このドキュメントでは、DLCにおける依存パッケージ管理の3階層モデルと操作方法について説明し、標準エンジン、リソースグループ/ジョブ、Notebookのシナリオで効率的かつ制御可能な依存環境を構成するのに役立ちます。
コア概念
階層モデル
依存環境の一貫性と制御性を確保するため、「標準エンジン」レベルにおいて、DLCはエンジンカーネルと標準イメージでプリセットされた保護された依存関係セットを維持しています。これをエンジンカーネルベースライン依存関係(以下「ベースライン依存関係」と呼ぶ)と称します。このセットはすべての依存関係解析とマージの起点となります。異なるイメージのベースライン依存関係の詳細については、実行環境をご覧ください。 エンジンカーネルのベースライン依存関係(ベースライン依存)
説明:エンジンカーネルのバージョンと標準イメージに付属するプリセット依存関係リスト。
特性:アンインストール不可;PyPI経由での直接上書き不可。バージョン調整はエンジンレベルでrequirements.txtを使用した「バージョンピン/上書き」による制御が必要。
作用:グローバルベースラインの上限として、プラットフォームの実行時の安定性と一貫性を確保します。
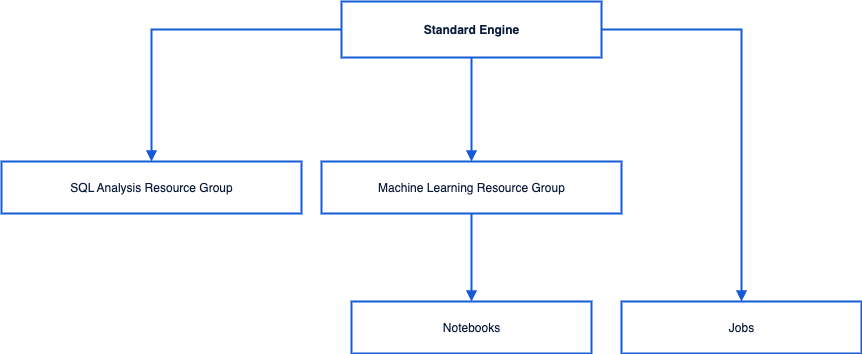
標準エンジン
機能:「ベースライン依存関係」に基づいて、限定的な依存関係の補完と制御された書き換えを行い、テナントエンジンレベルのグローバル依存関係ベースラインを形成します。
影響範囲:すべてのリソースグループ、ジョブ、およびNotebookがデフォルトで継承します。
リソースグループ
リソースグループ:SQL分析リソースグループ、機械学習リソースグループのみ。
作用:チーム/業務ラインの隔離層であり、汎用的だがグローバルではない依存構成を担います。
Notebookとジョブ
作用:個別化と実験的な最小増分依存関係であり、開発とデバッグのシナリオに密接しています。
継承とカスタマイズルール
継承関係:子レベルはデフォルトで親レベルの依存関係構成を継承します。
例えば:リソースグループはデフォルトで標準エンジンの依存関係を継承します。
カスタマイズ追加:任意のレベルで新しい依存関係を追加できます。追加された依存関係はそのレベルとその子レベルでのみ有効です。
例えば:「機械学習リソースグループ」で追加されたPythonパッケージは、そのリソースグループ内のジョブ/Notebookにのみ適用されます。
タスクインスタンスの最終的な依存環境 = ベースライン依存 + エンジン依存 + リソースグループ/ジョブ依存 + Notebook依存
インストール順序
インストール順序:エンジン/リソースグループ/ジョブ層の新規依存関係は「追加時間」の昇順でインストールされます。
競合ルール
競合セマンティックアライメントネイティブエコシステム
Maven(Jar):Mavenの解析と競合処理セマンティクスに従います。
PyPI(Python):pip/PEP仕様に従います。
上書きと改変
直接改変不可:エンジンに組み込まれた依存関係はPyPI方式で改変できません。
制御可能な改変:エンジンレベルでrequirements.txtを通じて組み込み依存関係のバージョンを再書き込みすることをサポートします。
有効時期とインストール状態
有効アクション:インストール、アンインストール、クローンは計算インスタンス起動時に有効になります。
トリガーシナリオ:
ジョブ起動
SQLリソースグループの再起動
機械学習リソースグループ:
ML オープンソースフレームワークと Python 依存関係:WedataのNotebook 探索ページでRestartをクリック
Spark MLlib 依存関係:WedataのNotebook 探索ページで Spark セッションを再作成します。
インストール状態を確認する:
エンジンレベル:最近のいずれかの計算インスタンスのインストール後の状態を表示します(SQLリソースグループとジョブAが順番に実行された場合、ジョブAに対応する状態が表示されます)。
リソースグループ/ジョブ/Notebookレベル:各次元のインストール状態を表示します。
依存エントリをクリックして、インストールの成功/失敗の詳細とログを確認できます。
前提条件
注意:
依存パッケージ機能はホワイトリスト機能です。この機能を使用するには、チケットを提出して サポートに連絡し、有効化してください。 標準エンジン Spark を購入します。
ストックエンジンを使用するには、チケットを提出して サポートに連絡し、エンジンイメージとゲートウェイイメージを2025-09-30以降のバージョンにアップグレードしてください。 操作ガイド
1. エンジンレベルの依存関係管理
