1. Supports connecting to ClickHouse using JDBC, and only supports reading data using JDBC Statement.
2. Supports filtering specific columns, column reordering, etc. You can specify the columns yourself.
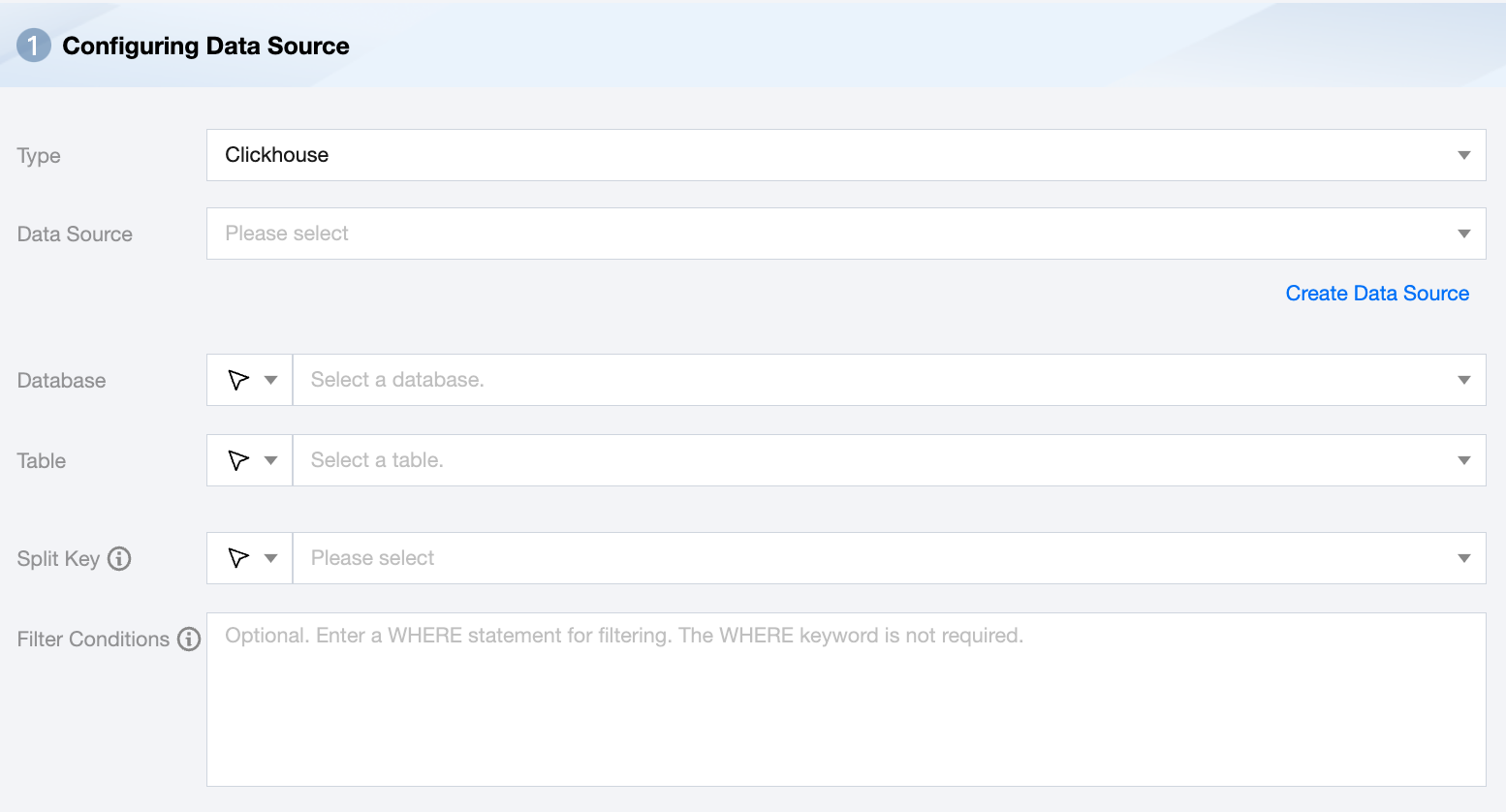
ClickHouse Offline Single Table Read Node Configuration
Parameters
Description
Data Source
Available ClickHouse Data Source.
