模型优化使用
Download
聚焦模式
字号
模型优化是 TI-ONE 平台模型推理加速的模块,使用了 TI-ACC 的能力,可对模型仓库里纳管的模型进行推理优化加速,降本增效,目前限时免费,但模型优化后的模型仅能支持在 TI-ONE 平台模型服务进行推理服务使用。
优化任务列表
优化任务列表中可查看优化任务名、优化进度以及加速比等信息,并支持对优化后的模型进行保存到模型仓库等操作。优化进度会包含“启动中”、“加速中”、“加速完成”等状态,一般该过程需要持续几分钟的时间。

支持对优化中(启动中、加速中)的任务停止,单击停止按钮,此任务即被停止。
支持对加速完成的任务保存和发布,单击保存到模型仓库按钮,此优化任务得到的优化模型即保存到模型仓库优化模型列表页面。
支持对加速失败的任务重新加速,单击更多 > 重新加速按钮,可对该优化任务进行重新编辑和加速。
支持对优化任务删除,单击删除按钮,此任务即被删除。
支持对标签编辑,单击编辑标签按钮,可进行标签编辑。
新建优化任务
当前支持 TorchScript、MMDetection、Detectron2、Hugging Face-Stable Diffusion、ONNX、SavedModel、Frozen Graph 格式的模型,参考如下指引接入。
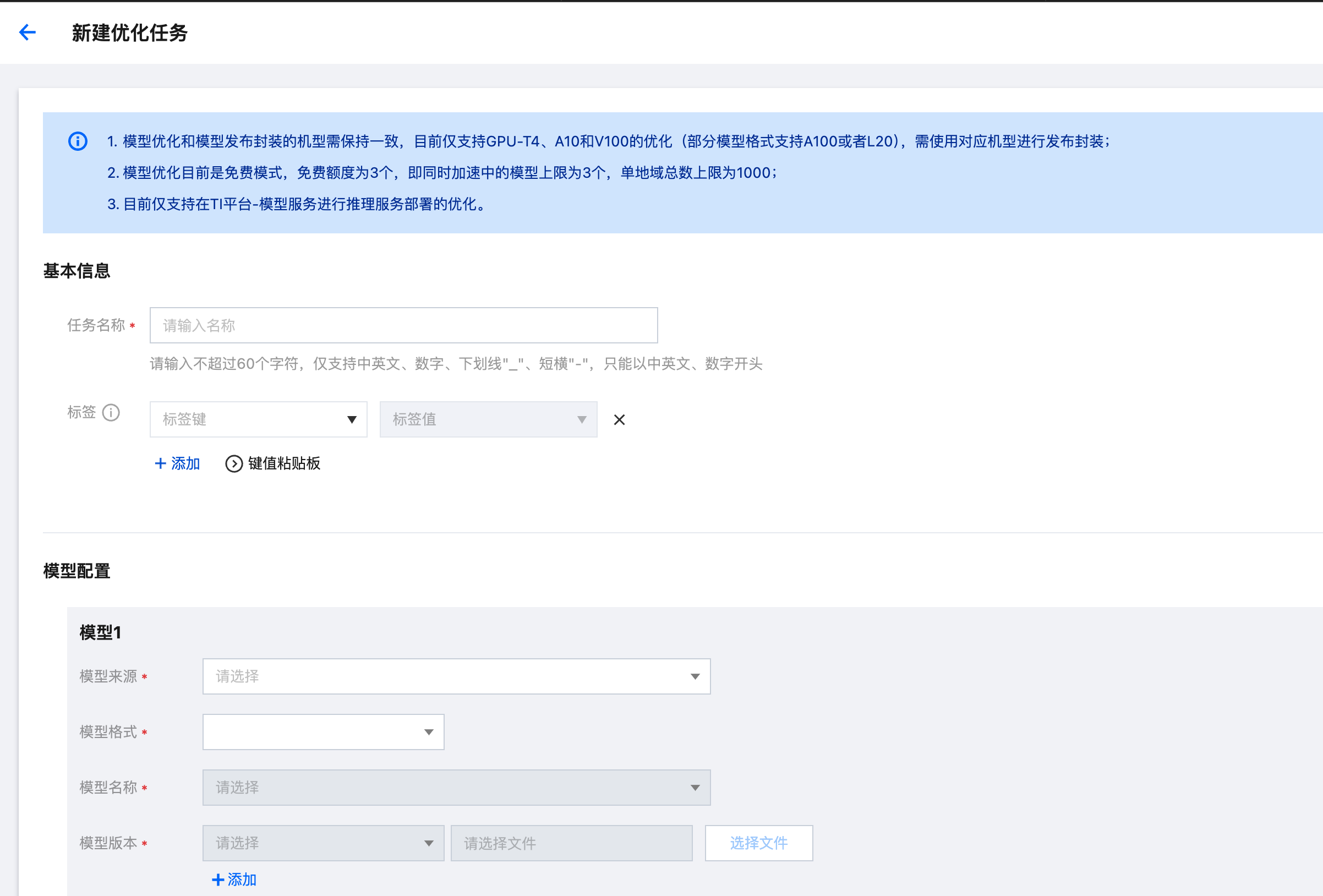
1. 输入任务名称,当仅优化一个模型及版本时,任务名称为客户填写的任务名称,当添加了多个模型或者版本时,会生成多个优化任务,每个任务的名称为客户填写的任务名称+“-模型名称”+“-模型版本”+“#”+序号;
2. 根据需要进行标签添加;
3. 选择模型来源 ,与模型仓库的模型来源字段一致,会在模型名称根据选择的模型来源筛选。
4. 选择模型名称 ,即待优化的模型,支持一个优化任务添加多个模型和版本,当添加了多个模型或者版本时,会生成多个优化任务,每个任务的名称为客户填写的任务名称+“-模型名称”+“-模型版本”+“#”+序号;
5. 选择模型版本 ,即待优化的模型版本,支持选择多个版本和对应的文件。
6. 选择模型文件,即待优化的具体模型文件,不同格式的模型文件后缀不同,请参考具体提示。
7. QAT模型,即量化感知训练。量化感知训练(QAT)是一种用于深度学习的技术,用于训练可 以量化的模型,以便部署在计算能力有限的硬件上。QAT 在训练过程中模拟量化,让模型在不损失精度的情况下适应更低的位宽。与量化预训练模型的训练后量化 (PTQ)不同,QAT 涉及在训练过程本身中量化模型。
说明:
QAT 过程可以分解为以下步骤:
