In edge scenarios, weak networks can trigger the Kubernetes eviction mechanism, causing unexpected pod eviction behavior. In edge computing scenarios, the network environment between edge nodes and the cloud is highly complex, the network quality cannot be guaranteed, and issues such as API Server and node connection interruptions can occur easily. Using native Kubernetes without modification may lead to frequent node status anomalies, activating the Kubernetes eviction mechanism, resulting in pod eviction, missing endpoints, and eventually causing service interruptions and fluctuations.
To address this issue, TKE-Edge introduces a distributed node status determination mechanism for the first time. This mechanism better identifies eviction timing, ensuring the system runs smoothly under weak network conditions, and avoiding service interruptions and fluctuations.
Pain Points of the Requirements
Native Kubernetes Approach
Weak cloud-edge networks impact communication between the kubelet running on edge nodes and the cloud API Server. If the cloud API Server cannot receive heartbeat signals from the kubelet or renew leases, it cannot accurately obtain the running status of the node and the pods on the node. If this lasts longer than the set threshold, the API Server will consider the node unavailable and take the following actions:
The disconnected node's status is set to NotReady or Unknown, and taints NoSchedule and NoExecute are applied.
Pods on the disconnected node are evicted and rebuilt on other nodes.
Pods on the disconnected node are removed from the Service's Endpoint list.
Solutions
Design Principles
In edge computing scenarios, relying solely on the connection between the edge node and the API Server to determine whether a node is normal is not reasonable. To make the system more robust, it's necessary to introduce additional judgment mechanisms.
Compared to the cloud and edge nodes, the network between edge nodes is more stable. Thus, a more stable infrastructure can be leveraged to improve accuracy. TKE-Edge pioneered the edge health distributed node status determination mechanism. In addition to considering the connection between nodes and the API Server, it introduces edge nodes as evaluation factors to provide a more comprehensive status assessment of the nodes. Extensive tests and practical demonstrations have proven that this mechanism improves the accuracy of node status determination under weak cloud-edge network conditions, ensuring stable operation of services. The main principles of this mechanism are as follows:
Each node periodically probes the health status of other nodes.
All nodes within the cluster regularly vote to determine the status of each node.
Both cloud and edge nodes collectively determine the node's status.
Firstly, nodes internally probe and vote for the specific status of a node, and the unanimous judgment of the majority ensures the accurate status. Secondly, although the network status between nodes is typically better than the cloud-edge network, we should consider the complexity of the edge nodes' network environment, which is not 100% reliable. Therefore, it is not possible to fully trust the network between nodes, and the node status cannot be decided solely by the nodes themselves. A joint decision is more reliable. With this in mind, the following design is proposed:
Status Determination
Cloud Determination Normal
Cloud Determination Abnormal
Intranet Determination Normal
Normal
K8s shows NotReady, but the behavior is different from the standard K8s process: No longer scheduling new Pods to the node, but not evicting Pods and handling services.
Intranet Determination Abnormal
Normal
K8s shows NotReady, with behavior consistent with the standard K8s process: evicting existing Pods; removing them from the Endpoint list; no longer scheduling new Pods to the node.
Prerequisite
This feature requires opening port 51005 on the node so that the nodes can perform distributed smart health detection amongst themselves.
Operation Steps
Caution:
The edge health check and multi-region check features require some deployment and configuration time and will not take effect immediately.
Enable Global Health-Check
The edge health check feature is turned off by default. Please follow the steps below to enable it manually:
