수평 분할(샤드)은 TDSQL for MySQL의 실제로 분산 데이터베이스가 작동하는 방식입니다. 각 노드는 데이터 계산 및 저장에 참여하지만 데이터의 일부에만 해당합니다. 따라서 비즈니스가 어떻게 성장하든지 분산 클러스터에 장치를 계속 추가하기만 하면 증가하는 컴퓨팅 및 스토리지 요구 사항을 충족할 수 있습니다.
수평 분할
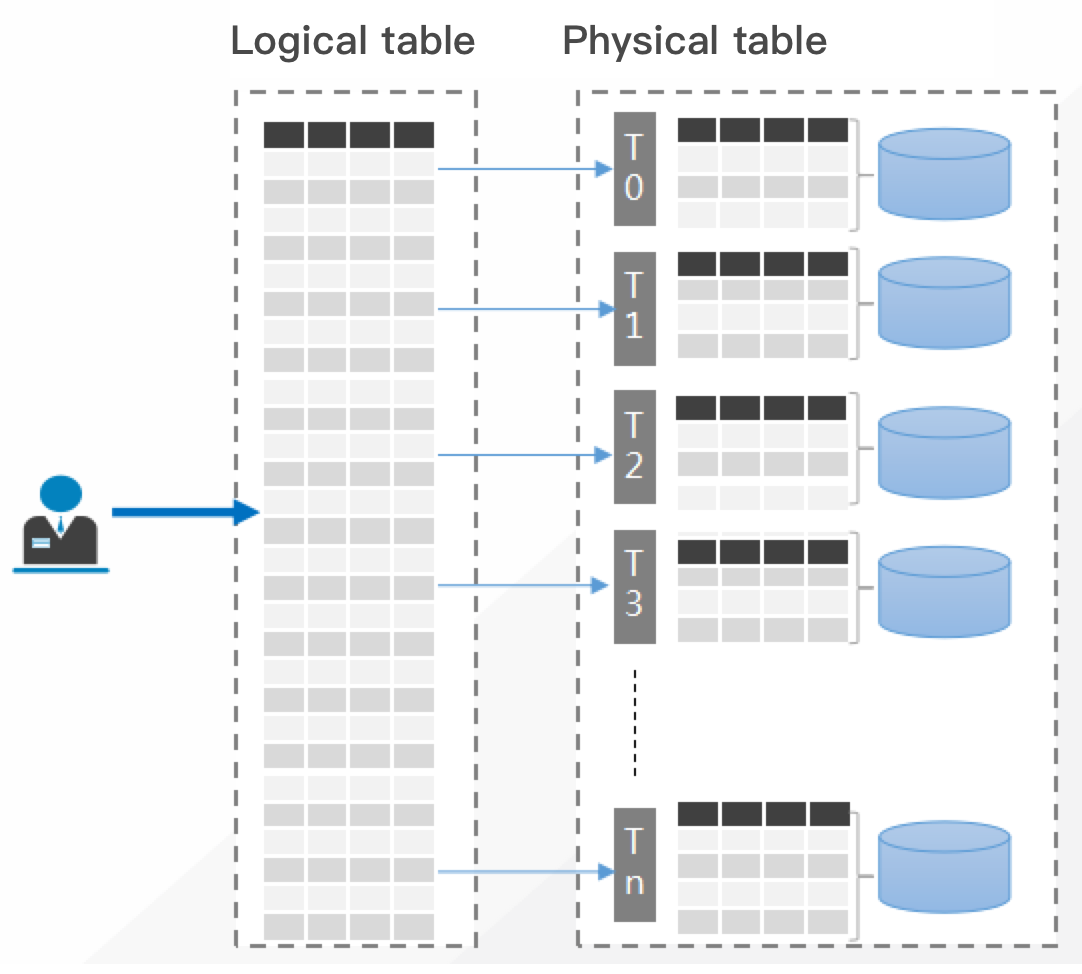
수평 분할(샤드): 정의된 규칙에 따라 테이블의 데이터를 여러 개의 독립된 물리적 데이터베이스 서버로 분산시켜 ‘독립적’인 데이터베이스 ‘샤드’를 형성하는 것입니다. 여러 샤드가 함께 논리적으로 완전한 데이터베이스 인스턴스를 형성합니다.
기존의 독립형 데이터베이스에서 전체 테이블의 읽기 및 쓰기는 하나의 물리적 저장 장치에서만 수행됩니다.
분산 데이터베이스에서 테이블 생성 중 설정된 샤드 키에 따라 시스템은 데이터를 다른 물리적 샤드에 자동으로 배포하지만 테이블은 여전히 논리적으로 완전합니다.