Database
Supports selecting or manually entering the database name to be read
By default, the database bound to the data source is used as the default database. Other databases need to be manually entered.
If the data source network is not connected and the database information cannot be fetched directly, you can manually enter the database name. Data synchronization can still be performed when the Data Integration network is connected.
Table
Supports selecting or manually entering the table name to be read.
Split Key
When extracting data from ClickHouse, if splitPk is specified, it indicates that you want to use the field represented by splitPk for data sharding. As a result, data synchronization will start concurrent tasks, improving data synchronization efficiency.
You can use a column from the source data table as a split key. It is recommended to use the primary key or an indexed column as the split key. Only integer fields are supported.
During data reading, data sharding is performed based on the configured field to achieve concurrent reading, which can enhance data synchronization efficiency.
Filter Conditions (Optional)
In actual business scenarios, it is common to synchronize data of the current day, with the where condition specified as gmt_create>$bizdate.
The where condition can effectively perform incremental business synchronization.
If the WHERE clause is not provided, including missing the key or value, the data synchronization is treated as full data synchronization.
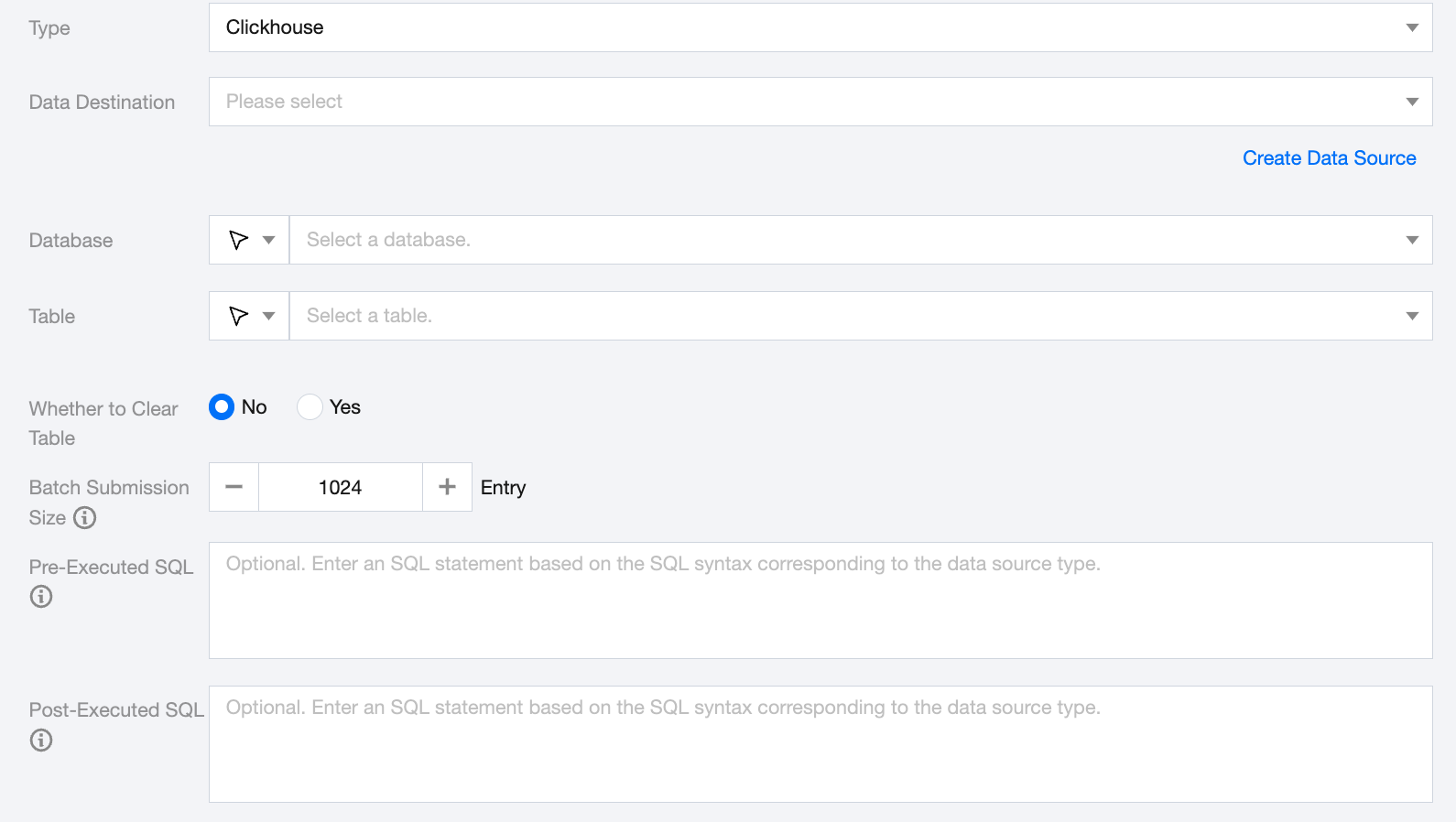
ClickHouse Offline Single Table Write Node Configuration
Parameters
Description
Data Destination
ClickHouse Data Source that needs to be written.
Database
Supports selection or manual input of the database name to write to
By default, the database bound to the data source is used as the default database. Other databases need to be manually entered.
If the data source network is not connected and the database information cannot be fetched directly, you can manually enter the database name. Data synchronization can still be performed when the Data Integration network is connected.
Table
Supports selection or manual input of the table name to write to
If the data source network is not connected and the table information cannot be fetched directly, you can manually enter the table name. Data synchronization can still be performed when the Data Integration network is connected.