ナビゲーションパス:リソース管理 → 標準エンジン → エンジンを選択 → 依存パッケージ管理。
インストール
COS / Local File
Jar と Python パッケージをサポート;COS バケットまたはローカルからアップロード。
PyPI
パッケージ名とバージョンを入力(PyPI命名規則に準拠);デフォルトでTencent Cloudリポジトリを使用し、外部ソースをサポート。
Maven
Maven 座標を入力;デフォルトでTencent Cloudリポジトリを使用し、カスタムリモートリポジトリと依存関係の除外をサポート。
アンインストール
依存関係を選択 → 「アンインストール」をクリックします。アンインストールは非同期操作で、次回の計算インスタンス起動時に有効になります。
クローン
他のエンジンから依存環境をワンクリックでクローン;重複する依存関係は自動的にスキップされます。
2. リソースグループレベルの依存関係管理
ナビゲーションパス:リソース管理 → 標準エンジン → エンジンを選択 → リソースグループ管理 → リソースグループを選択 → 依存パッケージ管理。
インストール/アンインストール:エンジンレベルと同様です。
3. ジョブレベルの依存関係管理
ナビゲーションパス:データ開発と探索 → データジョブ → ジョブの作成/編集 → 依存リソース
説明:単一のジョブに対して依存関係をカスタマイズし、そのジョブのみに適用されます。
インストール方法:エンジンレベルと同様です。
4. タスク依存環境の概要
ナビゲーションパス:運用管理 → 履歴タスクインスタンス → タスクを選択 → 依存環境。
説明:このタスクインスタンスが最終的に依存するセットとインストール状態(エンジン/リソースグループ/ジョブレベルをカバー)を表示し、迅速なトラブルシューティングを可能にします。
依存関係の競合処理
Maven(Jar)
直接依存関係の競合:後からインストールされたパッケージのインストールに失敗しました。
間接依存関係の競合:システムが自動的に競合する間接依存関係を削除し、インストールに成功しました。依存関係の削除記録を確認できます。
クラス競合:インストールは成功しましたが、実行時に競合が発生する可能性があります。
未使用競合クラス:タスクは正常に実行されます。
使用競合クラス:タスクが失敗し、ログに原因が表示されます。
PyPI(Python)
同階層の重複インストール:同じ名前または異なるバージョンの重複インストールで、後からインストールされた依存関係が失敗しました。
異なる階層の重複インストール:
標準エンジン/リソースグループ/ジョブレベル:追加された順にインストールを実行し、後からインストールされた依存関係が失敗します。
Notebookレベル:親レベルにある既存パッケージのバージョンを上書きできます。
ベストプラクティス
コア原則
エンジンレベルの依存関係を最小限に抑える
エンジンレベルはテナントエンジンレベルのグローバルベースラインであり、全体に影響します。「すべてのシナリオで必要」という共通依存関係を確認しない限り、エンジンレベルに過剰な依存関係を追加することは推奨されません。グローバルな結合とクロスチームの互換性コストを削減します。
リソースグループを使用して分離と階層化された進化を優先する
チーム/ビジネスラインの共通依存関係をリソースグループレベルに配置し、異なるチーム/プロジェクトの差異化されたニーズを自然に分離し、グローバルな汚染を回避します。
ジョブ/Notebook レベルで最小限の補完を行う
ジョブ/Notebook に固有のもの、短期間の検証、または小範囲の個別化された依存関係のみを配置します。複数のジョブで再利用される場合は、リソースグループレベルに移行して一元管理します。
シナリオベースの提案
複数のチームで同一のエンジンを共有
エンジンは「企業向け汎用基盤」を維持します。
チームごとの差異化された依存関係は、それぞれのリソースグループに配置し、相互に影響を与えないようにします。
アルゴリズムチームの迅速な実験
Notebook 段階では迅速な試行インストールが可能です。リリース前に依存関係をリソースグループレベルで固定化します。
よくあるご質問(FAQ)
Q:Mavenの推移的依存関係の競合をどのように処理しますか?
A:システムは自動的に競合する依存関係を削除し、詳細を記録します。インストールログと「削除記録」で影響範囲を確認してください。
Q:インストール/アンインストールがすぐに有効にならないのはなぜですか?
A:依存関係の変更は、コンピューティングインスタンスの起動時に有効になります。「有効化アクション」を押してリソースグループを再起動するか、ジョブ/セッションを再作成してください。