本稿は並列クエリ機能の実装原理を紹介します。
並列原理
TDSQL-C for MySQLはパラレルクエリ(Parallel Query)機能をリリースし、完全なデータパーティションを異なるスレッドにプッシュダウンし、複数のスレッドによる並列計算を実現します。計算結果はユーザースレッドに集約されユーザーに返され、クエリ効率を向上させます。
以下に簡単な例を用いて、パラレルクエリの基本原理を紹介します。
説明:
MySQL/InnoDBの物理ストレージはセグメントページ方式であり、パーティション単位はページです。ここでは行を使用してパーティションの概念を説明します。
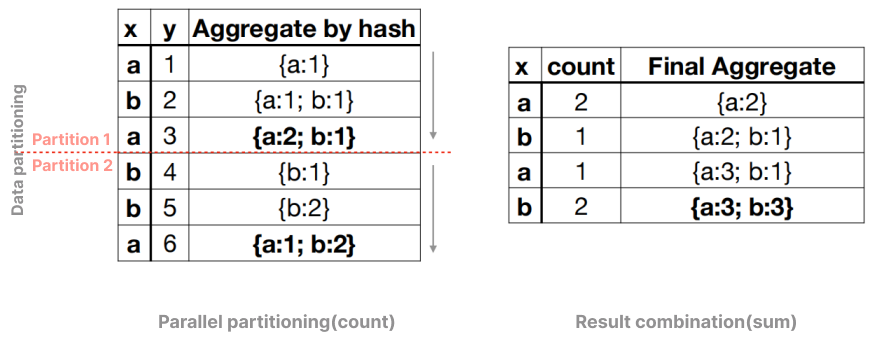
与えられたテーブルtと以下のグループ化集約クエリ。
select x, count(*) from t group by x;
ハッシュ集約アルゴリズム(反復評価)のプロセスは以下の表の通りです。アルゴリズムは各行を反復処理し、グループ集約状態を更新します。すべてのデータ行の反復が終了すると、グループ集約結果が得られます。集約状態の更新操作が一定であると仮定すると、アルゴリズムの時間計算量はO(n)となります。
このクエリをk個のスレッドで高速化する場合(ここでk=2)、まずデータテーブルをk * p個のパーティション(ここでp=1)に分割するのが最適です。これにより、各スレッドはp個のパーティションを処理し、部分結果を生成します。これらの部分結果は最終結果ではないため、マージ処理が必要です。マージ操作は正しい最終結果を得るために、同一のユーザースレッド内で実行する必要があります。
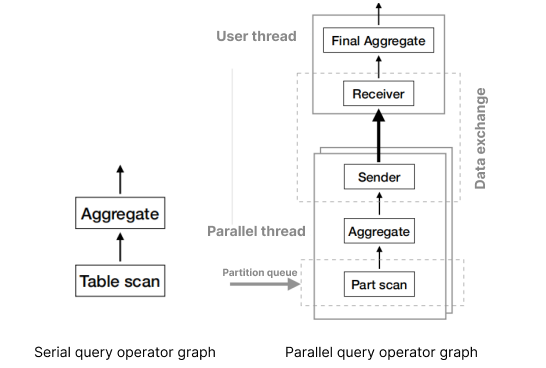
上記の例から、シリアルクエリモードとパラレルクエリモードの演算をオペレータグラフで次のように表現できます:
オペレータグラフから、パラレルクエリではデータが並列度に基づき複数の重複しないパーティションに分割されることがわかります。このプロセスはデータパーティションと呼ばれます。 データパーティションが完了した後、元のプラン内の特殊演算も分割されます。このプロセスはタスク分割と呼ばれます。すべての分割が完了すると、データは複数のワーカースレッド(並列スレッド)によってスキャンおよび実行されます。ワーカースレッドは各部分の結果をデータエクスチェンジオペレータを介してユーザースレッドに集約します。このプロセスはデータエクスチェンジに依存しています。
データエククスチェンジが完了すると、ユーザースレッドが集約操作を実行し、結果を集計して完全な結果を出力します。このプロセスでは、ユーザースレッドがデータパーティションとタスク分割を担当すると同時に、コーディネータ役割(コーディネータスレッドとも呼ばれる)を果たし、複数のワーカースレッドがサブタスクを並列実行するよう調整します。ユーザースレッドは最終結果を統合してユーザーに返す役割も担います。ワーカースレッドは並列サブタスクを実行し、データチャネルを介して中間結果を交換します。
では、パラレルクエリの核心要素を次のようにまとめることができます:
データパーティション:元のテーブルデータを重複のないパーティションに分割し、パーティション単位でのデータ読み取りをサポートします。
タスク分割:元のプラン内の特殊演算を「部分-全体」の2段階演算に分割します。さらに、データエクスチェンジオペレータを挿入し、スレッド間データ転送をサポートします。
データエクスチェンジ:異なるスレッド間でのデータ受け渡しをサポートします。
パラレルプロセス
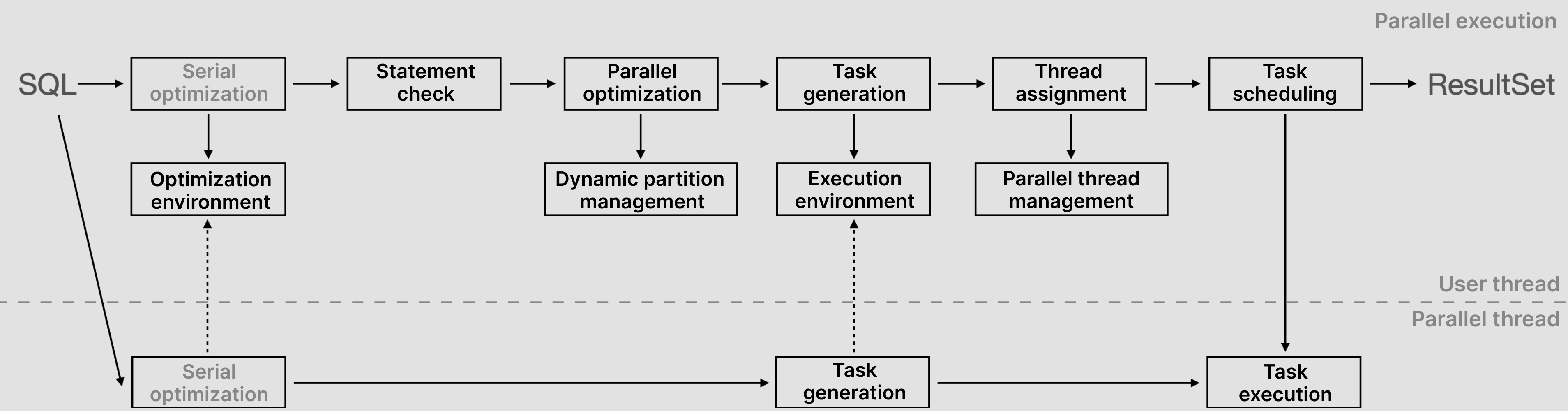
TDSQL-C for MySQLは上記の原理に基づき、完全なパラレルクエリプランを実装し、シリアル処理フローをパラレル処理フローに拡張しました。下図に示します。