2. On the cluster management page, click the cluster ID to enter the cluster details page.
3. Select "Add-on management" and enter the add-on list page.
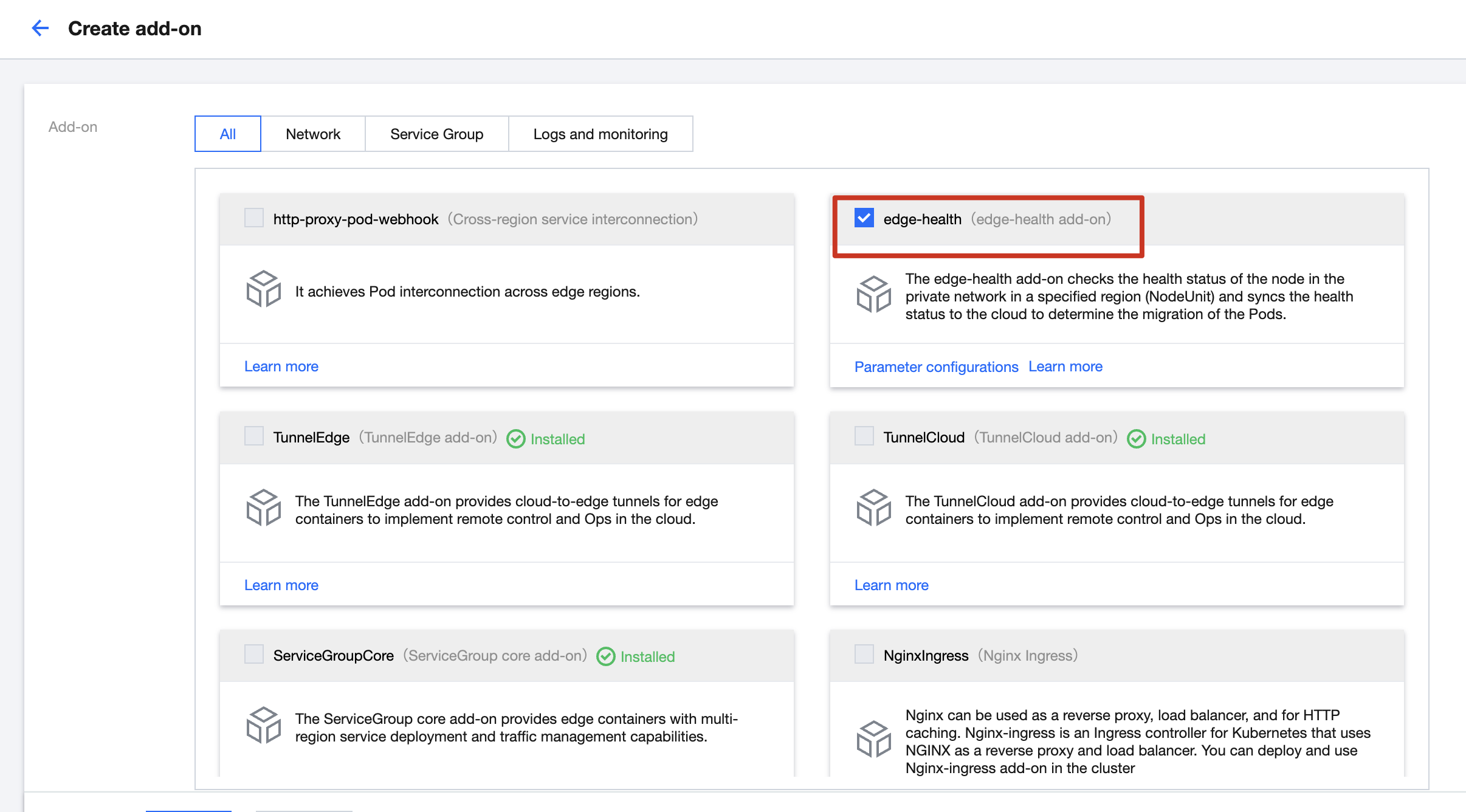
4. Click "Create", enter the "Create add-on" page.
5. Select "edge-health" and click "Done", as follow:
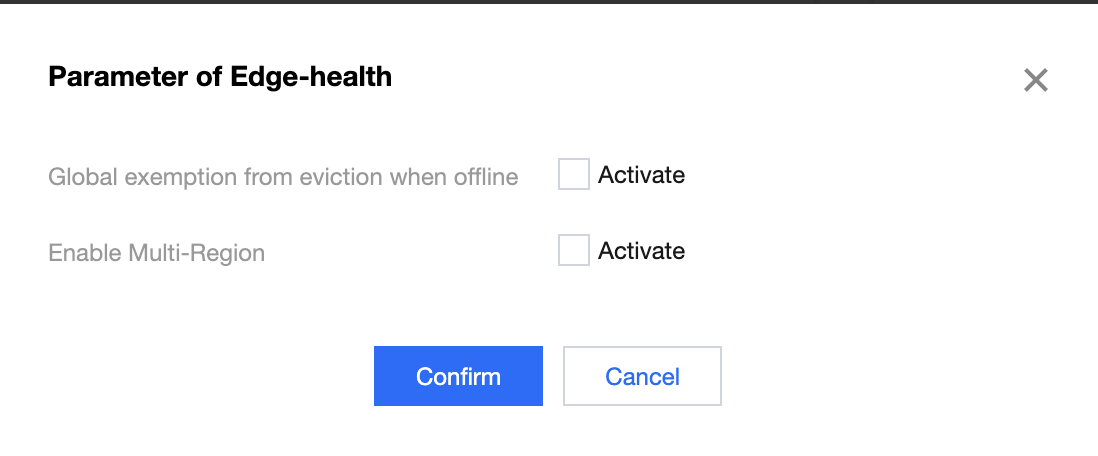
On "Parameter configurations" pages, you can enable "Global exemption from eviction when offline" and "Multi-Region" capabilities, as follow:
6. Click "Done" and "edge-health" add-on will be deployed on the edge cluster.
Global exemption from eviction when offline
