Visão geral da separação automática de leitura/gravação
Download
Modo Foco
Tamanho da Fonte
Este documento descreve o recurso de separação automática de leitura/gravação do serviço de proxy de banco de dados no TencentDB for MySQL, além dos seus pontos fortes e regras de roteamento.
Separação automática de leitura/gravação
Separação automática de leitura/gravação
Atualmente, os negócios de muitos usuários no ambiente de produção têm problemas como mais leituras e menos gravações e cargas de negócios imprevisíveis. Em cenários de aplicativos com um grande número de solicitações de leitura, uma única instância pode não ser capaz de suportar a pressão das solicitações de leitura, o que pode até mesmo afetar os negócios. Para implementar o dimensionamento automático de recursos de leitura e reduzir a pressão no banco de dados, você pode criar uma ou várias instâncias somente leitura e usá-las para sustentar um grande número de leituras de banco de dados. No entanto, essa solução requer que os negócios possam ser transformados para suportar a separação de leitura/gravação e a robustez do código determina a qualidade da separação de leitura/gravação do negócio, o que impõe altos requisitos técnicos e tem baixa flexibilidade e escalabilidade.
Portanto, após criar uma instância somente leitura, você pode adquirir um proxy de banco de dados, habilitar a separação de leitura/gravação e configurar o endereço do proxy de banco de dados em seu aplicativo para encaminhar automaticamente solicitações de gravação para a instância de origem e solicitações de leitura para a instância somente leitura. Além disso, esse método fornece soluções naturais para outros desafios de negócios, conforme detalhado abaixo:
Aplicativos com cargas de trabalho imprevisíveis
Os aplicativos que suportam cargas de trabalho altamente variáveis podem tentar abrir novas conexões de banco de dados para lidar com picos de tráfego. O gerenciamento de conexões no proxy de banco de dados dedicado permite dimensionar adequadamente os aplicativos que processam cargas de trabalho imprevisíveis, reutilizando efetivamente as conexões de banco de dados.
Primeiro, esse recurso permite que várias conexões de aplicativos compartilhem a mesma conexão de banco de dados para usar efetivamente os recursos do banco de dados. Em segundo lugar, permite ajustar o número de conexões de banco de dados abertas para manter um desempenho previsível do banco de dados. Terceiro, ele permite que você exclua solicitações de aplicativos inutilizáveis para garantir o desempenho e a disponibilidade gerais do aplicativo.
Aplicativos frequentemente abrindo/fechando conexões de banco de dados
Aplicativos criados com base em tecnologias como serverless, PHP ou Ruby on Rails podem frequentemente abrir e fechar conexões de banco de dados para processar solicitações de aplicativos.
O proxy de banco de dados dedicado pode ajudá-lo a manter um pool de conexões de banco de dados para evitar pressão desnecessária na computação de dados e na memória usada para estabelecer novas conexões.
Aplicativos com conexões abertas, mas inativas
Aplicativos SaaS e aplicativos de comércio eletrônico tradicionais podem tornar as conexões de banco de dados ociosas para minimizar o tempo de resposta quando os usuários se reconectam. Você pode usar o proxy de banco de dados dedicado para manter conexões inativas e estabelecer conexões de banco de dados para solicitações ativas conforme necessário, em vez de aumentar excessivamente o limite ou fornecer serviços de banco de dados com especificações mais altas para dar suporte à maioria das conexões inativas.
Aplicativos que exigem failover altamente suave
Com o proxy de banco de dados dedicado, você pode criar aplicativos que podem tolerar falhas de banco de dados ativas e passivas de maneira imperceptível, sem escrever código de processamento de falhas complexo. O proxy de banco de dados dedicado roteará automaticamente o tráfego de leitura para novas instâncias de banco de dados, mantendo as conexões do aplicativo.
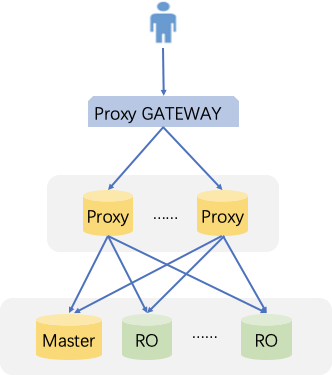
Pontos fortes
As solicitações de leitura/gravação são separadas automaticamente com um endereço de acesso unificado.
O suporte de ligação nativa melhora o desempenho e reduz os custos de manutenção.
Você pode definir pesos e limites de forma flexível.
Há suporte para failover, de modo que, mesmo que o proxy do banco de dados falhe, as solicitações podem acessar o banco de dados de origem normalmente.
Quando uma instância de origem é alternada, ou sua configuração é alterada, ou uma instância somente leitura é adicionada/removida, o proxy de banco de dados pode recarregar dinamicamente a configuração sem causar desconexões ou reinicializações de rede.
Regras de roteamento de separação de leitura/gravação
Envio para a instância de origem
Instruções DDL como
CREATE, ALTER, DROP e RENAME.Instruções DML como
INSERT, UPDATE e DELETE.Instrução
SELECT FOR UPDATE.Instruções relacionadas a tabelas temporárias.
Certas chamadas de funções do sistema (como
last_insert_id()) e todas as chamadas de funções personalizadas.Instruções relacionadas a
LOCK.Instruções após a transação ter sido habilitada (incluindo
set autocommit=0)Procedimentos armazenados.
Várias instruções concatenadas por ";".
KILL (instrução SQL, não comando)Todas as consultas e alterações de variáveis do usuário.
Envio para instância somente leitura
Ler instruções (
SELECT) fora das transações.Envio para todas as instâncias
instrução
show processlist.Todas as mudanças de variáveis do sistema (comando
SET).Comando
USE.Ajuda e Suporte
Esta página foi útil?
Você também pode entrar em contato com a Equipe de vendas ou Enviar um tíquete em caso de ajuda.
comentários