
BatchComputeはビッグデータコンピューティングビジネスを取り扱う企業及び科学研究機構のために、ハイコストパフォーマンスで且つ利用しやすいコンピューティングサービスを提供しています。BatchComputeはユーザー提示のバッチ処理規模により、ジョブを管理し、必要となる最適化したリソースをスケジューリングすることが可能です。Batch処理により、ユーザーがデータ結果の分析・処理に集中できるようになります。

特徴

完全なホスティング
ユーザーはバッチコンピューティング中のリソース・プロセススケジューリングを完全にBatchComputeにホスティングすることができます。ユーザがコンピューティングジョブをカスタマイズしサブミットしてから、BatchComputeのコンピューティング作動状態を確認すればいいです。コンピューティングに使われるCVMの新規作成と廃棄、コンピューティング環境のデプロイと実行、オリジナルデータと結果の保存管理は、完全にBatchにより処理されます。

コストの最適化
タスク数とリソースのリクエストにより、ユーザがバッチ処理タスクのために新規作成したコンピューティングリソースをダイナミックに構成したり柔軟に拡張したりすることができことにより、リソースの利用コストを下げると同時に、Batchの事前投資コストがゼロですので、ユーザはよりやすいコストでより十分にリソースを利用し、コンピューティングジョブを実行することができます。

