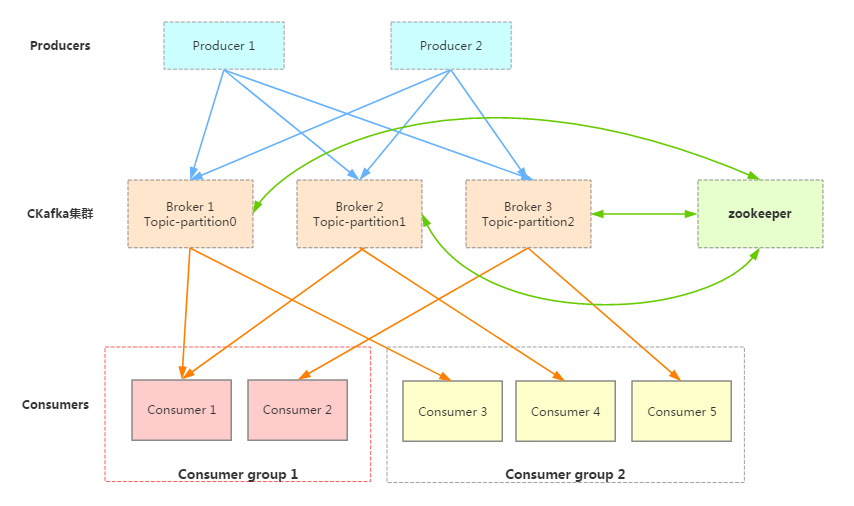
The following figure shows the architecture of TDMQ for CKafka (CKafka):
Producer
Message producers generate messages, such as those from web activities or service logs, and publish them to the CKafka broker cluster in push mode.
CKafka Cluster
Broker: A server that stores messages. Brokers support horizontal scaling, and the more nodes there are, the higher the throughput of the cluster.
Partition: A partition. A topic can have multiple partitions. Each partition physically corresponds to a folder, which is used to store the message and index files of that partition. A partition can have multiple replicas to improve availability, but this also increases storage and network overhead.
ZooKeeper: It is responsible for cluster configuration management, leader election, and fault tolerance.
Consumer
Message consumers. Consumers are divided into several consumer groups and consume messages from brokers in pull mode.
Architecture Principle Description
High Throughput
In CKafka, a large amount of network data is persisted to disks and then transmitted over the network through disk files. The performance of this process directly affects the overall throughput of Kafka and is mainly optimized through the following mechanisms:
Efficient disk utilization: Data is written to and read from disk sequentially, maximizing disk efficiency.
Message writing: Messages are written to the page cache and then flushed to disks by asynchronous threads.
Message reading: Messages are sent directly from the page cache to the socket.
When the requested data is not found in the page cache, disk I/O occurs. The message is loaded from the disk into the page cache and then sent out through the socket.
Broker zero-copy mechanism: The sendfile system call is used to send data directly from the page cache to the network.
Reduce network overhead.
Compress data to reduce network load.
Batch processing mechanism: Producers write data to brokers in batches, and consumers pull data in batches.
Data persistence
Data persistence of CKafka is mainly implemented based on the following principles:
Partition storage distribution in a topic
In the file storage of CKafka, a single topic contains multiple partitions. Each partition physically corresponds to a folder that stores messages and index files for that partition. For example, if you create two topics (Topic 1 with 5 partitions and Topic 2 with 10 partitions), the cluster will generate 15 folders in total (5 for Topic 1 and 10 for Topic 2).
The way for file storage in partitions
Physically, a partition consists of multiple segments of equal size. It supports sequential read and write operations and quickly deletes expired segments to improve disk utilization.
Scale-Out
A topic can include multiple partitions, which can be distributed on one or more brokers.
A consumer can subscribe to one or more partitions.
A producer is responsible for evenly distributing messages to the corresponding partitions.
Messages within a partition are ordered.
Consumer Group
CKafka does not delete consumed messages.
Every consumer must belong to a group.
Multiple consumers in the same consumer group cannot consume the same partition at the same time.
Different groups can consume the same message at the same time, enabling diversified modes (queue mode and publishing and subscription mode).