Release Notes
Announcements
Security Announcements
http://${master_ip}:18088 in your browser (or go to the EMR console > Cluster Service) to open the login page of Supserset. The default username is admin, and the password is the one you set when creating the cluster.

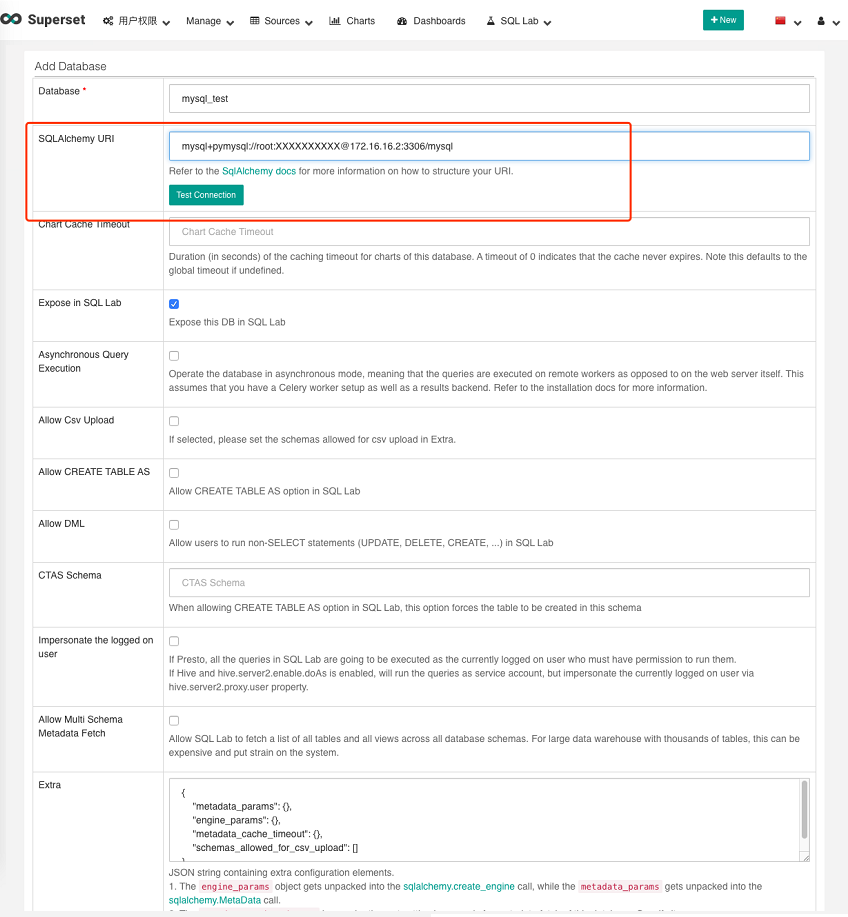
Name | SQLAlchemy URI | Remarks |
MySQL | mysql+pymysql://:@:/ | mysqlname: Username used to connect to MySQL.password: MySQL password.your_database: The MySQL database to be connected to. |
Hive | hive://hadoop@<master_ip>:7001/default?auth=NONE | master_ip: Master IP of the EMR cluster. |
Presto | presto://hive@:9000/hive/ | Master_ip: master_ip of the EMR cluster hive_db_name: Name of the database in Hive. If this parameter is left empty, it will be default by default |
Impala | impala://:27000 | core_ip: core IP of EMR cluster. |
Kylin | kylin://:@:16500/ | kylin_user: Kylin username password: Kylin password master_ip: master_ip of the EMR cluster kylin_project: Kylin project |
ClickHouse | clickhouse://:@:8123/ | clickhouse://default:password@localhost:8123/default user_name: Username password: Password clickhouse-server-endpoint: ClickHouse service endpoint database_name: Name of the database to be accessed |
source /usr/local/service/superset/bin/activate command.フィードバック