強力で利用しやすい
多くのアシスタント機能を提供することにより、ユーザのコンピューティングジョブのカスタマイズとサブミットに貢献しています。例えば色々な実行方法の定義、コンピューティングプロセスの設計、状態監視などです。BatchComputeはCOSのようなほかのクラウドサービスと密に連携しています。コンピューティングデータからバッチ処理の取得、コンピューティングジョブの提示と実行、コンピューティング結果のアップロードの三つの段階においてはワンストップ式のクローズドループのサービスを提供しています。
機能
詳細なタスク定義
Batchを使うには、ユーザーはバッチ処理タスクが必要となるCVMコンフィグレーション、イメージ及び実行用のソースコード・コマンドを指定する必要があります。Batchはコンフィグレーション情報におりリソースをスケジューリングしコンピューティングタスクを起動します。
CVMコンフィグレーションを定義
CVMのCPU、メモリ、ディスク容量などの情報を指定します。
実行イメージを定義
バッチ処理タスクの依存する実行環境を指定します。CVMイメージとDockerの方式による実行環境の指定をサポートします。
コマンドラインとパラメータを実行
BatchはCVMを新規に作成してイメージをデプロイした後に、ユーザー指定のコマンドラインを実行し、ユーザー設定のパラメータを追加します。
ストレージマウント
Batchはよく使われているクラウドストレージサービスをローカルにマウントする機能をサポートしています。ユーザーがクラウドストレージ製品におけるファイルを操作するのはローカルでのファイル操作と同じです。大量の並列アクセスが起こる場合には、各ノードのアクセススピードを保証することにより、迅速的なファイルアクセスを実現しています。BatchはCOSのマウントをサポートしています。ユーザーはBatchのタスクカスタマイズにマウントする必要のあるCOSアドレス、及びマウントされる対象であるローカルアドレスを設定すると、Batchはコンピューティングノードが立ち上がる時に自動的にマウント操作を実行します。
タスク依存関係のモデリング
Batchは異なるタスク間の依存関係を定義でき、一つのタスクにおいて複数のインスタンスを立ち上げてコンピューティングタスクを完成することをもサポートしています。例えば、処理する必要のあるタスクは二つの段階に分けられ、各段階は必要となるリソースが違う場合には、Batchのタスク依存機能を利用することにより、二つのリソース要求のタスクを新規に作成し、その内、一つのタスクがもう一つのタスクに依存することが可能です。
DAG プロセスエディット
DAGの文法により、複数のバッチ処理タスクに対し依存関係を設定することにより、複数のバッチ処理を一つのバッチ処理ジョブにすることが可能です。
複数インスタンスの並列処理
タスク設定の中インスタンス数を指定する同時に、環境変数方式により、異なるインスタンスはそれぞれ各自のインスタンス番号を取得し、並列処理の形により一つの大型分析タスクを完成することが可能です。
ユースケース
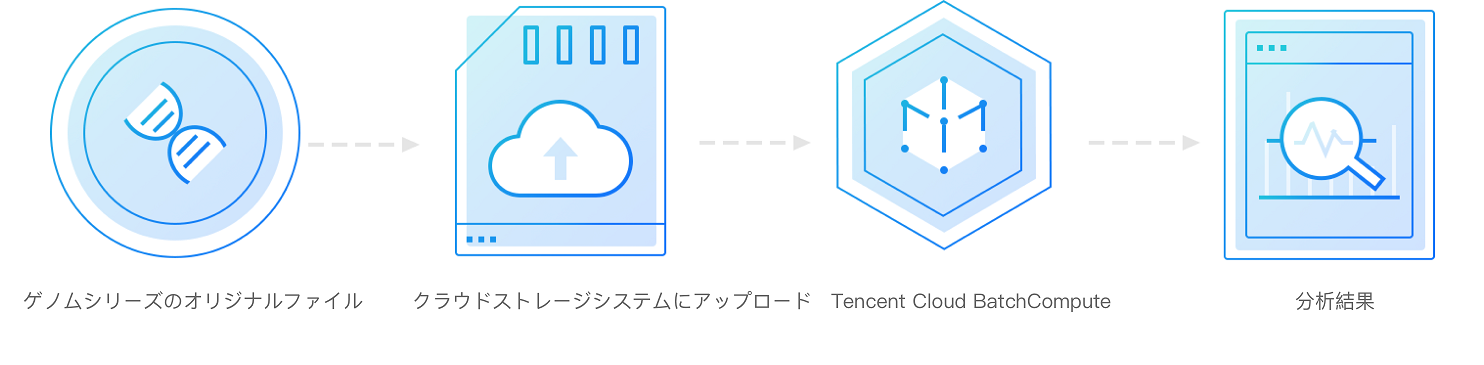
ライフサイエンス
デジタルメディア
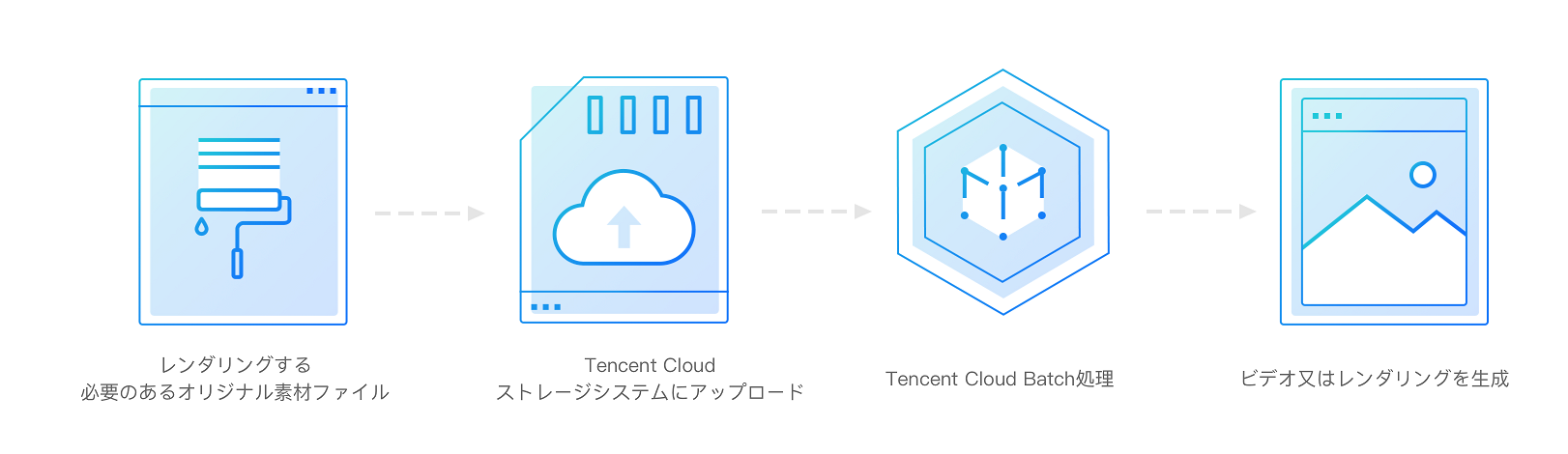
データの加速と自動化処理を実現するために、メディアとエンタティンメントカンパニーは高度化の拡張可能なBatchComputeリソースが必要です。Tencent CloudのBatchはユーザーのために自動化コンテンツレンダリング作業ラインの機能を提供しています。ユーザーは自分のレンダリング依存プロセスを構築できる同時に、Batchの大量リソースとジョブスケジューリング能力によりビジュアルクリエーティブ作業を効率よく実現することが可能です。
データの加速と自動化処理を実現するために、メディアとエンタティンメントカンパニーは高度化の拡張可能なBatchComputeリソースが必要です。Tencent CloudのBatchはユーザーのために自動化コンテンツレンダリング作業ラインの機能を提供しています。ユーザーは自分のレンダリング依存プロセスを構築できる同時に、Batchの大量リソースとジョブスケジューリング能力によりビジュアルクリエーティブ作業を効率よく実現することが可能です。
料金
BatchComputeサービスそのものは完全に無料です。
BatchComputeスケジューリングジョブの実行中には、ユーザーのコンフィグレーションによりCVMインスタンスを新規作成します。新規作成されたCVMインスタンスはCVMの従量課金モードにより課金されます。