自动评测:裁判模型打分 Prompt 和前后处理格式要求
Download
聚焦模式
字号
自动评测提供裁判模型打分的功能,通过裁判模型进行自动打分,大幅提高打分效率,减少人工打分的成本。
裁判模型打分功能提供向导式、可自定义评测流程和配置的方式来进行打分,可直接基于平台内置的打分节点“前处理、裁判模型、后处理”自定义串起评测流程,全程支持用户高度自定义打分 Prompt 和前后处理脚本,以获取对评测集最好的打分效果,其打分节点定义如下:
裁判模型:通过 AI 模型打分的方式,对评测集进行评测。其核心功能为支持用户选择 TI 在线服务或者输入 API 调用后打分。
打分 Prompt:通过自定义输入方式,为评测集量身定制合适的打分规则,规则主要包含裁判模型的系统定义、打分标准、以及需要把问题、参考答案、待评测模型的输出组合成字符串最终输入给裁判模型。为了获得更好的打分效果,允许用户为每个裁判模型自定义打分 Prompt,需通过 Jinja2 模板语法动态构造裁判模型的输入内容。
为了获取更好的评测结果,某些情况需要在裁判模型打分前后对数据做处理,平台支持输入 Python 脚本进行数据处理。处理包含两种,分别为前处理、后处理:
前处理:通常用来对原始数据集、被测模型的输出(Response)进行处理,作为最终的打分对象输入给裁判模型。
后处理:通常用来对裁判模型的输出进行数据处理,以得到最终的打分结果。
以下分别对裁判模型的打分 Prompt 和前后处理格式进行说明。
一、裁判模型打分模板使用规范
打分 Prompt 用来定义裁判模型的输入,包含裁判模型的系统定义、打分标准、以及需要把问题、参考答案、待评测模型的输出组合成字符串最终输入给裁判模型。用户需要通过 Jinja2 模板语法动态构造裁判模型的输入内容。
说明:
什么是 Jinja2?
Jinja2 是一种功能强大且灵活的模板引擎,支持变量插值、控制语句、过滤器等语法,广泛用于生成动态文本内容。
在裁判模型评测中,我们使用 Jinja2 模板来动态构造裁判模型看到的“问题与待评测模型回复” ,使裁判模型能基于清晰、标准化的上下文做出评价。
用户在编辑 prompt 时,可以应用被测模型 response 与评测数据集 data 中的相应字段内容,此外,平台默认会使用用户数据集,预定义变量供用户编辑引用。
1. 字段定义和变量说明
预定义变量说明
平台默认预定义以下3个核心变量,用于快速获取对话中的关键信息,用户可直接在模板中引用。
变量名 | 定义方式 | 数据来源 | 默认值 |
data.question | 最后一条 role 为 user 的 content | 从数据集的一条完整对话记录(data.messages)中提取最后一个role: "user"的消息内容。 | None |
data.gt | 最后一条消息且 role 为 assistant 的 content | 从数据集的一条完整对话记录(data.messages)中提取最后一个role: "assistant"的消息内容。 | 最后一条 role 不为 assistant,默认为 None |
data.history | 对话历史(去除 question 和 gt 的剩余消息) | 从 data.messages 中过滤掉最后一个 user 和 assistant 消息后,剩余消息按顺序拼接的文本。 | 若为单轮对话,默认为 None |
说明:
所有变量均来自于对评测集的部分引用,示例如下:
{
"messages": [
{"role": "user", "content": "北京的气候如何?"},
{"role": "assistant", "content": "北京属于温带季风气候..."}, // 上述内容组成data.history
{"role": "user", "content": "那夏季呢?"}, // 最后一条user消息 → data.question
{"role": "assistant", "content": "夏季高温多雨..."} // 最后一条assistant消息 → data.gt
],
"ref_answer": "北京夏季气候特征为高温多雨,..." // 可选字段
}
其他可用字段说明
除预定义变量外,用户可根据任务需求引用评测集中的自定义字段 (注意:需确保字段在评测集数据 data 或被测模型的 response 中存在)。以下为常见可用字段:
字段名 | 定义与用途 |
data.ref_answer | 参考答案,对应于原数据中的 ref_answer 字段(如果原数据中不包含则返回 None) |
response.content | 被测模型的实际响应内容 |
