TSA Helps Sincetimes Enhance Business Stability for New Game Launch
Download
Modo Foco
Tamanho da Fonte
Última atualização: 2026-04-01 18:15:40
1. Background
The new game developed by Beijing Sincetimes Network Co., Ltd. is an offbeat supernatural academy adventure game featuring card-based cultivation and progression. This game service is built on Tencent Cloud products, including Cloud Load Balancer (CLB), Web Application Firewall (WAF), Tencent Kubernetes Engine (TKE), TencentDB for MongoDB, and Tencent Cloud Distributed Cache (Redis ®* OSS-Compatible). On the verge of the new game's launch, Sincetimes collaborated with Tencent Cloud's after-sales expert team to visualize the cloud architecture through the Tencent Cloud Smart Advisor (TSA) product and conducted availability chaos experiments on TSA-Chaotic Fault Generator (TSA-CFG) for core businesses, enhancing system stability.
2. Business Challenges
Sincetimes maintains stringent requirements for product stability. As its game business continues to expand, system complexity continuously increases, and more diverse production faults occur. These faults may cause game interruptions, data loss, and performance degradation at any time, severely impacting player experience and consequently incurring economic losses for game operations. During its cloud operations process, Sincetimes faces the following challenges:
Issues and requirements for cloud architecture management
Sincetimes requires clear architecture diagrams as support during cloud Ops troubleshooting. However, the current cloud architecture information is scattered in the respective template libraries of Ops, lacking a unified professional platform to integrate and present such information. Users expect to align role information across all stages through the platform, and intuitively display availability and capacity hazards of cloud products, thereby enabling efficient governance.
Challenges in verifying container cluster stability
Sincetimes has built a container cluster for game applications based on Tencent Cloud TKE, which hosts the core businesses of the game, thus requiring high stability for the container cluster. However, the container cluster on the live network is subject to a variety of fault scenarios, and users are unable to verify the performance of the container cluster and their applications through real-world faults. Therefore, they urgently desire to verify the architecture stability and reliability through TSA-CFG.
3. Solutions
3.1 Using TSA-Cloud Architecture for Visualized Architecture Management
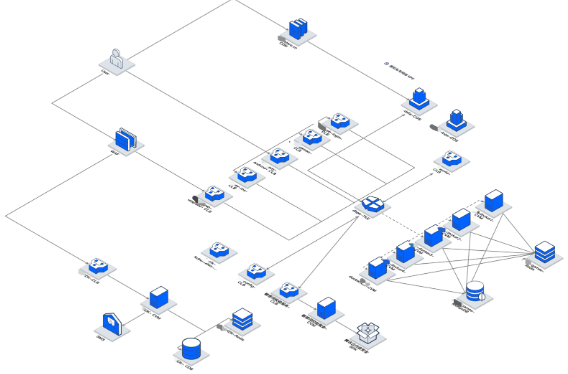
Through the architecture visualization feature provided by TSA-Cloud Architecture, business architecture diagrams are drawn to map out the customer's business system architecture online, clearly presenting the relationships between various business submodules at a glance. By precisely binding cloud resources to resources of each node in the architecture diagram, customers can clearly grasp the actual resource deployment status of each node and gain insights into dependencies between cloud products, thus ensuring efficient resource management. In addition, customers can leverage TSA-Cloud Risk Assessment to perform one-click scan and governance of availability hazards in the business architecture, providing foundational support for subsequent chaos experiments on TSA-CFG. The cloud architecture diagram for the new game business is as follows:
3.2 Using TSA-CFG for Fault Experiments
Through the fault injection experiment feature provided by TSA-CFG, hardware and software anomalies or disturbances are proactively introduced into the system to create fault scenarios. System availability is verified based on its behavior in various stress conditions, helping further formulate optimization policies.
3.2.1 Determining Experiment Objectives
1. Testing business elasticity capabilities: Verify whether the service of the game's primary process can be rapidly recovered within the expected 2 minutes based on container elasticity capabilities when a fault occurs, ensuring that the entire game server continues to provide services.
2. Testing rapid recovery capabilities for cloud product faults: Verify whether the business architecture can achieve resource failovers and fault recovery within 15 minutes when a fault occurs, to meet players' requirements for high stability.
3. Testing the effectiveness of business monitoring: Verify whether the coverage of resource monitoring and business metric monitoring is comprehensive. Test the timeliness of business alarm delivery, the effectiveness of emergency plans, and the emergency response capabilities of relevant personnel.
3.2.2 Formulating a GameDay
The following shows the entire process of a GameDay on TSA-CFG:
Before Experiment
Identify relevant Ops and business members participating in the chaos experiment on TSA-CFG;
With the assistance of Tencent Cloud after-sales experts, map out the overall business architecture, develop the GameDay plan, determine experiment scenarios, create experiments in advance, and prepare fault action orchestration beforehand;
Establish emergency response procedures for faults in advance, and designate the experiment commander-in-chief, operators for each process, recorders, and other relevant personnel.