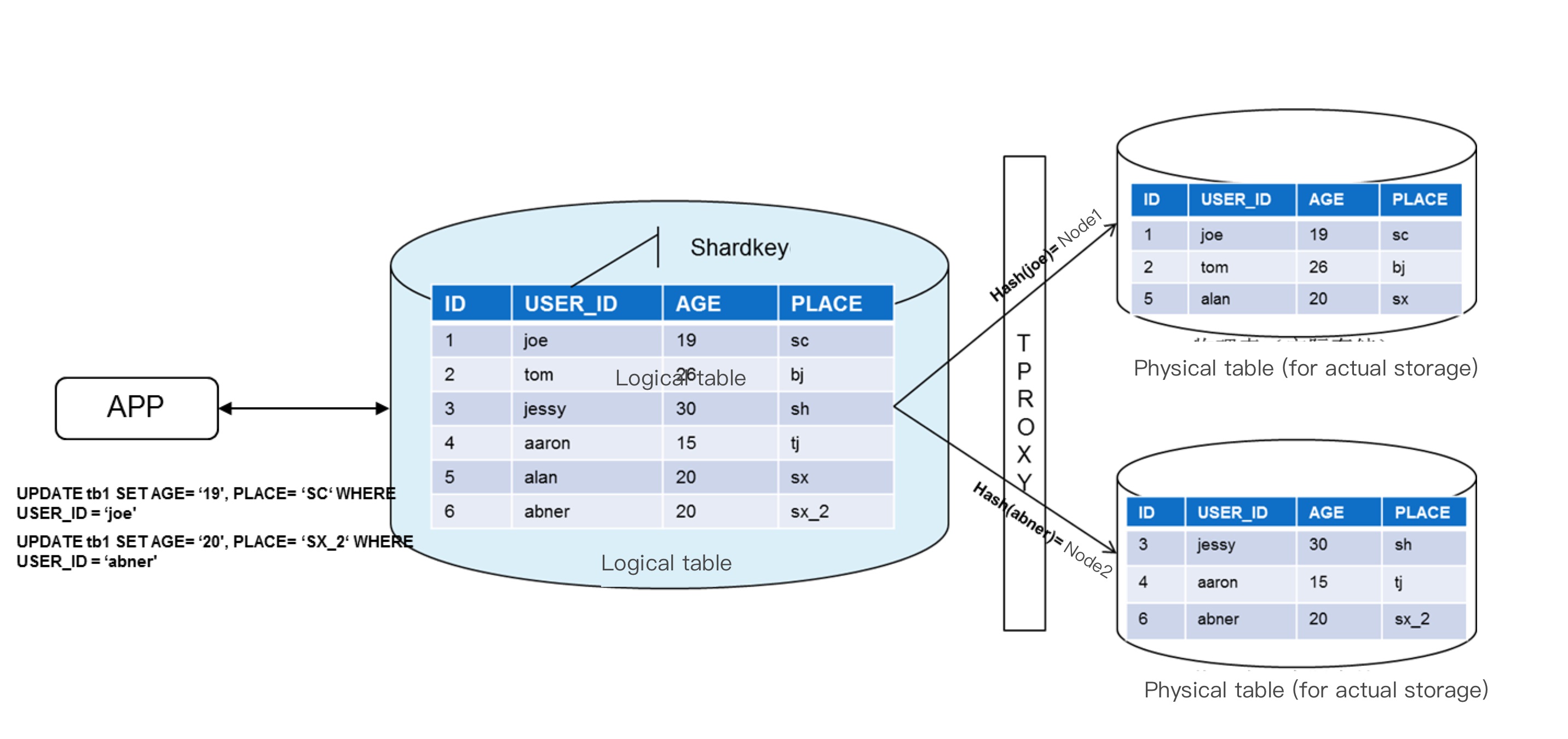
TDSQL for MySQL에서는 일반적으로 샤딩 차원을 결정하기 위해 샤드 키(shardkey)가 필요하며, 샤딩은 필드 모듈로 연산(HASH) 방식을 사용하여 수행됩니다. HASH 계산에 사용되는 필드는 shardkey입니다. HASH 알고리즘은 서로 다른 물리적 장치에 상대적으로 균일한 데이터 배포를 사실상 보장할 수 있습니다.
데이터 쓰기( SQL 문에 포함된 shardkey )
1. 비즈니스는 데이터 행을 씁니다.
2. 게이트웨이는 shardkey의 hash 계산을 수행합니다.
3. 다른 hash 값 범위는 다른 샤드에 해당합니다(스케줄링 시스템의 사전 샤딩 알고리즘에 의해 결정됨).
4. 데이터는 샤딩 알고리즘에 따라 실제 해당 샤드에 저장됩니다.