data.其他用户定义的字段 | 评测数据的用户定义的数据字段都可以引用 |
response.其他被测模型返回的字段 | 被测模型返回的其他字段都可以被引用,常见的例如 response.reasoning_content、response.tool_calls |
2. 打分 Prompt 拼接内容示例
说明:
在使用裁判模型进行评测时,裁判模型的输入必须是结构化的、清晰的字符串,包含系统定义、打分标准、以及需要把问题、参考答案、待评测模型的输出组合成字符串。由于评测集中有多条数据,每一条问题、参考答案、待评测模型的输出是动态变化的,因此需要将以上内容拼接为裁判模型的 prompt。Jinja 允许用户在一段文本(即打分 prompt )中定义占位符(变量),然后通过传入一个上下文字典,将这些变量替换为真实的值,从而动态生成最终输入给裁判模型的打分 prompt。
结合预定义变量与自定义字段,以下给出几种不同任务类型的模板示例。
示例1:单轮问答模板拼接示例
原始数据样例
"data": {"messages": [{"role": "user", "content": "牛顿第一定律的核心内容是什么?"},{"role": "assistant", "content": "任何物体都要保持匀速直线运动或静止状态,直到外力迫使它改变这种状态为止"}]}
待评测模型回答样例
"response": {"content": "牛顿第一定律表明:如果没有外力作用,物体将保持静止或匀速直线运动。","reasoning_content": "用户提问的是牛顿第一定律,我首先需要确定是什么学科..."}
打分 Prompt 和拼接效果
请以公正的评判者身份,评估下方所展示的 AI 助手针对用户提问所给出的回答质量。你将获得当前的用户提问、一个参考答案以及助手的回答内容。
在评估助手的回答时,你首先需要将其与参考答案进行对比,指出助手回答中存在的任何错误或信息不准确之处。
接着,考虑助手的回答是否具备帮助性、相关性和简洁性。
有帮助(Helpful):指回答正确回应了用户的问题或遵循了提问要求。若用户提问存在歧义或可能有多种理解方式,则更有帮助且恰当的做法是向用户询问澄清或更多信息,而非基于假设直接作答。
相关(Relevant):指回答的每一部分都与所提问题紧密相关或恰当对应。
简洁(Concise):指回答清晰明了,不冗长、不啰嗦或包含不必要的信息。
然后,根据需要,也可考虑助手回答中的创造性与新颖性。最后,识别助手回答中缺失的、但对回应用户提问有帮助的重要信息,尤其是那些在参考答案中出现的内容。
你的评估应综合考虑以下因素,与参考答案相比,判断助手回答在正确性、有用性、相关性、准确性、深度、创造性与细节丰富程度等方面的表现。
请先提供一份详细的评估说明,重点分析助手的回答与参考答案的相符程度,或是否在某些方面优于参考答案。尽可能保持客观。
在完成说明之后,请按照以下严格格式,以1到10分为助手的回答进行评分:
“评分:[[分数]]”,例如:“评分:[[5]]”。
【用户提问】
{{ data.question }}
【参考答案】
{{ data.gt }}
【助手回答】
{{ response.content }}
【模型推理过程】
{{ response.reasoning_content }}
请以公正的评判者身份,评估下方所展示的 AI 助手针对用户提问所给出的回答质量。你将获得当前的用户提问、一个参考答案以及助手的回答与思考过程内容。
在评估助手的回答时,你首先需要将其与参考答案进行对比,指出助手回答中存在的任何错误或信息不准确之处。
接着,考虑助手的回答是否具备帮助性、相关性和简洁性。
有帮助(Helpful):指回答正确回应了用户的问题或遵循了提问要求。若用户提问存在歧义或可能有多种理解方式,则更有帮助且恰当的做法是向用户询问澄清或更多信息,而非基于假设直接作答。
相关(Relevant):指回答的每一部分都与所提问题紧密相关或恰当对应。
简洁(Concise):指回答清晰明了,不冗长、不啰嗦或包含不必要的信息。
然后,根据需要,也可考虑助手回答中的创造性与新颖性。最后,识别助手回答中缺失的、但对回应用户提问有帮助的重要信息,尤其是那些在参考答案中出现的内容。
你的评估应综合考虑以下因素,与参考答案相比,判断助手回答在正确性、有用性、相关性、准确性、深度、创造性与细节丰富程度等方面的表现。
请先提供一份详细的评估说明,重点分析助手的回答与参考答案的相符程度,或是否在某些方面优于参考答案。尽可能保持客观。
在完成说明之后,请按照以下严格格式,以1到10分为助手的回答进行评分:
“评分:[[分数]]”,例如:“评分:[[5]]”。
【用户提问】
牛顿第一定律的核心内容是什么?
