
TDMQ for CKafka (CKafka) は、オープンソースのKafka API(0.9、0.10バージョン)と100%互換性のあり、分散式、高スループット、高いスケーラビリティを備えたメッセージングシステムです。パブリッシュ/サブスクライブに基づいて、CKafkaはメッセージのデカップリングにより、メッセージプロデューサーとコンシューマーがお互いを待たずに非同期で対話できるようにします。CKafkaには、データ圧縮をしながら、オフラインおよびリアルタイムデータ処理をサポートできるという利点があり、圧縮されたログの収集や監視データの集計などのケースに適しています。

特徴

オープンソースコンポーネントとの互換性あり
Apache Kafka 0.9 0.10バージョンと100%の互換性があり、クラウドへのマイグレーションは無料です。オープンソースプロセス全体のコンポーネントとの交換性を備え、Kafka Streams、Kafka Connect、KSQLに対しシームレスサポートをします。

アップストリームとダウンストリームのエコシステム
EMR、COS、CIS、SCS、SCF、CLS などの13+のクラウド製品と連携し、ワンクリックデプロイを実現できます。

高い信頼性
CKafkaクラスターは、オープンソースソリューションを超える強力なパフォーマンスと生産性を備えています。さらに、CKafkaの分散式デプロイでは、クラスターの安定性も非常に優れています。

高いスケーラビリティ
ユーザーエクスペリエンスに影響を与えることなく、クラスターの自動水平スケーリングとインスタンスのシームレスなアップグレードをサポートします。

ビジネスセキュリティ
異なるテナント間のネットワーク分離、インスタンスのネットワークアクセスはアカウント間で自然に分離されます。管理ストリームのCAM認証とデータストリームのSASL権限制御がサポートされ、アクセス権が厳密に制御されます。