Whether to Clear Table
Before writing to this ClickHouse data table, you can manually choose whether to clear the data table.
Batch Submission Size
The size of records submitted in batches at one time can greatly reduce the number of network interactions between the data synchronization system and ClickHouse, and improve overall throughput. If this value is set too high, it may cause OOM exceptions in the data synchronization process.
Pre-Executed SQL (Optional)
The SQL statement executed before the synchronization task. Fill in the correct SQL syntax according to the data source type, such as clearing the old data in the table before execution (truncate table tablename).
Post-Executed SQL (Optional)
The SQL statement executed after the synchronization task. Fill in the correct SQL syntax according to the data source type, such as adding a timestamp (alter table tablename add colname timestamp DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP).
Data type conversion support
Read
ClickHouse Data Type
Internal Types
Integer,Smallint,Tinyint,Bigint
Long
Float32,Flout64,Decimal
Double
String,Array,Null
String
Date32,Datetime64
Date
Write
Internal Types
ClickHouse Data Type
Long
Integer,Smallint,Tinyint,Bigint
Double
Float32,Flout64,Decimal
String
String,Array
Date
Date32,Datetime64
FAQs
Failure to insert identical data after delete
Cause:
The data inserted into the replica table will be divided into data blocks. Each data block will generate a block_id and be stored in the block subdirectory of the corresponding table directory in ZooKeeper.
Data blocks are automatically deduplicated based on block_id. For identical data blocks (data blocks with the same size and the same order of identical rows) that are written multiple times, the block will only be written once.
Therefore, for the same piece of data, multiple inserts into the replica table will only write the data the first time. When this data is deleted, it is successfully removed, but the block_id existing on Zookeeper is not deleted along with it. This causes subsequent inserts of this data to be identified by the table engine as duplicate data and skipped, so the data does not get written into the table and can't be queried.
Solution:
Set `insert_deduplicate=0` to temporarily disable the deduplication mechanism. Find the corresponding block_id under Zookeeper and manually delete this block_id.It is recommended to use truncate table to delete data.