従来のMySQLシリアルフローでは、SQL文はまずシリアル最適化され、シリアル実行計画が出力された後、反復モデルで結果が出力されます。このプロセス全体の効率は高くありません。パラレルクエリ機能を実現するため、TDSQL-C for MySQLはSQL文処理フロー全体を新たに設計しました: 1. 並列クエリの原理に基づくと、プロセス全体はユーザースレッドとワーカースレッド(並列スレッド)の2つの部分に分割され、すべてのプロセスはこれら2種類のスレッドで実行されます。SQL文の実行が開始されると、ユーザースレッドはオプティマイザ内で設定されたパラメータ値に基づいてこの文を分析し、対応する実行計画を生成します。SQL最適化環境は、高度に抽象化された決定論的計算モジュールと簡単に理解できます。その入力はSQLと最適化環境であり、出力は実行計画です。同じ入力に対しては常に同じ最適化パスが適用され、同じ出力が生成されるため、結果の正確性が保証されます。
2. 実行計画が生成されると、ステートメント検出段階に入ります。この時、コンピューティング層は当該ステートメントがパラレルクエリ実行基準を満たしているかどうかを検出します。ステートメントレベルの検出には、ダイナミッククエリ、データ分離レベルがRCまたはRRであるか、データ処理量が十分かどうかのコスト判断が含まれます。実行計画レベルでは、反復オペレータと関数が並列化可能かどうかを検出します。基準を満たさない場合、ステートメントはシリアル実行に戻ります。基準を満たす場合はパラレルクエリを実行し、並列最適化段階に進みます。具体的な対応ステートメントについては、パラレルクエリ対応ステートメントシナリオをご参照ください。 3. 並列最適化段階では、コンピューティング層は要件に基づいてデータ分割対象のテーブルを選択し、集約やソートなどの操作に対してタスク分割を実施します。これにより各ワーカーが並列実行しやすくなります。最適化段階ではデータ分割が関わるため、各スレッドに割り当てられるデータが十分に均等になるよう、TDSQL-C for MySQLは動的パーティション管理機能を導入しています。これにより1つのスレッドが複数タスクを実行可能となり、データスキューの発生を最大限に防止します。
4. 上記の一連のプロセスが完了すると、コンピューティング層はパラレルクエリタスクを生成し、タスクレプリカの方式でワーカースレッドにプッシュダウンします。パラメータ設定値に基づいてワーカースレッド数を割り当て・制限し、ワーカースレッドはこの時点でパラレルクエリ操作の実行を開始します。各スレッドが並列実行され、結果を取得後、データをユーザースレッドにプッシュアップして集約処理を行い、ユーザーに返します。これにより、1つのステートメントに対する完全なパラレルクエリフローが完了します。
全体のフローは次のように要約できます。ユーザースレッドがSQLを受信すると、解析、検証、最適化などの通常の手順を経てシリアル実行計画を生成すると同時に、最適化プロセスで依存する各種情報(最適化環境)を収集します。次に、シリアル実行計画を分析し(ステートメント検出、実際には演算子ツリー、実行環境、最適化コストの検出)、並列最適化を開始するかどうかを決定します。並列最適化時には、シリアル演算子ツリーを粗粒度タスクに分割し、並列テーブル(動的パーティション)とタスク間データ交換アルゴリズムを選択し、タスク依存グラフを構築します。この時点でユーザースレッドの準備が整い、利用可能なスレッドマネージャから十分なワーカースレッドを割り当てれば、スケジューリング実行を開始できます。ワーカースレッドの完了後、並列クエリの原理に基づき、データはデータエクスチェンジを経てユーザースレッドに集約処理され、完全な結果がユーザーに返されます。
上記のプロセスにおいて、TDSQL-C for MySQLは複数のパラメータを設定し、ユーザーが並列クエリ機能を調整できるようにしています。これによりステートメントの実行コストや並列クエリによるリソース負荷などを制御し、さらに複数の監視指標によって並列クエリ関連の各種情報をリアルタイムで監視します。詳細については並列クエリの有効化/無効化をご参照ください。