【参考答案】
任何物体都要保持匀速直线运动或静止状态,直到外力迫使它改变这种状态为止
【助手回答】
牛顿第一定律表明:如果没有外力作用,物体将保持静止或匀速直线运动。
【模型推理过程】
用户提问的是牛顿第一定律,我首先需要确定是什么学科...
示例2:多轮问答模板拼接示例
原始数据样例
"data": {"messages": [{"role": "system", "content": "你是由A公司研发的智能助手,能够精准回答用户问题。"},{"role": "user", "content": "你好,可以帮我解释一下广义相对论吗?"},{"role": "assistant", "content": "广义相对论是爱因斯坦提出的,引入了引力场与时空弯曲的关系。"},{"role": "user", "content": "那狭义相对论又是什么呢?"},{"role": "assistant", "content": "当物体运动速度接近光速时,时间、空间、质量与能量都将展现出与日常经验完全不同的规律,而光速是宇宙中一切物体速度的极限。"}]}
待评测模型回答样例
"response": {"content": "狭义相对论主要研究惯性系中的运动规律,包括时间膨胀和长度收缩。","reasoning_content": "用户问的是狭义相对论,应该说明核心内容。常见表述是:高速运动下的时空性质,如时间膨胀和长度收缩。"}
打分 Prompt 和拼接效果
请以公正的评判者身份,评估下方所展示的 AI 助手针对用户提问所给出的回答质量。你将获得助手与用户之间的对话历史记录、当前的用户提问、一个参考答案以及助手的回答内容。
在评估助手的回答时,你首先需要将其与参考答案进行对比,指出助手回答中存在的任何错误或信息不准确之处。同时,请注意助手的回答是否与对话历史中提供的信息保持一致,以及其与参考答案的契合程度如何。
接着,评估助手的回答是否具备帮助性、相关性和简洁性:
有帮助(Helpful):指回答正确回应了用户当前的提问或遵循了提问要求,同时能够结合对话上下文(如适用)给出恰当回复。如果用户提问存在歧义或可能有多种理解方式,则更有帮助且恰当的做法是向用户询问澄清或请求更多信息,而不是基于假设直接给出答案。
相关(Relevant):指回答的每一部分都紧密联系或恰当地回应了所提问题,既考虑当前问题本身,也兼顾对话历史中的相关背景信息。
简洁(Concise):指回答清晰明了,不冗长、不啰嗦,也没有包含不必要的信息。
此外,根据需要,也可考虑助手回答中的创造性与新颖性。最后,识别助手回答中缺失的、但对回应用户提问有帮助的重要信息,尤其是那些出现在参考答案中,或对话历史中本应被引用但未被提及的内容。
你的评估应综合考量以下因素,与参考答案相比,判断助手回答在正确性、有用性、相关性、准确性、深度、创造性与细节丰富程度等方面的表现。
请先提供一份详细的评估说明,重点分析助手的回答与参考答案的相符程度,或是否在某些方面优于参考答案。请尽可能保持客观。
在完成详细说明后,请按照以下严格格式,以1到10分为助手的回答进行评分:
“评分:[[分数]]”,例如:“评分:[[5]]” 或 “评分:[[8]]”。
【对话历史】
{{ data.history }}
【用户问题】
{{ data.question }}
【参考答案】
{{ data.gt }}
【助手回答】
{{ response.content }}
请以公正的评判者身份,评估下方所展示的 AI 助手针对用户提问所给出的回答质量。你将获得助手与用户之间的对话历史记录、当前的用户提问、一个参考答案以及助手的回答内容。
在评估助手的回答时,你首先需要将其与参考答案进行对比,指出助手回答中存在的任何错误或信息不准确之处。同时,请注意助手的回答是否与对话历史中提供的信息保持一致,以及其与参考答案的契合程度如何。
接着,评估助手的回答是否具备帮助性、相关性和简洁性:
有帮助(Helpful):指回答正确回应了用户当前的提问或遵循了提问要求,同时能够结合对话上下文(如适用)给出恰当回复。如果用户提问存在歧义或可能有多种理解方式,则更有帮助且恰当的做法是向用户询问澄清或请求更多信息,而不是基于假设直接给出答案。
