Release Notes
Announcements
Module Name | Supported | Service Module to Restart |
YARN | Yes | NodeManager |
YARN | Yes | NodeManager |
Hive | Yes | HiveServer and HiveMetastore |
Spark | Yes | NodeManager |
Sqoop | Yes | NodeManager |
Presto | Yes | HiveServer, HiveMetastore, and Presto |
Flink | Yes | None |
Impala | Yes | None |
EMR | Yes | None |
Self-built component | To be supported in the future | No |
HBase | Not recommended | None |

Cluster-wide Advanced Configuration Snippet(Safety Valve) for core-site.xml.<property><name>fs.AbstractFileSystem.ofs.impl</name><value>com.qcloud.chdfs.fs.CHDFSDelegateFSAdapter</value></property><property><name>fs.ofs.impl</name><value>com.qcloud.chdfs.fs.CHDFSHadoopFileSystemAdapter</value></property><!--Temporary directory of the local cache. For data read/write, data will be written to the local disk when the memory cache is insufficient. This path will be created automatically if it does not exist--><property><name>fs.ofs.tmp.cache.dir</name><value>/data/emr/hdfs/tmp/chdfs/</value></property><!--appId--><property><name>fs.ofs.user.appid</name><value>1250000000</value></property>
core-site.xml). For other settings, see Mounting COS Bucket to Compute Cluster.Configuration Item | Value | Description |
fs.ofs.user.appid | 1250000000 | User `appid` |
fs.ofs.tmp.cache.dir | /data/emr/hdfs/tmp/chdfs/ | Temporary directory of the local cache |
fs.ofs.impl | com.qcloud.chdfs.fs.CHDFSHadoopFileSystemAdapter | The implementation class of CHDFS for `FileSystem` is fixed at `com.qcloud.chdfs.fs.CHDFSHadoopFileSystemAdapter`. |
fs.AbstractFileSystem.ofs.impl | com.qcloud.chdfs.fs.CHDFSDelegateFSAdapter | The implementation class of CHDFS for `AbstractFileSystem` is fixed at `com.qcloud.chdfs.fs.CHDFSDelegateFSAdapter`. |
cp chdfs_hadoop_plugin_network-2.0.jar /opt/cloudera/parcels/CDH-5.16.1-1.cdh5.16.1.p0.3/lib/hadoop-hdfs/
hadoop jar ./hadoop-mapreduce-examples-2.7.3.jar teragen -Dmapred.map.tasks=4 1099 ofs://examplebucket-1250000000/teragen_5/hadoop jar ./hadoop-mapreduce-examples-2.7.3.jar terasort -Dmapred.map.tasks=4 ofs://examplebucket-1250000000/teragen_5/ ofs://examplebucket-1250000000/result14
