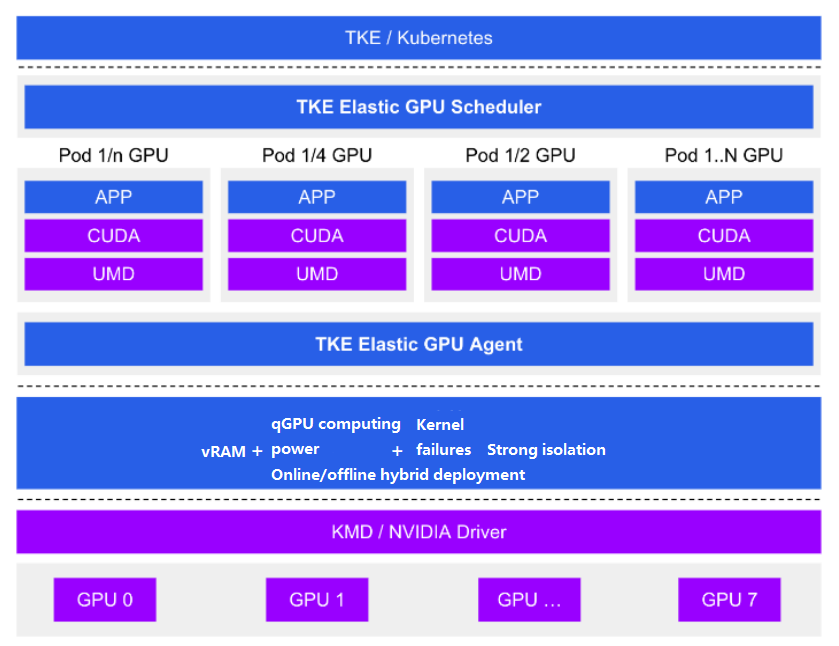
Tencent Kubernetes Engine qGPU (TKE qGPU) is a GPU virtualization service launched by Tencent Cloud. It supports sharing a GPU card among multiple containers and provides the capacity to finely isolate the vRAM and computing power among containers. Also, it provides the unique online/offline hybrid deployment capability to increase GPU utilization and help users significantly save their GPU resource costs on the basis of finely segmenting GPU resources and on the premise of ensuring their business stability.
Based on TKE's open-source Elastic GPU framework, qGPU can schedule GPU computing power and vRAM at a fine granularity, share a GPU card among multiple containers, and allocate GPU resources across GPU cards. Plus, relying on the powerful underlying isolation technology, it can strongly isolate vRAM and computing power to ensure that business performance and resource use are not affected by GPU sharing.
Note:
The qGPU feature is available only for TKE native nodes. No guarantee of effective service is provided for other node types.
Solution Framework Diagram
qGPU Strengths
Flexibility: Finely configure GPU computing capacity and vRAM size.
Strong isolation: vRAM and computing power can be strictly isolated.
Hybrid deployment: Supports online and offline hybrid deployment to maximize the GPU utilization.
Coverage: Supports popular architectures including Volta (such as V100), Turing (such as T4) and Ampere (such as A100 and A10).
Cloud nativeness: Standard Kubernetes and NVIDIA Docker solutions are supported.
Compatibility: No need to rewrite application code or replace CUDA libraries, and it is easily deployed in a way imperceptible to the application.
High performance: Virtualization is applied at the underlying layer of GPU devices, realizing efficient convergence and nearly zero loss of throughput.