相关(Relevant):指回答的每一部分都紧密联系或恰当地回应了所提问题,既考虑当前问题本身,也兼顾对话历史中的相关背景信息。
简洁(Concise):指回答清晰明了,不冗长、不啰嗦,也没有包含不必要的信息。
此外,根据需要,也可考虑助手回答中的创造性与新颖性。最后,识别助手回答中缺失的、但对回应用户提问有帮助的重要信息,尤其是那些出现在参考答案中,或对话历史中本应被引用但未被提及的内容。
你的评估应综合考量以下因素,与参考答案相比,判断助手回答在正确性、有用性、相关性、准确性、深度、创造性与细节丰富程度等方面的表现。
请先提供一份详细的评估说明,重点分析助手的回答与参考答案的相符程度,或是否在某些方面优于参考答案。请尽可能保持客观。
在完成详细说明后,请按照以下严格格式,以1到10分为助手的回答进行评分:
“评分:[[分数]]”,例如:“评分:[[5]]” 或 “评分:[[8]]”。
【对话历史】
[SYSTEM] 你是由A公司研发的智能助手,能够精准回答用户问题。
[USER] 你好,可以帮我解释一下广义相对论吗?
[BOT] 广义相对论是爱因斯坦提出的,引入了引力场与时空弯曲的关系。
【用户问题】
那狭义相对论又是什么呢?
【参考答案】
当物体运动速度接近光速时,时间、空间、质量与能量都将展现出与日常经验完全不同的规律,而光速是宇宙中一切物体速度的极限。
【助手回答】
狭义相对论主要研究惯性系中的运动规律,包括时间膨胀和长度收缩。
二、前后处理脚本书写规范
当您需要自定义评测数据的预处理(Preprocess)或模型输出 Response 的后处理(Postprocess)逻辑时,您需要提供一个符合以下规范的 Python 脚本。评测系统将以模块形式导入并执行您脚本中约定的函数。
1. 函数命名与接口约定
前处理、后处理脚本中必须分别包含以下两个函数:preprocess 和 postprocess。评测模块将根据此名称调用预处理函数。
2. 前处理函数
预处理函数通常用来对原始数据集、被测模型的 Response 进行处理,以构建最终输入给模型的 Prompt,您需要实现此函数。
函数名:preprocess
功能: 对被测模型的 Response 或者原始数据集进行处理,最终返回一个用于后续评测模块使用的值,或者不返回任何值。
入参:data, resp, **kwargs
出参:处理结果,作为当前处理节点的 Result【展示在处理结果中】
数据结构内容:用户可为结构体自定义添加新字段,以便后续通过字典的方式引用。
data【dict 类型】: 根据评测集的内容自动解析,包含 messages 字段,为 OpenAI 的对话格式,若根据评测格式制作数据,其他任意字段都会被包含在该结构体中,例如:ref_answer 字段。
字段名 | 是否包含 | 字段说明 | 字段示例 |
messages | 是 | OpenAI对话格式 | "messages": [{"role": "user", "content": "你好"}, {"role": "assistant", "content": "你好,有什么可以帮助你"}, {"role": "user", "content": "12+12等于几"},{"role": "assistant", "content": "24"}] |
ref_answer | 通过用户数据集解析,原数据集中不存在该字段则为 None | 参考答案 | "答案等于24" |
gt | 若 messages 中最后一条数据 role 为 assistant,则取其 content 作为本字段 | 标准答案 | "24" |
question | 解析 messages 字段最后一个 role 为 user的 content 内容作为本字段 | 用户提问问题 | "12+12等于几" |
history | 剔除 messages 中的 gt 与 question 字段的剩余内容,根据平台 jinja 模板版渲染为字符串 | 用户提问历史消息 | "[USER] 你好 [BOT] 你好,有什么可以帮助你" |