During Experiment
After the experiment starts, the Ops owner executes the experiment on TSA-CFG and executes fault injection actions in each scenario.
After fault injection, business owners observe the specific impact of the fault on the business, and whether monitoring data and alarms are delivered normally;
After fault rollback and recovery, business owners observe whether business performance as well as monitoring alarms and metrics converge and return to normal as expected;
Record key data throughout the experiment.
After Experiment
Organize the data records during the experiment, including experiment logs and monitoring data;
On TSA-CFG, click to export the experiment report to facilitate review and analysis of the experiment by the team;
Record, analyze, and govern availability issues identified during the experiment.
3.2.3 Orchestrating Experiment Scenarios
This chaos experiment primarily targets the core businesses of Sincetimes for fault scenario experiments. Before executing this experiment, the Sincetimes business Ops team collaborated with Tencent Cloud after-sales experts to meticulously select a fault experiment plan covering the application layer and data layer. The plan includes multi-product fault scenarios, aiming to comprehensively assess system stability and reliability through combined fault scenario experiments, thereby providing a solid foundation for sustained and stable business operations. The fault experiment plan is as shown in the table below:
Application layer
Simulate fault experiment scenarios in a TKE environment, including high CPU utilization, high memory utilization, node shutdown, network packet loss, process termination, process killing, network out-of-order issues, and network latency.
Data layer
For core databases such as TencentDB for MySQL, Tencent Cloud Distributed Cache (Redis ®* OSS-Compatible), and TencentDB for MongoDB, perform verification operations, such as verifying whether services can be automatically switched after a primary node fault occurs, and whether the recovery time meets expectations.
4. Solution Implementation
This implementation leverages TSA for visualized cloud architecture management and chaos experiments. TSA-Cloud Architecture provides features such as architecture management, architecture assessment, architecture node capacity monitoring, and chaos experiments based on visualized cloud architecture. TSA-CFG supports quick creation of experiments, flexible orchestration of more than 100 fault scenario actions across the access layer, logic layer, and data layer, and enables parallel fault injection as well as monitoring and observability for large-scale instances. Combined with the intuitive visual interface of TSA-Cloud Architecture, this solution ensures that users can operate the experiment workflow more intuitively, precisely control the blast radius, and safeguard business security. The specific chaos experiment implementation is as follows:
4.1 Creating a Chaos Experiment
According to the experiment plan, create an experiment in advance on TSA-CFG. This mainly involves selecting the scope of target experiment object instances, orchestrating fault scenario actions, and adding business steady-state monitoring metrics.
The product currently provides over 130 atomic fault actions, supporting flexible serial and parallel combination and orchestration of these actions in a single experiment to meet diverse experiment needs.
4.2 Executing Fault Injection
During the execution of fault actions, you can view the execution status (success, failure, or in progress) and injection effects of these actions in real time through TSA-Cloud Architecture, making the experiment progress clear at a glance.
4.3 Observing the Effects
When using TSA to execute chaos experiments, the business team needs to synchronize the business impact and recovery status, while the Ops team needs to observe multiple types of monitoring alarms to evaluate the experiment effects. The experiment effects may be assessed through basic cloud resource monitoring metrics at the Infrastructure as a Service (IaaS) layer such as CPU utilization or through business metrics such as queries per second (QPS), latency, and number of online users. For example, during the node shutdown fault scenario simulation, the experiment effect observation process is as follows:
After fault injection: When the node is shut down, the Pod restart time is prolonged, and the Pod cannot be successfully started within the expected time.
Issue analysis: During this process, it was found that the game business failed to start normally. Upon investigation by the business team, the primary process of the game was unable to correctly assign IDs to other component services, resulting in game unavailability.
Issue recording and improvement plans: Finally, the primary process service of the game was recovered manually, restoring core game servers. Additionally, the business team also recognized the need to further optimize the primary process service processing of the game to mitigate this risk.
5. Customer Benefits
Sincetimes validated the availability of its core business systems through this business stability improvement practice, mainly achieving the following benefits:
1. One-stop governance for cloud architecture risks
Cloud architecture visualization: Cloud resources and business architectures are clearly displayed, and precise locating of cloud resources is enabled through nodes via quick resource binding to facilitate collaboration and information sharing across teams.
One-stop risk governance: The cloud risk assessment and monitoring features are used to effectively identify potential risks in the cloud architecture and business operations, increasing the business health score by approximately 20%. The operational procedures for one-stop risk governance are also simplified to improve operational efficiency.
2. Cloud business system availability improvement
Business availability assessment: By conducting fault experiments to identify issues, the business team improves its issue handling capabilities, which enhances confidence in business operations.
Proactive identification of potential hazards and issues: Through experiments, the business team identifies potential availability hazards and issues and governs them in advance, effectively mitigating risks on the live network.
System observability verification: The timeliness and effectiveness of system monitoring metrics and alarm delivery are verified.
Improved fault emergency plan: The business team has improved proficiency in the chaos experiment process, strengthening the ability of organizational personnel to handle emergencies.