1. 定义模型:定义一个浮点模型,就像常规模型一样。
2. 定义量化模型:定义一个与原始模型结构相同但增加了量化操作(如 torch.quantization.QuantStub)和反量化操作(如 torch.quantization.DeQuantStub))的量化模型。
3. 准备数据:准备训练数据并将其量化为适当的位宽。
4. 训练模型:在训练过程中,使用量化模型进行正向和反向传递,并在每个 epoch 或 batch 结束时使用反量化操作计算精度损失。
5. 重新量化:在训练过程中,使用反量化操作重新量化模型参数,并使用新的量化参数继续训练。
6. Fine-tuning:训练结束后,使用 fine-tuning 技术进一步提高模型的准确率。
8. 填写 “Tensor 信息” 字段:
将 输入数据 看作一个整体,需要在执行模型优化前,预先给出输入数据的形状信息,模型优化任务才能正常执行。
输入数据 是以多维张量(Tensor)作为基本元素(element)的列表(list)、字典(dict)、元组(tuple)及他们的嵌套组合。
对于输入数据中的各个 element,需分别给出他们的形状大小。对于每个 element,采用“element:dtype(shape)”的格式表示其形状大小,每个 element 占一行。
element 采用如下方式表示:
对于 输入数据 的第 1 层:
如果该层是 list 或 tuple,则每个元素用 input_0、input_1、... 来表示。(特别地,如果输入数据是单个 Tensor,则用 input_0 表示)
如果该层是 dict,则每个元素用 dict 的 key 来表示。
对于 输入数据 的第 n 层(n > 1):
如果该层是 list,则每个元素用 [0]、[1]、... 来表示。
如果该层是 tuple,则每个元素用 (0)、(1)、... 来表示。
如果该层是 dict,则每个元素用 [key] 来表示。
dtype 是对应 element 的基本数据类型,如 float、int32、array.char 等。
shape 是对应 element 的实际形状,有 3 种情况:
固定大小:用一个 size 值表示,其中 size 由n个以*分隔的正整数表示。如 “3*1024*1024”,表示 element 是一个大小为3乘1024乘1024的3维张量。
动态连续大小:用一个,(英文逗号)隔开的2个 size 值表示。如 “3*1024*2048,3*2048*2048”,表示 element 是一个大小可变的3维张量,其大小最小为3乘1024乘2048,最大为3乘2048乘2048。