其他字段 | 用户数据中的其他字段;用户也可在处理脚本中添加 | 自定义字段 | str | int | float | dict 等可JSON序列化的内容 |
Response【dict 类型】: 解析后的大语言模型响应的结果,包含 content 字段,若推理框架支持 separate_reasoning,则包含 reasoning_content 字段,其他可能的字段包括 tool_calls。
字段名 | 是否包含 | 字段说明 | 字段示例 |
content | 是 | 大语言模型推理结果 | "答案等于24" |
reasoning_content | 如果推理框架支持思维链分开展示并返回,则包含;否则为None | 大语言模型推理思维链 CoT 内容 | "嗯,用户问的是“12+12等于几”,这个问题看起来很基础,但作为刚开始学习数学的人可能需要详细解释..." |
tool_calls | 若执行工具调用并返回本字段,则包含;否则为None | 大语言模型工具调用内容 | [{"id":"call_id","type":"function","function":{"name":"get_current_weather","arguments":"{\\"location\\": \\"San Francisco, USA\\", \\"format\\": \\"celsius\\"}"}}] |
其他字段 | 模型返回的其他字段;用户也可在处理脚本中添加 | 自定义字段 | str | int | float | dict 等可 JSON 序列化的内容 |
函数签名:
def preprocess(data: dict, resp: dict, **kwargs) -> bool | int | str | float | None:""":data: Dict,一个字典,包含以下关键信息:- 'messages': 多轮对话历史。- 'ref_answer': (可选) 参考答案。- 以及用户自定义的所有其他字段:resp: Dict, 大模型推理结果,包含以下内容:- content: 模型生成的回答内容- reasoning_content: 模型生成回答的推理过程(如果有)- tool_calls: 模型调用的工具列表(如果有)- 以及用户自定义的所有其他字段:**kwargs: 平台扩展字段,预处理可不提供:return: 预处理结果,可用于裁判模型评测jinja模版引用"""# --- 在此实现您的逻辑 ---pass
注意:
1、前处理函数必须包含 data, resp,**kwargs 字段,**kwargs 后续用于平台扩展更多可操作数据项。
2、data,resp 支持通过字典/对象的方式进行访问或增加字段。
3、为避免因意外数据格式导致整个评测流程中断,建议在脚本中加入基础的异常捕获。
def preprocess(data: dict, resp: dict) -> bool | int | str | float | None:try:# 你的处理逻辑except Exception as e:print(f"[预处理脚本出错]:{e}")return 1 # 根据需求返回默认值
使用示例:
示例1: 判断模型是否包含思维链
def preprocess(data: dict, resp: dict) -> bool:# 判断模型回复是否包含 reasoning_contentreturn resp['reasoning_content'] == ''
示例2: 去除 content 中的思维链
import redefault_cot_pairs = [('<think>', '</think>'), ('<Think>', '</Think>')]def remove_cot(text: str, cot_pairs=None) -> str:if cot_pairs is None:cot_pairs = default_cot_pairsret = textfor t0, t1 in cot_pairs:ret = re.sub(f"{t0}.*?{t1}", '', ret, flags=re.DOTALL)return ret.strip()def preprocess(data: dict, resp: dict) -> bool | int | str | float | None:field = 'clean'resp[field] = remove_cot(resp['content'])return resp[field]