ofs:// schema with the mount point path of your CHDFS instance.CREATE TABLE `report.report_o2o_pid_credit_detail_grant_daily`(`cal_dt` string,`change_time` string,`merchant_id` bigint,`store_id` bigint,`store_name` string,`wid` string,`member_id` bigint,`meber_card` string,`nickname` string,`name` string,`gender` string,`birthday` string,`city` string,`mobile` string,`credit_grant` bigint,`change_reason` string,`available_point` bigint,`date_time` string,`channel_type` bigint,`point_flow_id` bigint)PARTITIONED BY (`topicdate` string)ROW FORMAT SERDE'org.apache.hadoop.hive.ql.io.orc.OrcSerde'STORED AS INPUTFORMAT'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'OUTPUTFORMAT'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'LOCATION'ofs://examplebucket-1250000000/user/hive/warehouse/report.db/report_o2o_pid_credit_detail_grant_daily'TBLPROPERTIES ('last_modified_by'='work','last_modified_time'='1589310646','transient_lastDdlTime'='1589310646')
select count(1) from report.report_o2o_pid_credit_detail_grant_daily;
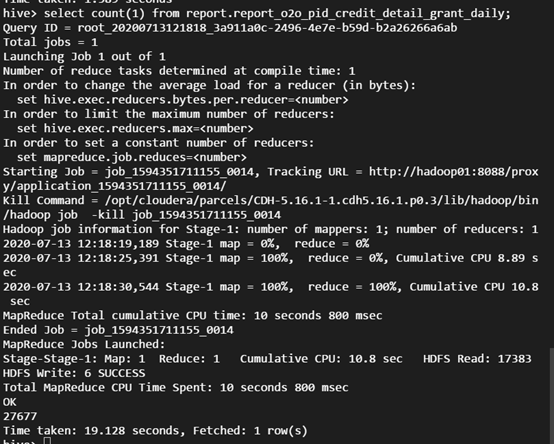
Spark example word count test as an example.spark-submit --class org.apache.spark.examples.JavaWordCount --executor-memory 4g --executor-cores 4 ./spark-examples-1.6.0-cdh5.16.1-hadoop2.6.0-cdh5.16.1.jar ofs://examplebucket-1250000000/wordcount
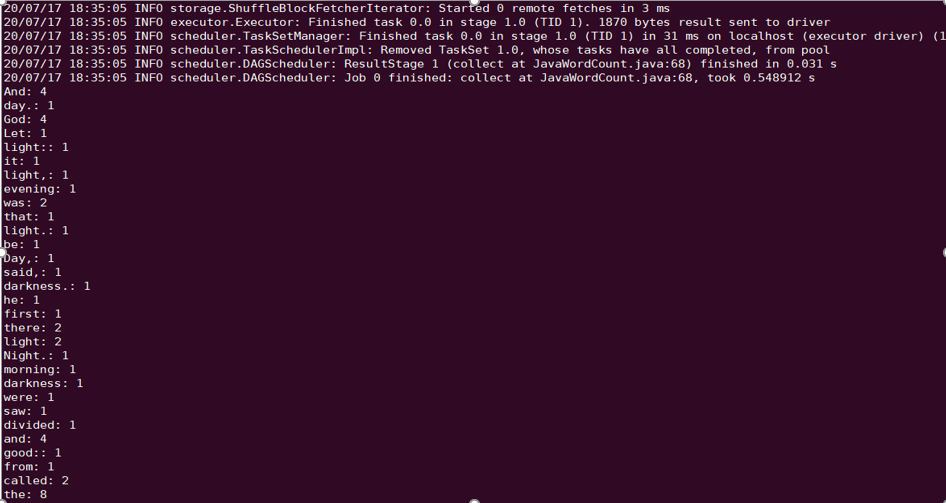
sqoop directory, for example, /opt/cloudera/parcels/CDH-5.16.1-1.cdh5.16.1.p0.3/lib/sqoop/.sqoop import --connect "jdbc:mysql://IP:PORT/mysql" --table sqoop_test --username root --password 123 --target-dir ofs://examplebucket-1250000000/sqoop_test
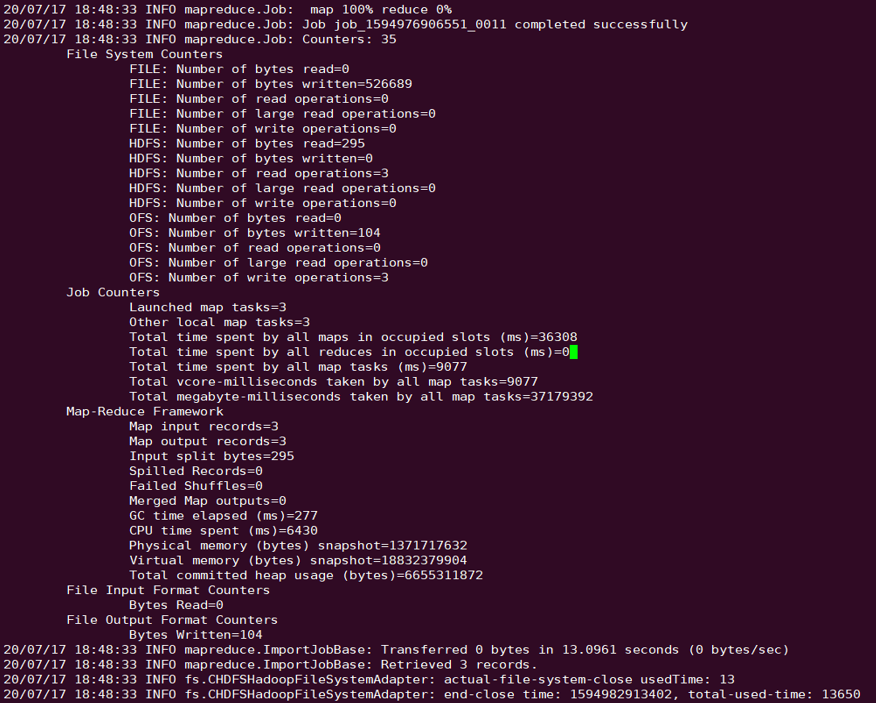
presto directory, for example, /usr/local/services/cos_presto/plugin/hive-hadoop2./usr/local/services/cos_presto/ plugin/hive-hadoop2.select * from chdfs_test_table where bucket is not null limit 1;
chdfs_test_table is a table with location as "ofs scheme".
Esta página foi útil?
Você também pode entrar em contato com a Equipe de vendas ou Enviar um tíquete em caso de ajuda.
comentários