Key-Value Encoding and Keyspace
In TDSQL Boundless, all data is encoded into a Key-Value (KV) pairs. The encoded keys are designed to be mem-comparable, which allows efficient sorting and comparison directly in memory.
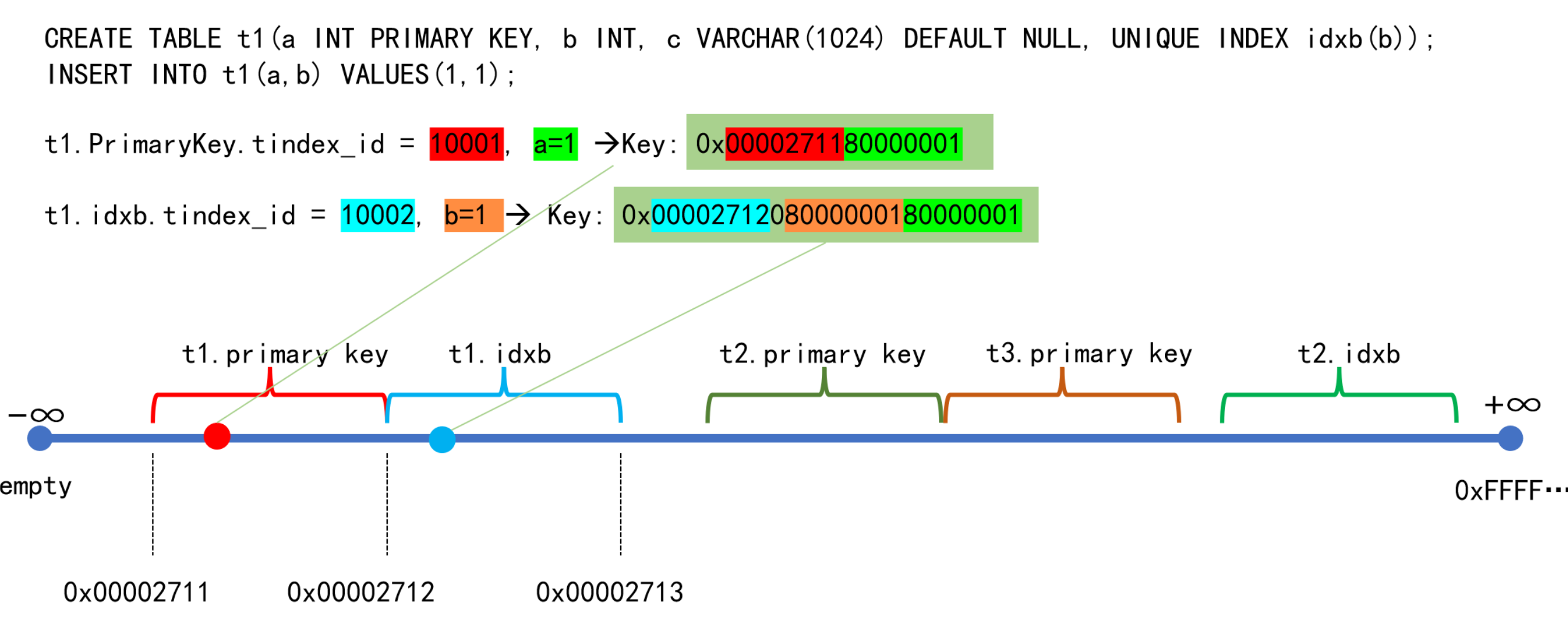
Encoding Rules: The system assigns a globally unique and monotonically increasing ID to every index (both primary and secondary). For example, the primary key and a secondary index for a table t1 will each have their own unique ID. All data for a given index shares a same prefix in its encoded keys (e.g., all keys for t1's primary key might start with 00002711), making the keys for that index logically contiguous.
Keyspace: You can visualize the data as being distributed along an infinitely long, sorted keyspace, where every key occupies a unique point. Data for a single index, sharing the same prefix, is therefore clustered together in a continuous range on this line. Such a continuous range of data is called a Region.
As a result, data for a single index is spatially contiguous, but the data for different indexes belonging to the same table may be distributed across different, non-contiguous Regions.