仅做数据处理,不返回任何值
def preprocess(data: dict, resp: dict) -> None:# 例如:将模型回复内容添加到 data 中if resp['content']:data['resp'] = resp['content']# 不影响评测判断,返回 Nonereturn None
3. 后处理函数
后处理函数通常用来对裁判模型的输出进行后处理,以得到最终的打分结果。
函数名:preprocess
功能: 对裁判模型的 Response 进行处理
入参:【必须】:judge_reqs,judge_resps,judge_models,data,resp,**kwargs
出参:处理结果,作为当前处理节点的 Result【展示在处理结果中】
数据结构内容:用户可为结构体自定义添加新字段,以便后续通过字典的方式引用。
judge_reqs【list[dict] 类型】: 根据评测指标配置中的裁判模型处理顺序,依次添加裁判模型的推理请求为一个列表;列表中的每一项,通过解析用户 prompt模板以及推理超参配置等生成,默认包含 messages 字段并开启 stream,separate_reasoning 字段。
字段名 | 是否包含 | 字段说明 | 字段示例 |
messages | 是 | OpenAI 对话格式 | [{"role": "system", "content": "You are a helpful assistant. 0827-adjustment" },{"role": "user","content": "你是一个裁判员,请对回答进行打分。\\n\\n\\n[历史信息和问题]\\n\\n<|im_start|>user\\n你好<|im_end|>\\n\\n\\n<|im_start|>assistant\\n你好,有什么可以帮助你<|im_end|>\\n\\n\\n<|im_start|>user\\n18+18等于几<|im_end|>\\n\\n\\n\\n[待评测模型的回答]\\n{'content': '18 + 18 = 36'}\\n\\n[参考答案]\\n答案等于24\\n\\n\\n请给出你的打分,最高分5,最低分1。"}] |
其他字段 | 模型返回的其他字段;用户也可在处理脚本中添加 | 自定义字段 | str | int | float | dict 等可JSON序列化的内容 |
judge_models【list[dict] 类型】: 列表的每一项内容为裁判模型的基本配置,其根据评测指标配置中的裁判模型处理顺序,依次加入。
字段名 | 是否包含 | 字段说明 | 字段示例 |
name | 是 | 裁判模型名称 | "deepseek" |
judge_template_content | 是 | 裁判模型打分模板 | """裁判员的打分模板,例如: 你是一个裁判员,请对回答进行打分。[历史信息和问题] {% for message in data.messages %} {{'<|im_start|>' + message['role'] + '\\n' + message['content'] + '<|im_end|>' + '\\n'}} {% endfor %} [待评测模型的回答] {{ response.content }} [参考答案] {{ data.ref_answer }} 请给出你的打分,最高分{{ max_score }},最低分{{ min_score }}。 """ |
generation_params | 不一定,根据用户配置解析 | 裁判模型推理参数 | {\\"temperature\\": 0.8, \\"top_p\\": 0.85} |
