Overview of the KV Separation Feature
Unduh
Mode fokus
Ukuran font
What Is KV Separation
In the LSM-Tree storage engine, keys (Key) and values (Value) are stored in the same SST file by default. When a Value is large (such as a
TEXT / BLOB / JSON field ranging from several KB to tens of KB), each Compaction operation requires repeatedly reading and writing these large values to the next level, resulting in severe Write Amplification (Write Amplification).The core idea of KV separation is: when the size of a record's Value exceeds a set threshold, store the Value separately in an independent Blob file, while keeping only a pointer to the Blob in the SST file. This approach:
SST file sizes are significantly reduced, and Compaction only needs to move pointers.
Large Value data is "deposited" in Blob files and is hardly involved in Compaction.
Write amplification is significantly reduced, which in turn benefits both disk I/O and SSD lifespan.
Data Layout Comparison
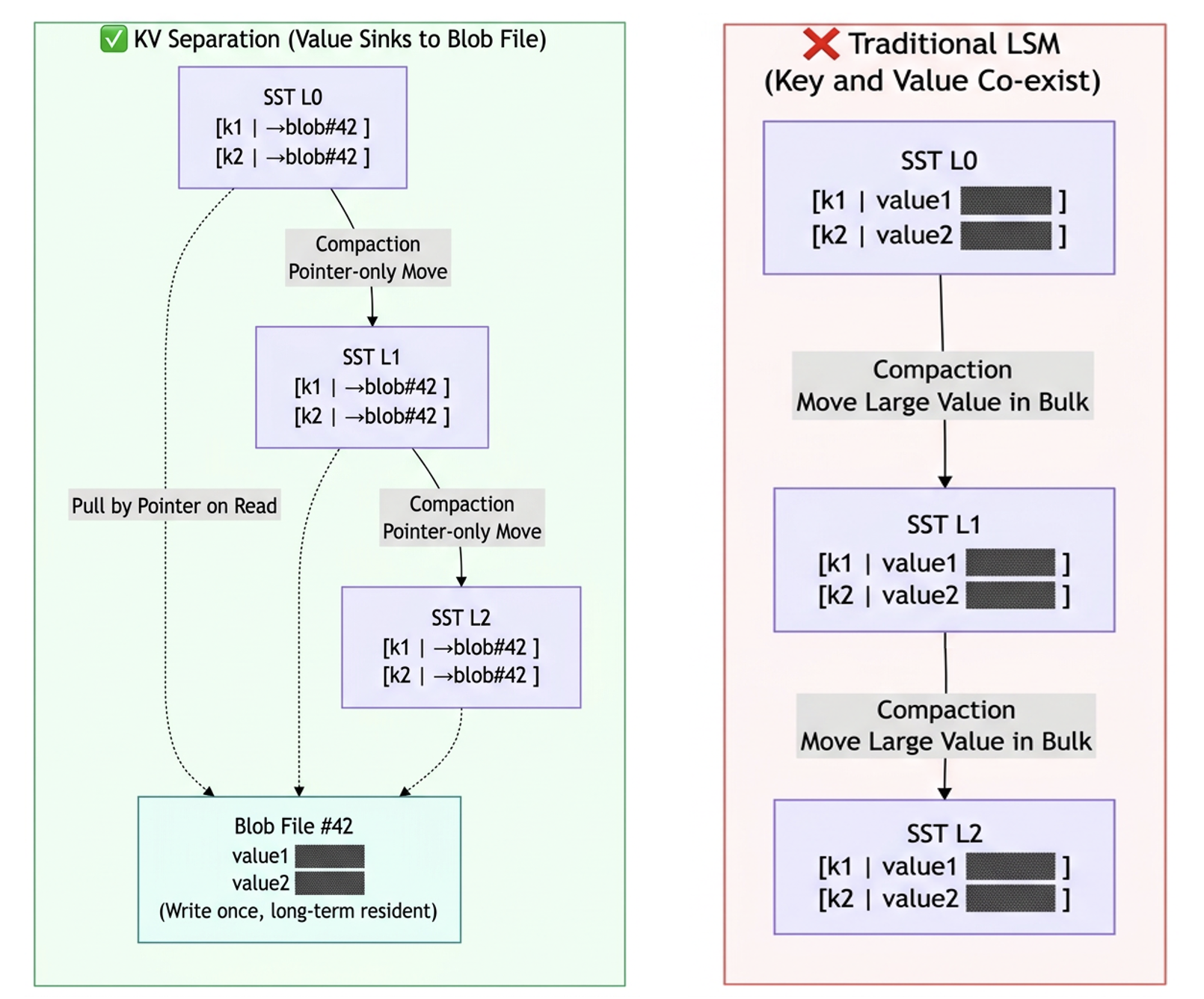
TDStore's KV separation capability is implemented based on RocksDB 7.x Integrated BlobDB. On top of this, TDStore has added multiple self-developed enhancements (see Performance Optimization Points for details).
Core Benefits
Benefit | Description |
Write Amplification Reduction | Large values no longer participate in Compaction, and the overall write amplification can be reduced by several times. |
Write throughput improvement | After the Compaction pressure decreases, foreground writes become more stable, and tail latency improves. |
SSD lifespan extension | The total disk write volume is reduced, and SSD wear is decreased. |
More Efficient Backup/Migration | SST size is reduced, making Region migration and Snapshot synchronization faster. |
Note:
Standard Server (CPU Bottleneck): QPS increased from 18.5K to 21.2K, representing an improvement of approximately 14%.