監視・メンテナンスの統合管理
テナント隔離、権限制御、メッセージ積上げクエリー、コンシューマー詳細表示などの多次元監視アラームなど、Tencent Cloudプラットフォームの運用およびメンテナンスサービスの完備なセットを提供します。
機能
送受信のデカップリング
ピークシフト
水平スケーリング
一回の生産で複数回の消費
送受信のデカップリング
CKafkaは、プロデューサーとコンシューマーの関係を効果的にデカップリングし、ユーザーが同じインターフェースの制約を順守することを保証する限り、生産と消費間の処理プロセスを独立的に拡張または修正できます。
したがって、CKafkaは、従来のメッセージミドルウェアをスムーズに置き換えることができます。プロデューサーとコンシューマーをデカップリングし、未処理メッセージをキャッシュしながら、CKafkaは、より大きなスループット、より強いパーティションのレプリケーションメカニズムとフォールトトレランスメカニズムを備えています。
ピークシフト
業務アクセス量が急増する場合、システムが緊急事態に対応する能力が非常に重要になります。ただし、バーストトラフィックはめったにないため、トラフィックのピーク値を目安として投入すると、リソースが無駄になります。
CKafkaは、過負荷リクエストによるシステムクラッシュを引き起こさないように、重要なシステムコンポーネントにバーストトラフィックによるアクセス負荷に対処できることを保証します。
水平スケーリング
メッセージの処理はデカップリングされているため、スケーリング処理プロセスのみが必要であり、メッセージのキューイングの効率と処理効率を効果的に高めることができ、非常に柔軟です。実装に関しては、CKafka は一つのTopicを複数のPartitionに分けて、一つまたは複数のBroker に分散できます。 </ p> <p>一つのコンシューマーは一つまたは複数のPartitionにサブスクライブでき、プロデューサはメッセージを対応するPartitionにアサインします。したがって、Brokerの数を増やすと、クラスターをスケーリングできます。一般的にBrokerが多いほど、クラスターのスループット率が高くなります。
一回の生産で複数回の消費
CKafkaは、キュー、パブリッシュ/サブスクライブモードなど複数のモードをサポートします。CKafkaトピックはパーティションの概念をサポートし、異なるパーティションは異なるブローカーに分類され、スループットを効果的に向上させます。さらに、CKafkaは、パブリッシュ/サブスクライブモードとマルチキューモードをサポートし、コンシューマー グループポリシーを利用し、トピックは一つのノードに一つのデータのみを保存し、各コンシューマー グループは各自の消費記録データをメンテナンスします。一回の生産で複数のコンシューマーグループの消費ケースを保証できます。
機能
送受信のデカップリング
CKafkaは、プロデューサーとコンシューマーの関係を効果的にデカップリングし、ユーザーが同じインターフェースの制約を順守することを保証する限り、生産と消費間の処理プロセスを独立的に拡張または修正できます。