system_prompt | 不一定,根据用户配置解析 | 裁判模型推理system | "You are a helpful assistant. " |
data【dict 类型】: 同前处理的数据结构 data。
judge_resps【list[dict] 类型】: 列表的每一项内容同前处理的数据结构 resp,根据评测指标配置中的裁判模型处理顺序,依次添加裁判模型的推理结果为一个列表。
函数签名:
def postprocess(judge_reqs: list[dict],judge_resps: list[dict],judge_models: list[dict],data: dict,resp: dict,**kwargs,) -> bool | int | str | float | None:""":param judge_reqs, 裁判模型的打分请求数据。:param judge_resps, 裁判模型的推理结果。:param judge_models, 裁判模型的相关配置。:return: 进行自定义的后处理逻辑,并返回一个用于最终评测结果判断、展示或统计的值,其类型应为 bool | int | str | float | None,以便进行指标计算。"""# --- 在此实现您的逻辑 ---pass
注意:
后处理函数必须包含 judge_reqs,judge_resps,judge_models,data,resp,**kwargs 字段,**kwargs 后续用于平台扩展更多可操作数据项,默认注入了最后一个裁判模型节点的 judge_req,judge_resp,judge_model,可通过如下方式调用:
def postprocess(judge_reqs: list[dict],judge_resps: list[dict],judge_models: list[dict],data: dict,resp: dict,**kwargs,) -> bool | int | str | float | None:judge_req = kwargs.get('judge_req')judge_resp = kwargs.get('judge_resp')judge_model = kwargs.get('judge_model')
使用示例:
计算所有裁判打分的平均分
def postprocess(judge_reqs, judge_resps, judge_models, data, resp, **kwargs):scores = []for jr in judge_resps:try:# 假设裁判返回内容为 "该回答得分为4分" 或 "Score: 4"content = jr['content']score = int(content.strip().split(" ")[-2]) # 简单示例,请根据实际格式调整scores.append(score)except:continueif scores:return round(sum(scores) / len(scores), 2)return None
判断多数裁判是否认为回答正确
def postprocess(judge_reqs, judge_resps, judge_models, data, resp, **kwargs):positive_count = 0for jr in judge_resps:content = jr['content']if "good" in content or "correct" in content or "4" in content or "5" in content:positive_count += 1return positive_count > len(judge_resps) / 2 # 超过一半认为正确
仅做数据整理,返回 None
def postprocess(judge_reqs, judge_resps, judge_models, data, resp, **kwargs):# 可在此处做数据存储、结构转换等,但不影响最终评测return None
