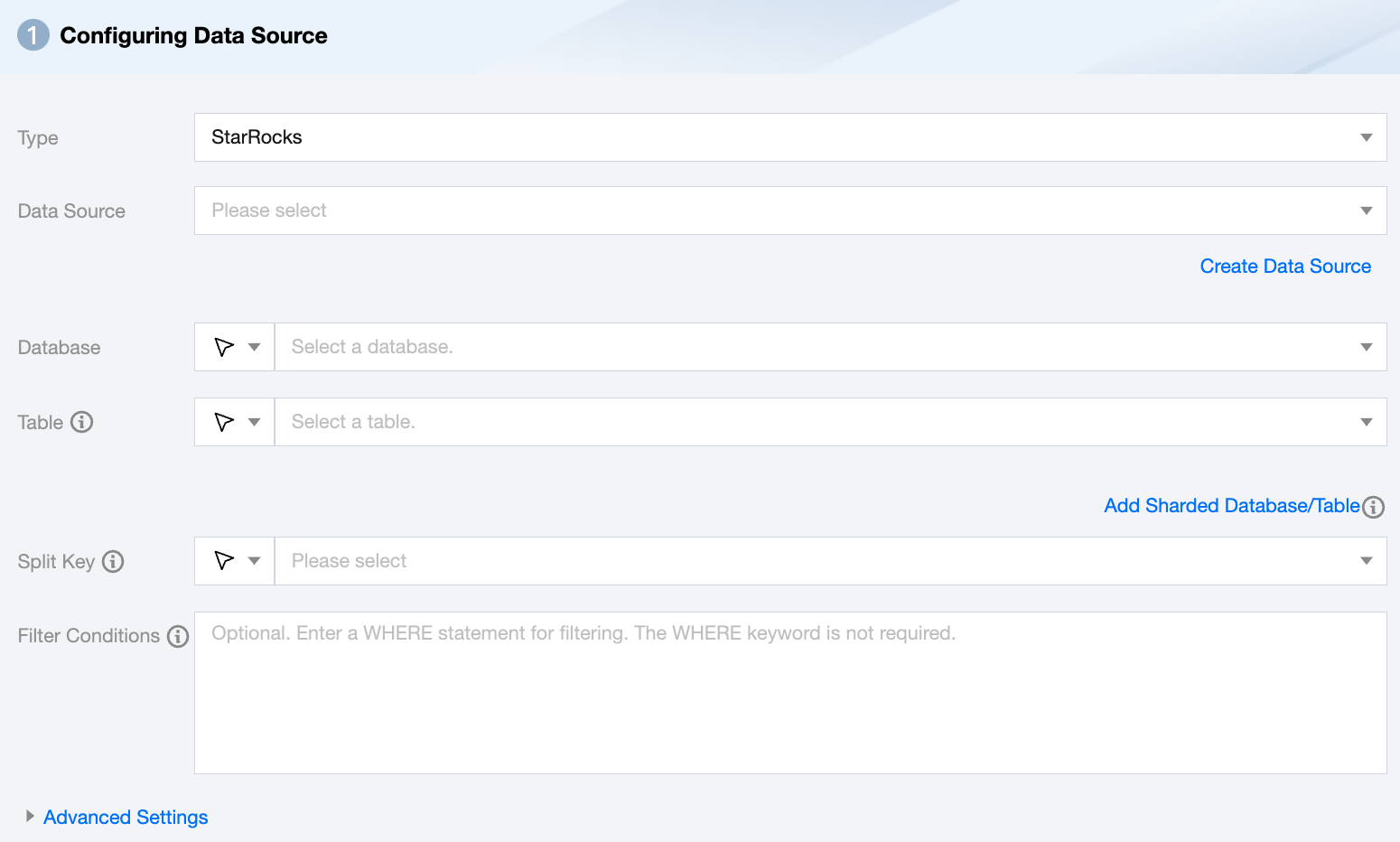
StarRocks Offline Single Table Read Node Configuration
Parameters
Description
Data Source
Select the pre-configured StarRocks data source from the source end
Database
Supports selecting or manually entering the library name to be read. By default, the database bound to the data source is used as the default library. For other databases, you need to manually enter the library name. If the data source network is not connected and the database information cannot be fetched directly, you can manually enter the database name. Data synchronization can still be performed when the Data Integration network is connected.
Table
Supports selecting or manually entering the table name to be read. If the data source network is not connected and the table information cannot be fetched directly, you can manually enter the table name. Data synchronization can still be performed when the Data Integration network is connected.
Split Key
Specify the field for data sharding. After specifying, concurrent tasks will be launched for data synchronization. You can use a column in the source data table as the partition key. It is recommended to use the primary key or indexed column as the partition key.
Filter Conditions (Optional)
Fill in the corresponding filter statement based on the data type. This statement will serve as the filter condition for the data to be synchronized.
Advanced Settings (Optional)
You can configure parameters according to business needs.