したがって、CKafkaは、従来のメッセージミドルウェアをスムーズに置き換えることができます。プロデューサーとコンシューマーをデカップリングし、未処理メッセージをキャッシュしながら、CKafkaは、より大きなスループット、より強いパーティションのレプリケーションメカニズムとフォールトトレランスメカニズムを備えています。
ピークシフト
業務アクセス量が急増する場合、システムが緊急事態に対応する能力が非常に重要になります。ただし、バーストトラフィックはめったにないため、トラフィックのピーク値を目安として投入すると、リソースが無駄になります。
CKafkaは、過負荷リクエストによるシステムクラッシュを引き起こさないように、重要なシステムコンポーネントにバーストトラフィックによるアクセス負荷に対処できることを保証します。
水平スケーリング
メッセージの処理はデカップリングされているため、スケーリング処理プロセスのみが必要であり、メッセージのキューイングの効率と処理効率を効果的に高めることができ、非常に柔軟です。実装に関しては、CKafka は一つのTopicを複数のPartitionに分けて、一つまたは複数のBroker に分散できます。 </ p> <p>一つのコンシューマーは一つまたは複数のPartitionにサブスクライブでき、プロデューサはメッセージを対応するPartitionにアサインします。したがって、Brokerの数を増やすと、クラスターをスケーリングできます。一般的にBrokerが多いほど、クラスターのスループット率が高くなります。
一回の生産で複数回の消費
CKafkaは、キュー、パブリッシュ/サブスクライブモードなど複数のモードをサポートします。CKafkaトピックはパーティションの概念をサポートし、異なるパーティションは異なるブローカーに分類され、スループットを効果的に向上させます。さらに、CKafkaは、パブリッシュ/サブスクライブモードとマルチキューモードをサポートし、コンシューマー グループポリシーを利用し、トピックは一つのノードに一つのデータのみを保存し、各コンシューマー グループは各自の消費記録データをメンテナンスします。一回の生産で複数のコンシューマーグループの消費ケースを保証できます。
ユースケース
ログ分析システム
ストリームデータ処理プラットフォーム
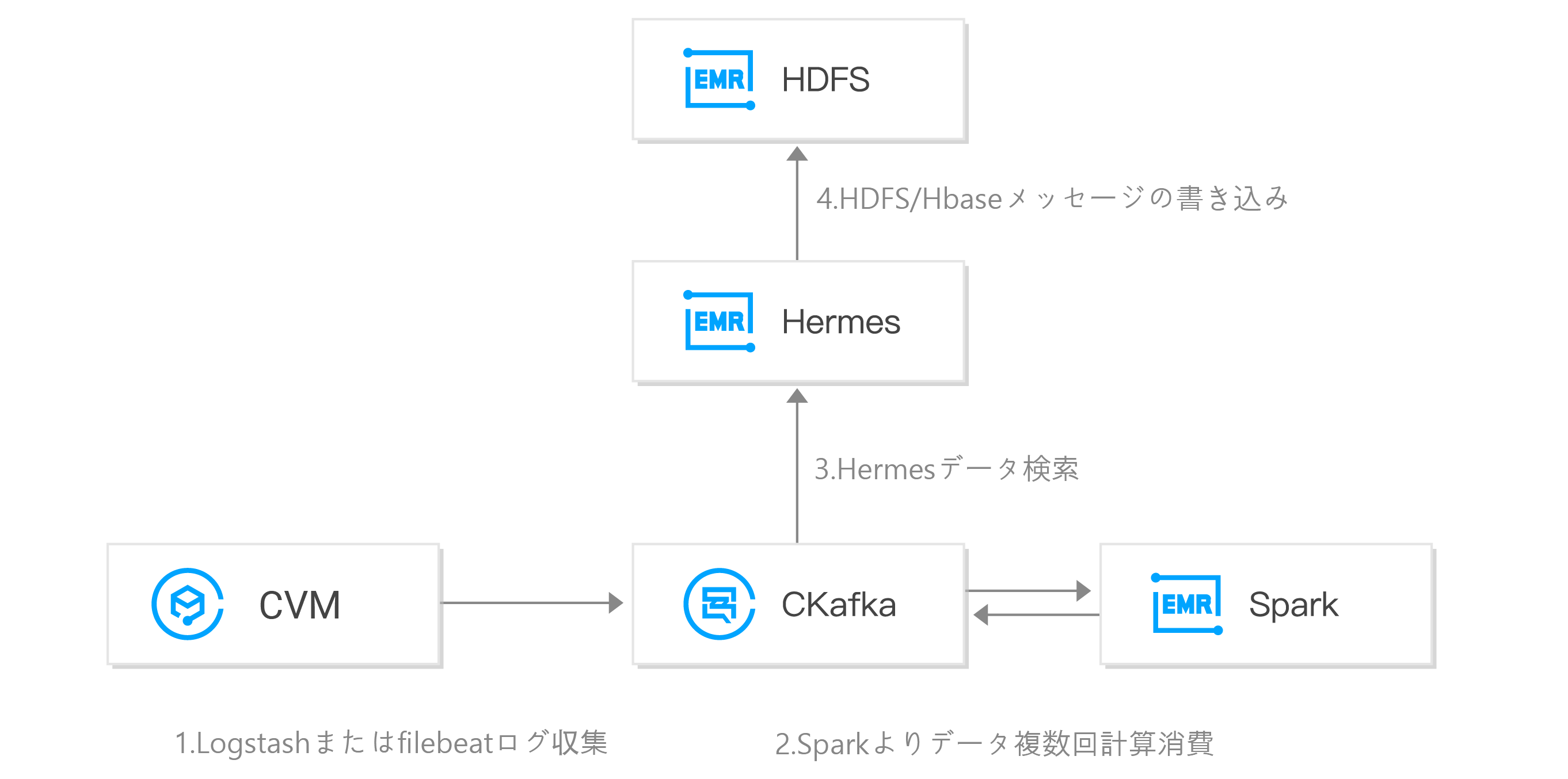
CKafkaは、ビッグデータスイートEMRと連携し、完備なログ分析システムを構築します。最初に、ログデータを収集するためにagentがクライアントにデプロイされ、データがCKafkaに集約されます。その後、Sparkなどのバックエンドのビッグデータスイートにより複数回のデータ計算が実行され、元のログデータに対してクリア、書き込み・保存、グラフィカル表示が行われます。
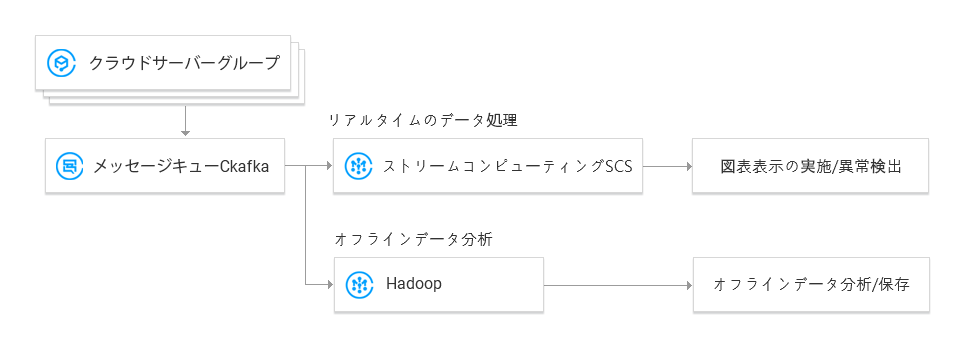
CKafkaは、リアルタイム/オフラインデータ処理および異常検出のために、ストリームコンピューティングSCSと連携し、さまざまなケースに対応できます:
- リアルタイムデータを分析および表示し、異常検出を実行して、システムの問題を迅速に特定します
- コンシューマー履歴データは保存され、オフラインで分析され、データの2次処理、傾向レポートの生成などが行われます。
料金
CKafkaは、従量課金とサブスクリプションの2 つの課金モードをサポートしています。詳細については、 課金概要をご参照ください。