三、平台内置打分 Prompt 模板以及建议使用的后处理脚本
概述:为提高用户配置效率,平台内置单轮、多轮对话打分 prompt 模板,以及提供对应的后处理方式。
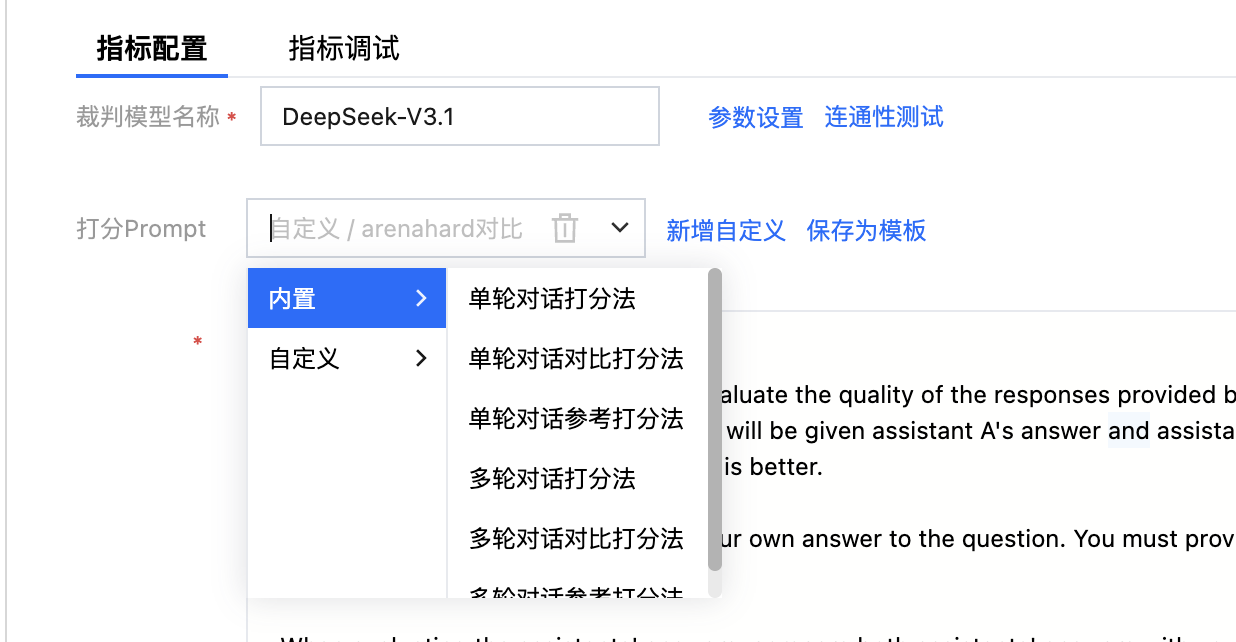
1. 单轮对话打分法
直接对待测模型的回复进行打分,最终评分范围为1到10。若不自定义后处理脚本,平台默认帮助用户进行后处理来解析出具体的评分作为最终结果。
2. 单轮对话对比打分法
根据原始问题,通过参考答案(数据集中的 ref_answer 字段,您也可修改为其他自定义字段)与待测模型的回复进行对比打分,裁判模型会输出 A 和 B 的好坏或者相等,后处理脚本将相应结果提取并映射到相应的分值。
以下为其对应的后处理脚本,供用户参考使用:
import refrom typing import Optionalans_map = {"A>>B": 1,"A>B": 2,"A=B": 3,"B>A": 4,"B>>A": 5,}def parse_last_comparison(text: str) -> Optional[str]:pattern = r"\\[\\[(A>>B|A>B|A=B|B>A|B>>A)\\]\\]"matches = re.findall(pattern, text)return matches[-1] if matches else Nonedef postprocess(judge_reqs: list[dict],judge_resps: list[dict],judge_models: list[dict],data: dict,resp: dict,**kwargs,) -> Optional[int]:last_comparison = parse_last_comparison(judge_resps[-1]['content'])return ans_map.get(last_comparison)
3. 单轮对话参考打分法
参考 ref_answer 字段对待测模型的回复进行打分,最终评分范围为1到10。若不自定义后处理脚本,平台默认帮助用户进行后处理来解析出具体的评分作为最终结果。
4. 多轮对话打分法
对待测模型的回复进行打分(适用于需要上下文的使用场景),最终评分范围为1到10,若不自定义后处理脚本,平台默认帮助用户进行后处理来解析出具体的评分作为最终结果。
5. 多轮对话对比打分法
对待测模型的回复进行打分(适用于需要上下文的使用场景),裁判模型会输出 A 和 B 的好坏或者相等,后处理脚本将相应结果提取并映射到相应的分值。
以下为其对应的后处理脚本,供用户参考使用:
import refrom typing import Optionalans_map = {"A>>B": 1,"A>B": 2,"A=B": 3,"B>A": 4,"B>>A": 5,}def parse_last_comparison(text: str) -> Optional[str]:pattern = r"\\[\\[(A>>B|A>B|A=B|B>A|B>>A)\\]\\]"matches = re.findall(pattern, text)return matches[-1] if matches else Nonedef postprocess(judge_reqs: list[dict],judge_resps: list[dict],judge_models: list[dict],data: dict,resp: dict,**kwargs,) -> Optional[int]:last_comparison = parse_last_comparison(judge_resps[-1]['content'])return ans_map.get(last_comparison)
6. 多轮对话参考打分法
参考 ref_answer 字段对待测模型的回复进行打分(适用于需要上下文的使用场景),最终评分范围为1到10,若不自定义后处理脚本,平台默认帮助用户进行后处理来解析出具体的评分作为最终结果。
文档反馈