Cloud Disk with 300 MB/s Throttling (I/O Bottleneck): QPS increased from 4.2K to 9.2K, representing an improvement of approximately 118%.
In scenarios with I/O constraints, such as cloud disks, the benefits of KV separation are particularly significant.
Applicable and Inapplicable Scenarios
Scenarios Recommended for Enabling KV Separation:
The average Value size per row is greater than or equal to 1 KB. Typical examples include:
Rich text, article body, chat message logs (
TEXT / LONGTEXT)Image thumbnails, small binary attachments (
BLOB)Large JSON documents (user profiles, product details, log aggregation)
Write-heavy and read-light workloads, or workloads where reads are dominated by point queries/primary key queries.
Significant Compaction pressure or write amplification issues have been observed in the business.
Scenarios Not Recommended for Enabling KV Separation:
Most Values are small (< 256 B). Enabling KV separation for them introduces an additional pointer dereference, which is counterproductive.
Businesses that are highly sensitive to the P99 latency of point queries (enabling KV separation adds an extra Blob file I/O per read operation).
A large number of short-lived records (frequently updated/deleted) put significant pressure on Blob GC.
Analytical queries that involve intensive range scans and require reading the Value for each row.
Decision Flowchart
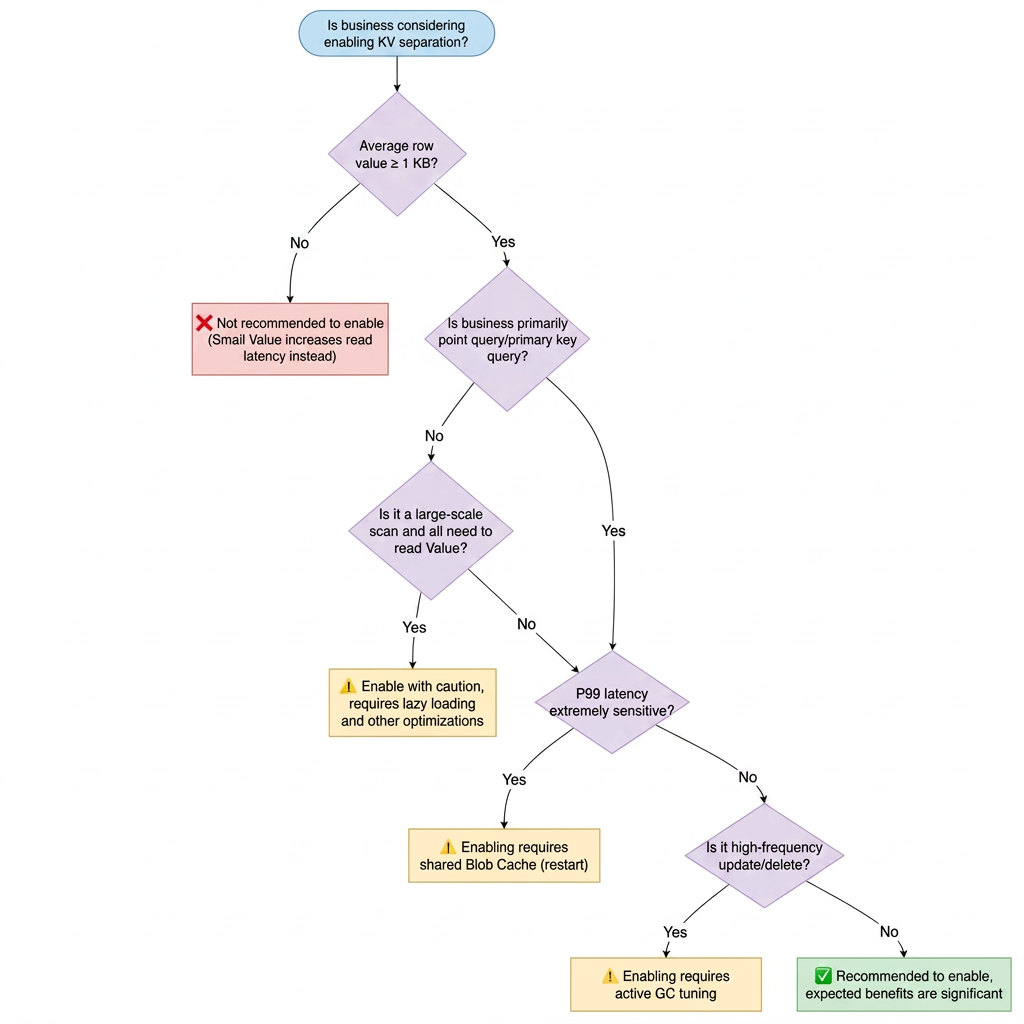
Note:
It is recommended that you first conduct a benchmark comparison test in a test environment (enabled vs. disabled), observe write amplification, QPS, and latency, and then decide whether to deploy to production.
Bantuan dan Dukungan
Apakah halaman ini membantu?
Anda juga dapat Menghubungi Penjualan atau Mengirimkan Tiket untuk meminta bantuan.
masukan