创建任务
Download
聚焦模式
字号
创建步骤
填写基本信息
1. 登录TI-ONE 控制台,进入训练工坊 > 任务式建模,单击新建,开始创建训练任务。
2. 在基本信息配置页,填写如下信息:
任务名称:仅支持中英文、数字、下划线"_"、短横"-",只能以中英文、数字开头。
地域:训练任务所在的地域,默认为当前列表页所在的地域。
训练镜像:可选择平台内置训练镜像、自定义镜像和内置大模型,其中内置训练镜像请查看内置训练镜像列表;自定义镜像支持选择容器镜像服务的镜像或者填写外部镜像地址(若为私有镜像,需要输入用户名和密码),自定义镜像规范请查看自定义训练镜像规范。
训练模式:不同训练框架支持的训练模式请查看内置训练镜像列表。
计费模式:可选择按量计费和包年包月,若选择按量计费,则需要选择算力规格和节点数量;若选择包年包月,则需要先创建资源组,购买节点,相关操作请查看 资源组管理,选择完资源组后选择对应的计算资源。平台支持的计费规格请查看计费概述。
说明:
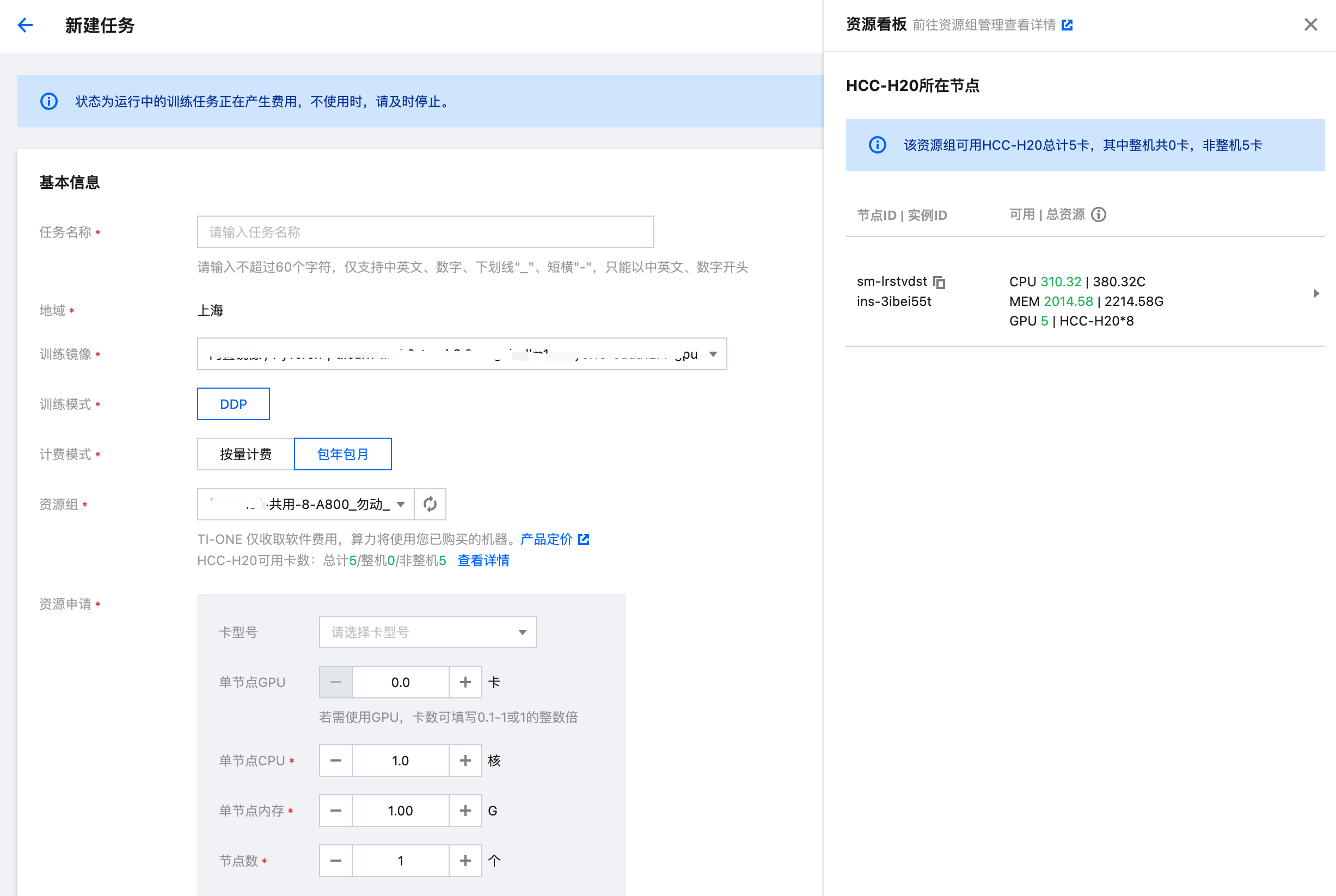
1. 选择资源组后会立即展示该资源组所剩的 GPU 概览信息,包括各卡型号的 GPU 总卡数,整机卡数和非整机卡数(碎卡数),可帮助用户快速了解选中资源组的 GPU 分布情况,根据当前任务场景选择使用整机资源还是非整机(碎卡)资源,可有效降低整体资源的碎片化情况,提升 GPU 总体利用率。
2. 点击 查看详情 即会在当前页面右侧展示详细资源看板,看板中展示了各个卡类型的节点剩余可用和总资源;点击下拉后可展示当前节点正在运行的所有任务/服务,可帮助用户快速了解节点资源的占用情况,以便团队间进行资源使用协商。
标签:可为任务创建标签,一个任务可添加多个标签。
描述:可添加最多500字的备注描述。
CLS 日志投递:CLS 日志投递默认关闭,TI 控制台会默认展示 15 天的日志,若您期望持久化存储日志,获得日志检索等服务,可以开启 CLS 日志投递,打开 CLS 后可以将日志投递至 CLS 服务(需要确保 CLS 服务已完成开通),CLS 产品介绍和收费指南请查看 CLS 介绍。
自动重启:您可以对任务配置自动重启策略,您需要配置最大重启次数,最高为10次,超过最大重启次数后,会将任务直接标记为异常;当前任务自动重启的触发条件为任务运行过程中发生异常退出(当前该功能仅支持计费模式为包年包月且训练模式为 MPI、DDP 和 Horovod 的训练任务)。任务自动重启的事件信息可在 任务详情 > 事件 页面中查看。
填写任务配置信息
任务配置页面需要配置本次训练任务的算法、数据、输入输出等信息,具体配置项说明如下:
1. 存储路径设置:存储类型支持COS、CFS(包含 CFS Turbo 类型)和 EMR(HDFS):
若选择 COS,则需要选择数据集所在的 COS 路径;
若选择 CFS、EMR(HDFS) ,则需要下拉选择 CFS 文件系统、EMR 集群,同时填写需要平台挂载的数据源目录;