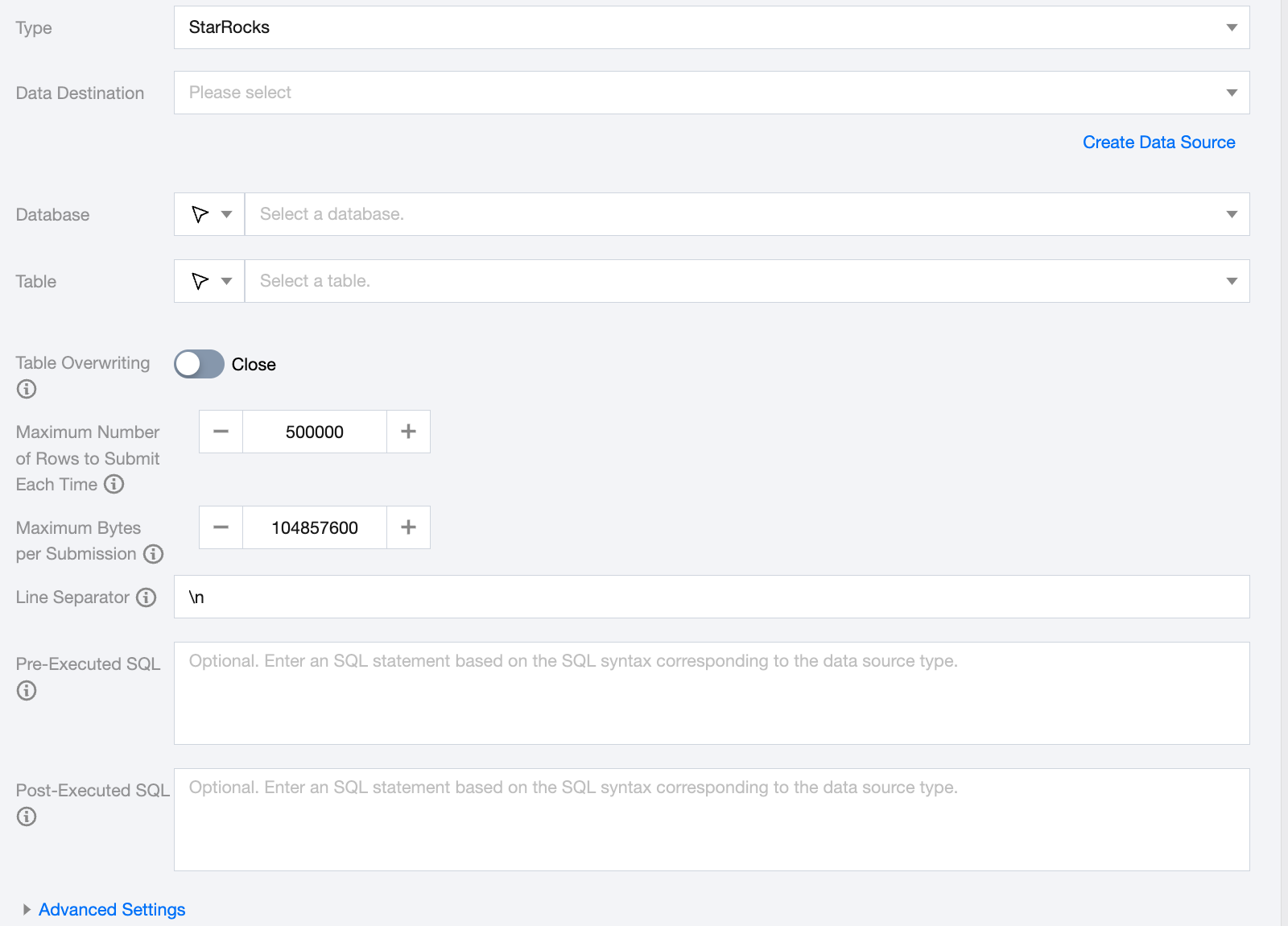
StarRocks Offline Single Table Write Node Configuration
Parameters
Description
Data Destination
Select the pre-configured StarRocks data source from the target end
Database
Supports selecting or manually entering the library name to be read. By default, the database bound to the data source is used as the default library. For other databases, you need to manually enter the library name.
If the data source network is not connected and the database information cannot be fetched directly, you can manually enter the database name. Data synchronization can still be performed when the Data Integration network is connected.
Table
Supports selecting or manually entering the table name to be read. If the data source network is not connected and the table information cannot be fetched directly, you can manually enter the table name. Data synchronization can still be performed when the Data Integration network is connected.
Table Overwriting
Once enabled, SR writes will support atomic overwrite operations at the table level. Before writing the data, a new table with the same structure will be created using the CREATE TABLE LIKE statement. The new data will be imported into the new table, and the old table will be atomically replaced with the new one using a swap method to achieve table overwrite.
Maximum Number of Rows to Submit Each Time
The maximum number of records per StreamLoad import during task execution. The default is 500,000.
Maximum Bytes per Submission
The maximum bytes per StreamLoad import during task execution. The default is 100MB.
Line Separator
The default is \\n.
Pre-Executed SQL
SQL statements executed before the synchronization task. Fill in the SQL according to the correct SQL syntax corresponding to the data source type.
Post-Executed SQL
SQL statements executed after the synchronization task. Fill in the SQL according to the correct SQL syntax corresponding to the data source type.
Advanced Settings (Optional)
You can configure parameters according to business needs.