, with subsequent numbers following this sequence.
Stack tree: As a more effective representation, the stack tree aggregates time slice data from the bottom up to form a call tree. Each node represents the execution time of the corresponding method, allowing for intuitive identification of bottleneck methods and their duration.
Flame graph: a graphical representation of the stack tree.
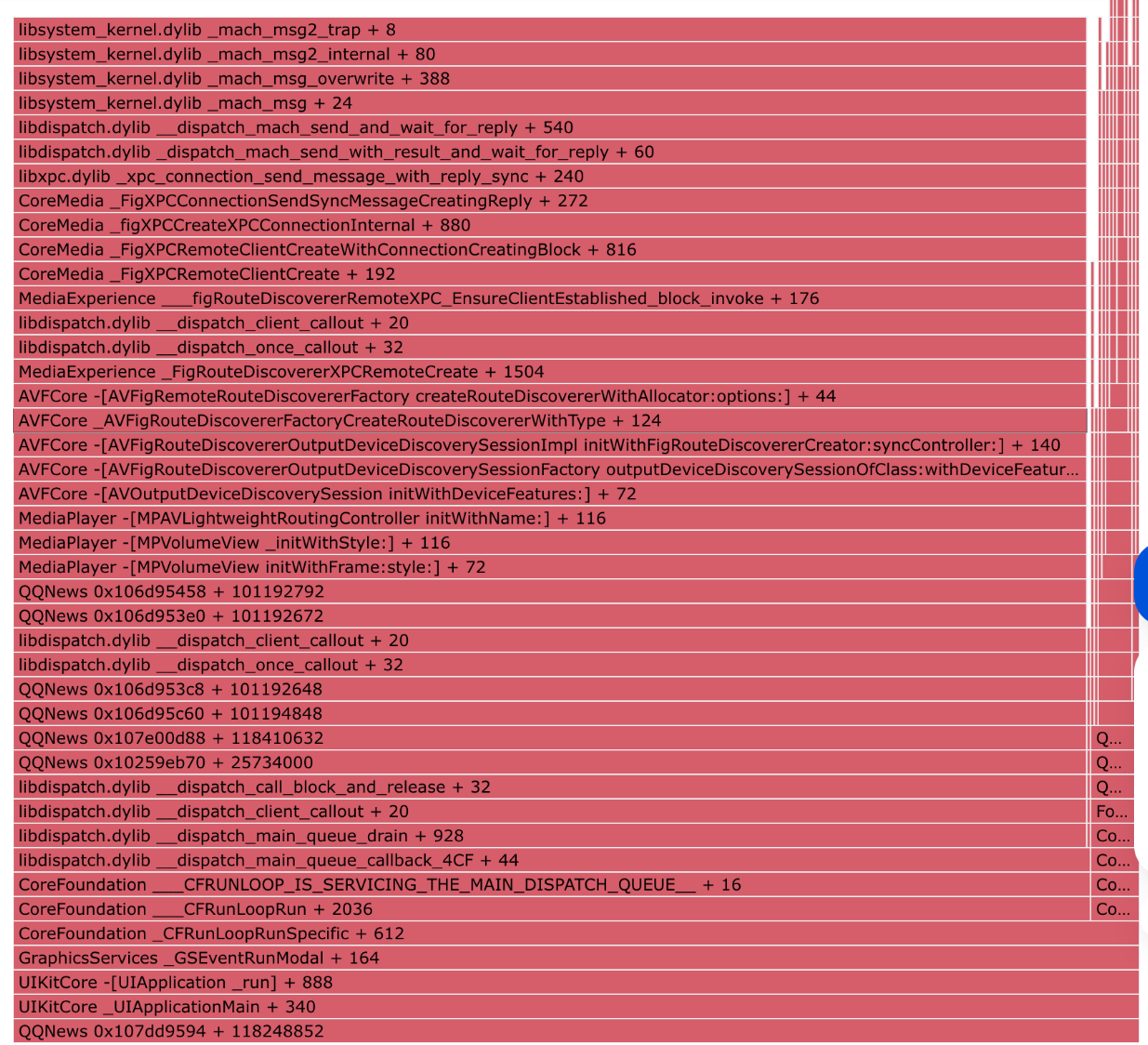
The stack trace directly reveals the timing and methods causing the freeze. For most issues, this typically identifies the method responsible for the abnormal behavior. However, since the stack trace only captures the main thread's state, some ANR issues may stem from the main thread being blocked while waiting for a lock. In such cases, identifying where the lock is held becomes crucial for root cause analysis. This is where the full thread dump comes into play.
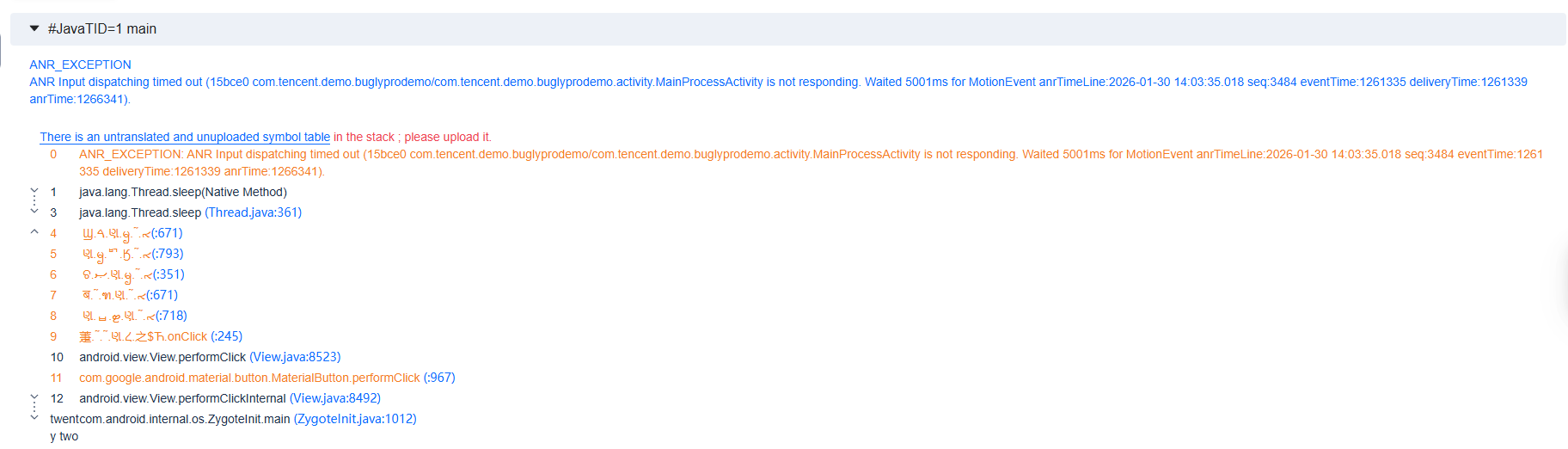
Full thread dump
The full thread dump captures the call stacks of all threads when a suspected ANR is detected, including the main thread itself. Its purpose is to assist developers in identifying lock contention issues.
Generally, if the main thread freezes due to lock contention, developers can trace identical lock usage patterns in the call stack to check whether other threads hold or are waiting for the same lock. This helps determine whether issues like deadlocks or prolonged lock waits have occurred.
フィードバック