After enabling this feature, all eviction flags, specifically the NoExecute taints, will be intercepted through the webhook mechanism. This prevents Pods from being evicted and rescheduled due to frequent node disconnections and reconnections. This feature is mutually exclusive with Multi-Region checks. When the eviction prevention feature is enabled, the actual health status of edge nodes will not be detected.
Multi-Region:
The concept of multi-region here actually refers to NodeUnit in edge-health, which distinguishes the node's regional attributes through NodeUnit. For details, please refer to the NodeUnit. Enabling Edge Health capability deploys edge-health health monitoring Pods on all edge nodes. If the multi-region capability is not enabled at this time, all nodes' statuses will be detected by default, and there is no multi-region concept. All nodes can be considered as nodes within the same region for mutual detection.
If you want nodes within different regions to independently check each other's health status, you need to enable the Multi-Region capability. At this point, you'll modify an edge-health-config ConfigMap, notifying K8s to handle multi-region health check capability. Once enabled, nodes will be separated into different regions based on the <nodeunit-name>: nodeunits.superedge.io label on the node. For example, the label beijing:nodeunits.superedge.io indicates that the node belongs to NodeUnit Beijing. Nodes with the same label are considered part of the same NodeUnit. When enabling the multi-region functionality, nodes within the same region will probe and vote on each other's state.
Note:
If you enable the Multi-Region capability and the node does not belong to any NodeUnit, the node will not perform health checks.
If the Multi-Region capability is not enabled, all nodes within a cluster will check each other, even if the nodes belong to a NodeUnit.
2. On the cluster management page, click the cluster ID to enter the cluster details page.
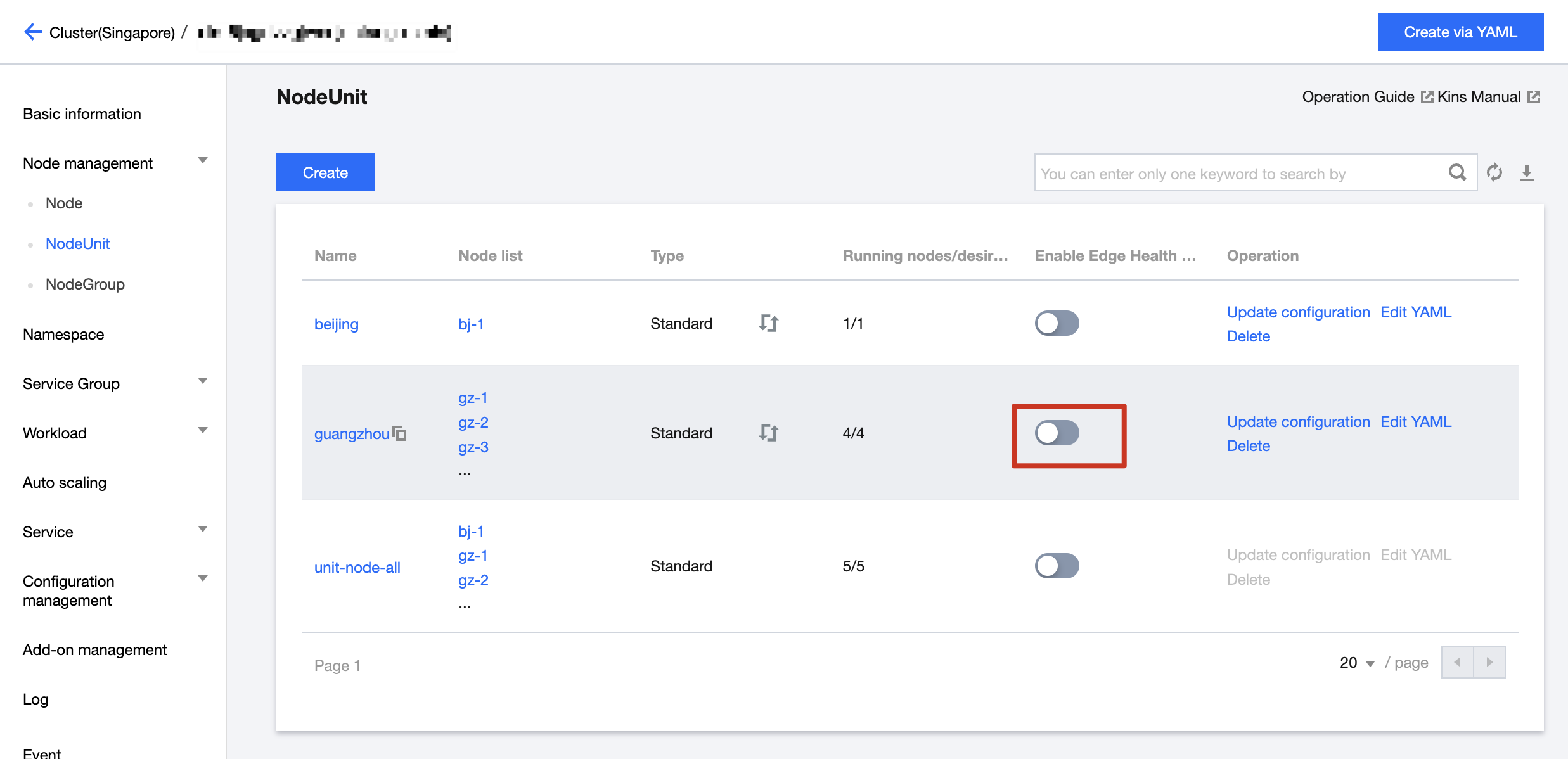
3. Select "Node management" > "NodeUnit", and you'll see there is an additional switch called "Enable Edge Health Check", as follow:
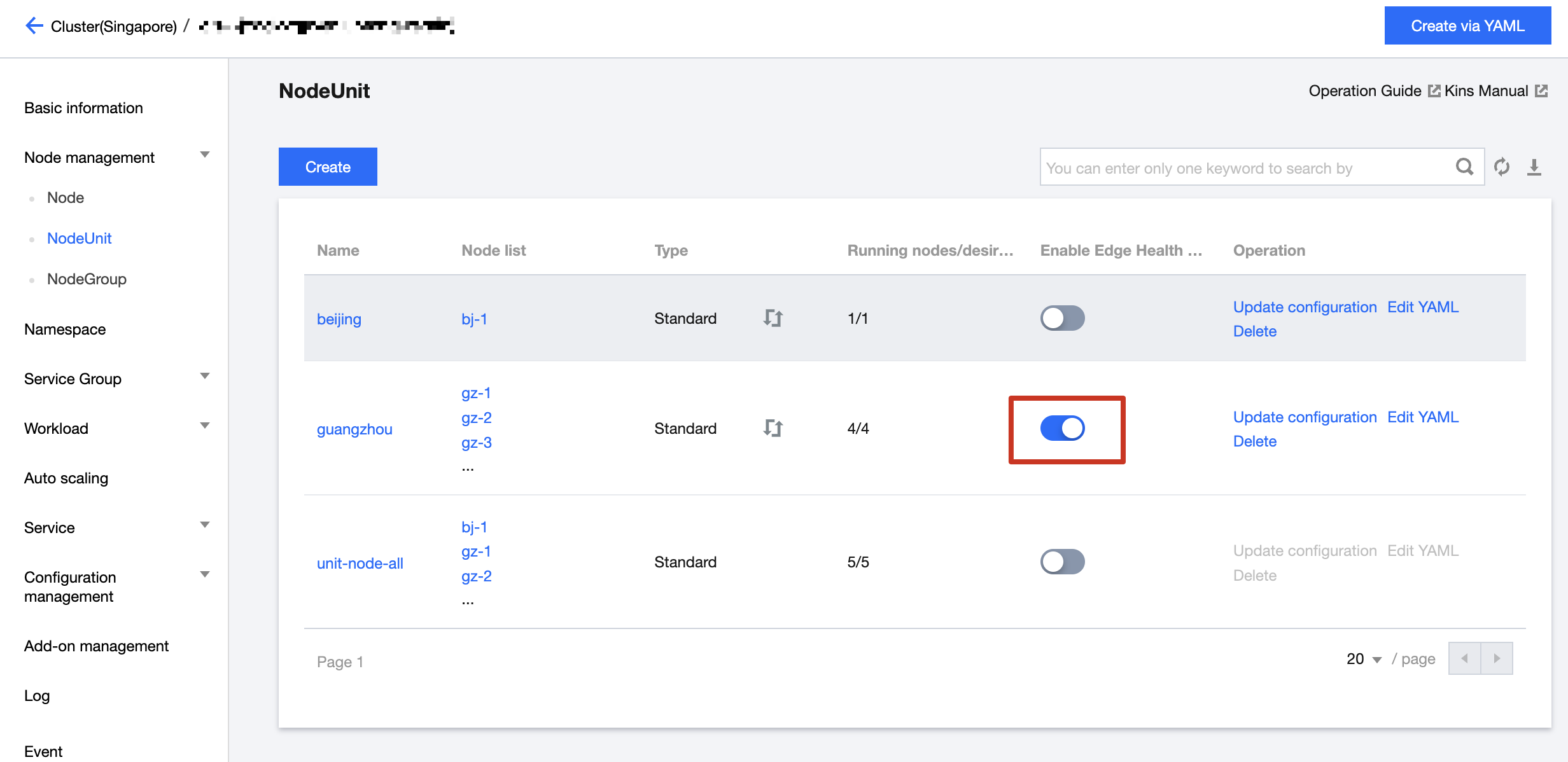
4. You can choose the NodeUnit you want and enable the "Edge Health Check" switch. At that time, you can check on the edge-health of each node that all nodes under the NodeUnit will probe each other.
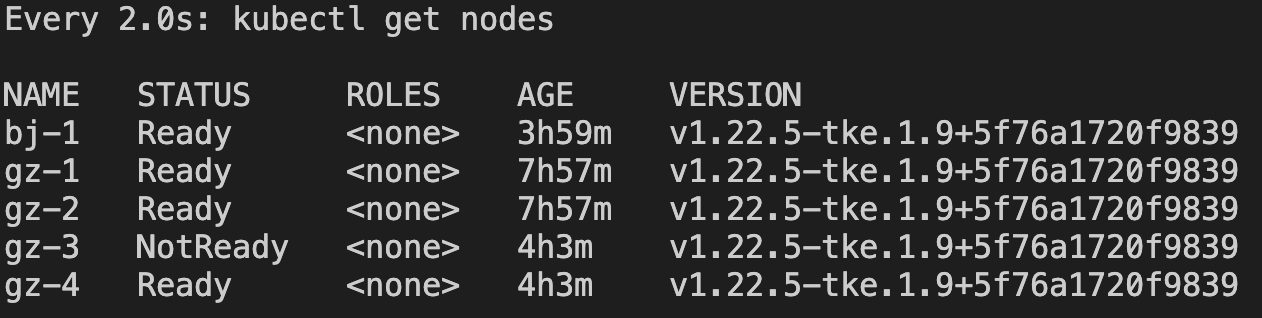
5. At this point, the multi-regional health status capability is enabled. We can simulate the test using the gz-3 node, as follows:
You can use iptables rules to simulate disconnection from the apiserver:
iptables -I INPUT -s xxx.xxx.xxx.xxx -j DROP # This would be the IP address of the apiserver
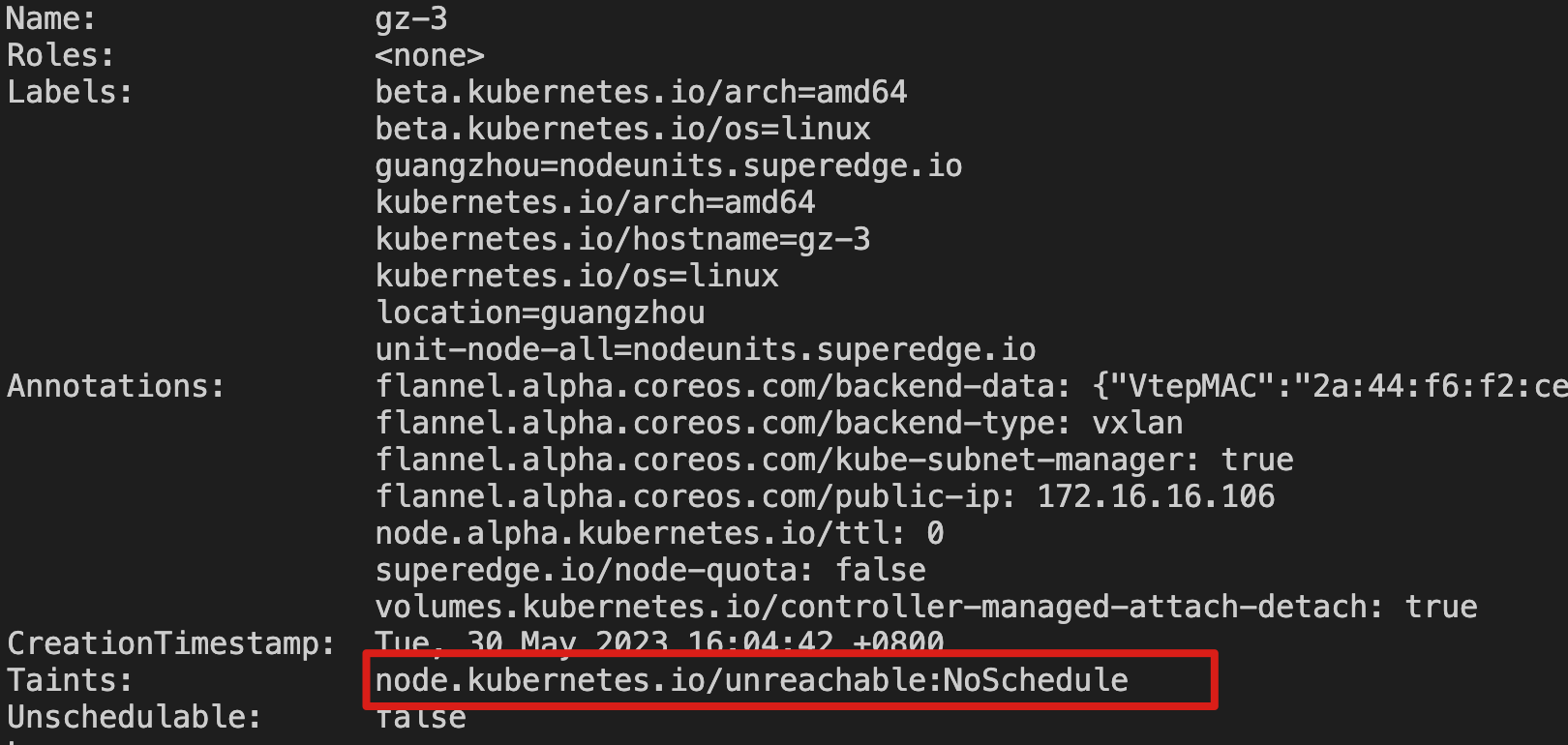
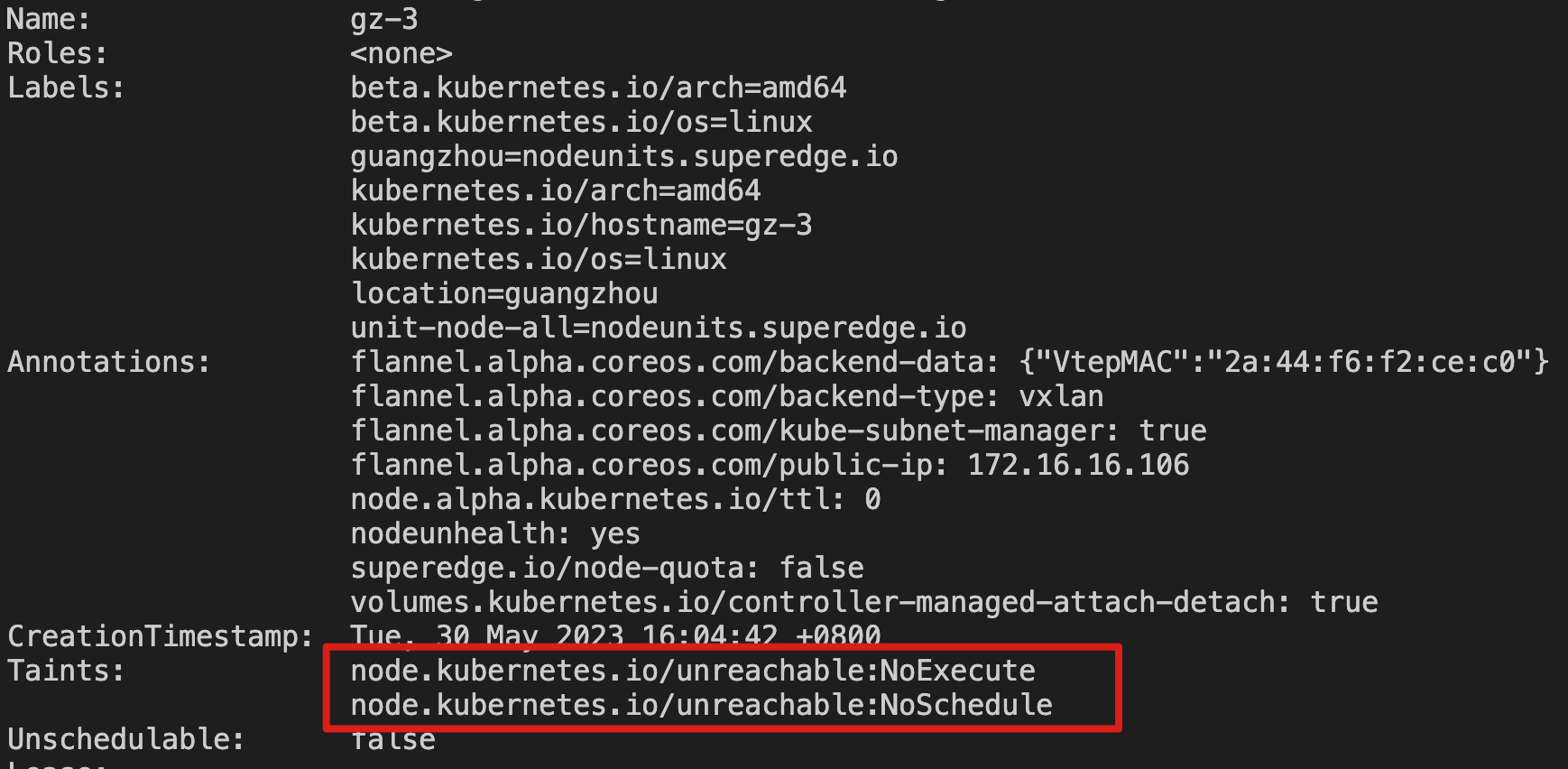
After some time, you can observe that the gz-3 node is in a NotReady state, but the Taint node.kubernetes.io/unreachable:NoExecute is not added. Therefore, the Pods on this node will not be evicted, and no new Pods will be scheduled on this node. This behavior demonstrates the proper handling of node unavailability by the cluster and its impact on workload management.
To simulate a scenario where both cloud and internal network checks fail, shut down the `gz-3` node and observe its status. In this situation, the node state reflects the standard Kubernetes node failure state, and the Pods on this node will be evicted and rescheduled to other available nodes.

 Yes
Yes
 No
No
Was this page helpful?