데이터 집계
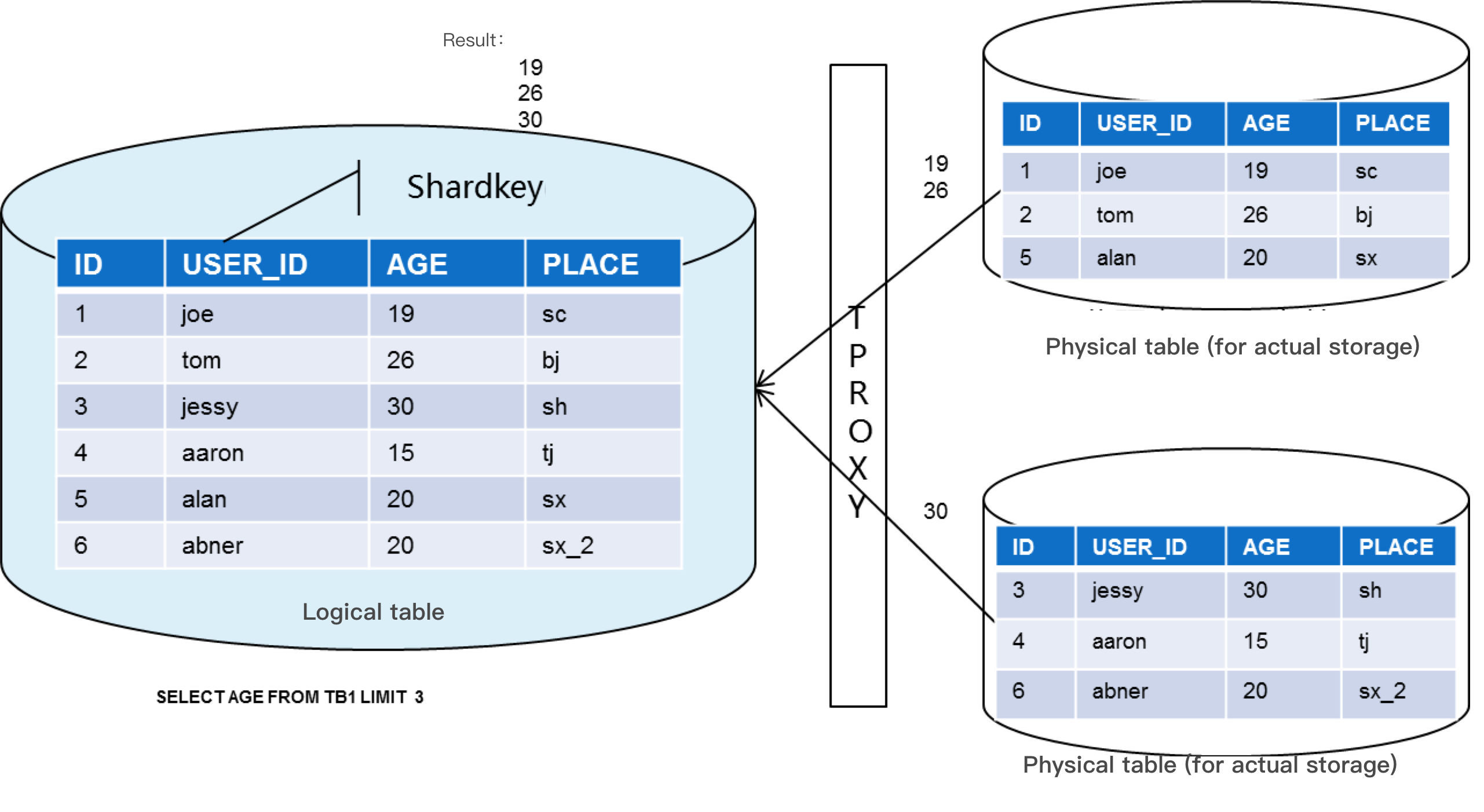
데이터 집계: 쿼리 SQL 문의 데이터에 여러 개의 분할된 테이블이 포함된 경우 명령문은 실행을 위해 이러한 모든 테이블로 라우팅됩니다. TDSQL for MySQL은 기존 SQL 의미를 기반으로 각 샤딩된 테이블에서 반환된 데이터를 집계하고 최종 결과를 반환합니다.
주의 사항:
SELECT 문을 실행할 때 shardkey 필드를 where 조건에 포함하는 것이 좋습니다. 그렇지 않으면 게이트웨이는 느리고 성능에 상당한 영향을 미치는 전체 테이블 스캔 후에 실행 결과를 집계할 수 있습니다.
데이터 읽기(특정 shardkey 포함):
1. 비즈니스가 shardkey를 포함하는 select 요청을 보내면 게이트웨이는 shardkey에 대한 hash 계산을 수행합니다.
2. 다른 hash 값 범위는 다른 샤드에 해당합니다.
3. 샤딩 알고리즘에 따라 해당 샤드에서 데이터를 얻습니다.
데이터 읽기(특정 shardkey는 포함되지 않음)
1. 비즈니스에서 보낸 shardkey가 없는 select 요청은 모든 샤드로 전송됩니다.