以上几种数据来源在配置的时候均可定义数据在训练容器内的挂载路径,您的代码中需要填写该路径以获取数据。创建任务时可选择多个数据路径,分别设置不同的容器挂载路径,挂载到容器中,供训练算法读取。
使用 EMR(HDFS) 注意事项:平台默认使用 Hadoop 身份访问挂载 HDFS;如果需要使用其他身份,请按照如下代码包规范上传相关配置文件。
用户名和 keytab 文件统一由用户提供,放在代码包里面。
代码包规范:
/
<emr_id>/username.txt(内容为用户名,内容如: “hadoop/172.0.1.5”,当未开启 kerberos 认证时,文件不存在或者文件为空时可以使用默认的用户名“hadoop”;开启了 kerberos 认证后,默认用户名不可用)
/<emr_id>/emr.keytab (内容为 keytab 认证文件)
(因为平台同时支持多个 emr 的多个认证,所以需要添加 <emr_id> 到目录中,值如:emr-1rnhggsh)2. 代码包:您可以选择 COS 中的文件路径作为代码包目录,也可以不填此选项,读取存储路径设置中挂载的路径作为代码包路径;代码包可先上传至 COS 存储桶中,也可以直接在 TI-ONE 的 COS 文件选择对话框中点击上传。
3. 启动命令:您需要填写程序入口命令,支持填写多行,默认工作目录为/opt/ml/code。
4. 调优参数:填写的超参数 JSON 会保存为 /opt/ml/input/config/hyperparameters.json 文件,您的代码需自行解析。
5. 训练输出:选择您需要保存训练输出的 COS 路径,平台会默认将 /opt/ml/output 路径下的数据定期上传至输出 COS 路径;若您需要将训练输出的模型一键发布至模型仓库,则需要将模型输出保存至 /opt/ml/model 路径下,平台会在训练结束后将该路径下的数据上传至 COS 路径;若您选择的是 CFS 等文件系统作为训练存储,您也可以不配置训练输出,直接将训练输出写到挂载的 CFS 文件路径中。
另外,在您配置任务的过程中,底部会实时显示您当前任务配置的价格,请注意关注。所有信息配置完成后,即完成了任务创建。
内置大模型预置流程说明
任务式建模内置了多种大模型精调模板,您可以直接一键启动内置大模型精调任务。以下是内置字段说明:
预置存储路径设置
第一行 “平台 CFS”:系统默认为您配置了精调该大模型的配套训练代码。
第二行 “平台 CFS”:系统默认为您配置了一份精调该大模型的示例数据;若您希望使用自定义业务数据精调该大模型,可删除此行,并在底部添加其他存储来源。
第三行 “平台 CFS”:系统默认为您配置了平台内置模型。
第四行 “用户 CFS”:此处需选择您的 CFS 文件系统和源路径,“容器挂载路径”为系统默认填充您无需修改。若您需要使用 其他CFS文件系统 作为训练输出,则您可以删除本行再添加。

预置启动命令
平台默认填充了启动命令,一般情况下您无需修改。
预置调优参数
平台提供多个预置参数,您可以直接修改超参 json 迭代模型。以下是超参释义:
超参 | 默认值 | 解释 |
Epoch | 2 | 训练过程中的迭代轮次 |
BatchSize | 1 | 每轮训练迭代中的样本数。BatchSize 越大,训练速度越快同时内存占用越高 |
LearningRate | 1e-5 | 梯度下降过程中更新权重的超参,过高导致模型难以收敛,过低导致模型收敛速度过慢 |
Step | 750 | 每跑多少个Step保存一次模型的checkpoint,保存checkpoint越多需要的存储空间越大 |
UseTilearn | true | 是否要开启腾讯自研加速,"true/false",设置为"true"会默认启用腾讯自研加速框架训练,其中3d并行加速需8卡以上,需要进行PP和TP参数设置,可参考angel-tilearn文档;设置为"false"会默认使用开源加速框架进行训练。仅部分模型开放 |
FinetuningType | Lora | 用户可自定义选择精调训练模式“Lora/Full”,LoRA 在固定预训练大模型本身参数的基础上,对权重矩阵进行低秩分解,训练过程中只更新低秩部分参数;FULL 在精调过程中会全量更新模型参数,需要的训练资源更多 |
MaxSequenceLength | 2048 | 最大文本序列长度,可根据您的业务数据长度进行合理设置。例如,如果大部分业务数据长度都在2048以下,则可设置 MaxSequenceLength 为 2048,大于2048的数据都会被截断为2048,可降低 GPU 显存压力 |
GradienAccumulationSteps | 1 | huggingface trainer参数,默认为1,提升batchsize |
GradientCheckPointing | True | huggingface trainer参数,默认True,时间换显存的策略,开启后优化显存但训练速度变慢 |
DeepspeedZeroStage | z3 | DeepSpeed ZeRO 阶段配置,可选值["z0", "z2", "z2_offload", "z3", "z3_offload"],默认值z3;仅部分模型开放 |
ResumeFromCheckpoint | Ture | 是否自动从已有的 checkpoint 文件恢复训练,默认值为 True,表示若输出目录存在 checkpoint 文件,从最新的 checkpoint 恢复继续训练;设置为 False 表示将重新训练。设置为 False 且输出目录非空,则会报错,建议训练输出路径使用空目录,若需要开启强制覆盖需要手动增加一条"overwrite_output_dir": true 参数开启覆盖文件 |
TilearnHybridTPSize | 1 | Tilearn 3D 并行参数,TP并行的维度,默认为1;仅部分模型开放 |
TilearnHybridPPSize | 1 | Tilearn 3D 并行参数,PP并行的维度,默认为1;仅部分模型开放 |
文档反馈