Data Sharding and Replication Group
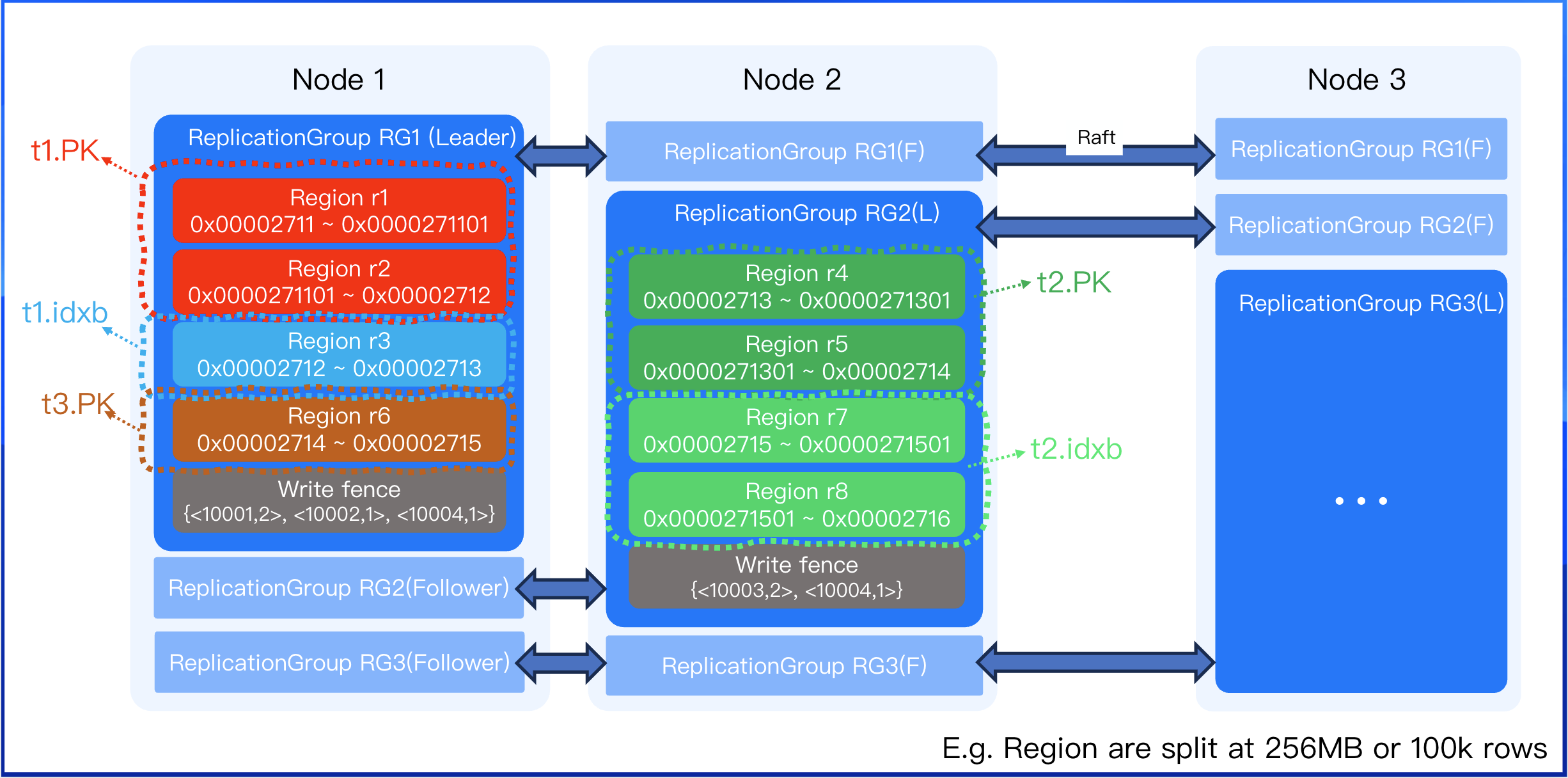
While the keyspace is a logical concept, each KV pair must be physically stored. When the data volume becomes too large for a single node, the data is partitioned into multiple shards. These shards are the physical embodiment of the logical Regions. A region is typically split when it grows beyond a standard capacity, such as 256 MB or 100,000 rows. Because different indexes have different data sizes, they will be split into a varying number of regions. Due to varying data volumes across different indexes, the number of index regions may differ.
As shown below, table t1 has fewer than 100,000 rows, but its value fields are large. The primary key records take up more space, requiring 2 regions, while a more compact secondary index might only need 1 region.
Table t2 has many rows (e.g., 200,000 rows), each KV pair is small. Its primary key and secondary index would each be split into 2 regions to hold 100,000 rows a piece.
To optimize data scheduling and performance, a higher-level construct called a replication group(RG) is used. For example,reven though the Regions for t1.pk (primary key) and t1.idxb (secondary index) are distinct, they can be bundled into the same replication group. This co-location provides two key benefits. It avoids the need for 2PC (Two-Phase Commit) distributed transactions on INSERT operations and prevents cross-node lookups when queries use a secondary index to fetch table data. A single replication group can contain multiple regions, and the leader of the replication group also serves as the leader for all regions within it.