动态离散大小:用一个 size 值列表表示。如“[3*1024*1024,3*2048*2048]”,表示 element 是一个大小可变的3维张量,其大小有2种可能,分别为 3乘1024乘1024 或 3乘2048乘2048。
下面给出若干填写实例:
eg.1 输入数据是单个 Tensor
Tensor 是固定大小,数据类型为 float,实际形状是1乘3乘1024乘1024。
“Tensor 信息” 字段共填写1行,填写 input_0:float(1*3*1024*1024)

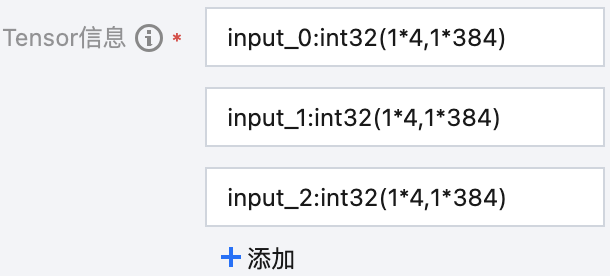
eg.2 输入数据是单层 list
共3个 element,3个 element 均为数据类型为 int32 的 Tensor,实际形状均为最小为1乘4、最大为1乘384的动态连续大小。
“Tensor 信息” 字段共填写3行,分别为input_0:int32(1*4,1*384)、input_1:int32(1*4,1*384)、input_2:int32(1*4,1*384)
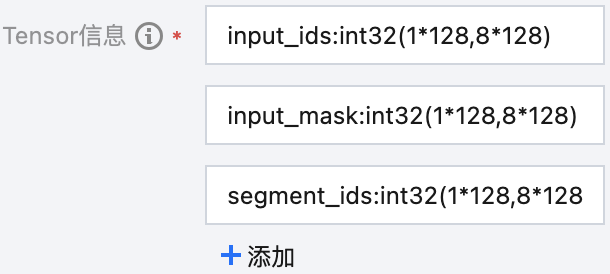
eg.3 输入数据是单层 dict
共3个 element,key分别为 input_ids、input_mask、segment_ids,value 均为数据类型为 int32 的 Tensor,实际形状均为最小为1乘128、最大为8乘128的动态连续大小。
“Tensor 信息” 字段共填写3行,分别为 input_ids:int32(1*128,8*128)、input_mask:int32(1*128,8*128)、segment_ids:int32(1*128,8*128)
9. 默认使用最新的加速库引擎版本即可,每个格式最新的加速库引擎版本会有不同;
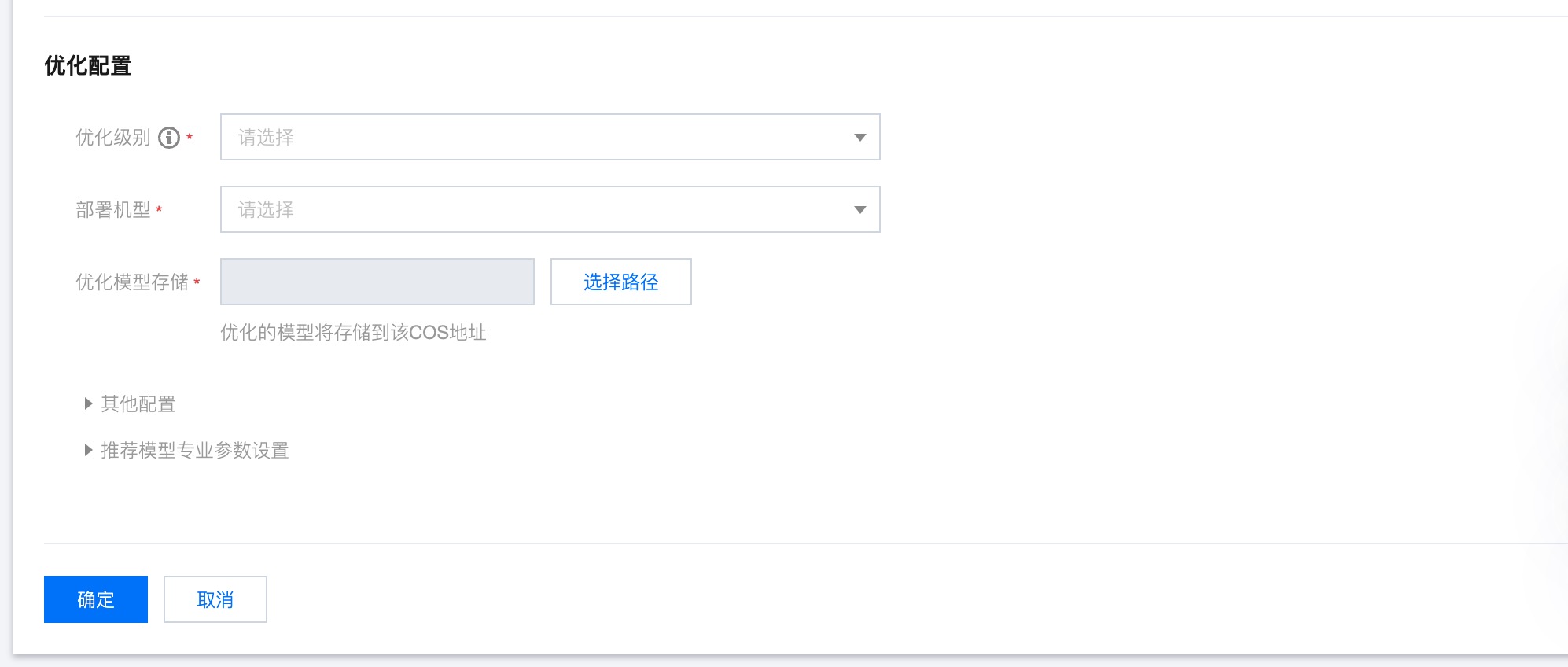
10. 优化级别可以选择 FP16 或无损 两种方式,无损代表使用模型原始精度优化,FP16 代表转为 FP16 精度进行优化,推荐使用 FP16 进行优化,推理速度比无损要高,并且一般不会造成精度下降。
11. 部署机型可以选择 T4 、V100 或 A10 三种机型(部分模型格式支持 A100 或者 PNV5b,当选择 PNV5b 的时候,需要选择资源组;当选择 T4 的时候,可以选择限时免费(按量)或者资源组,选择其他机型仅支持免费模式),优化时选的部署机型需要和实际部署服务的机型保持一致,即如果需要 T4 部署服务,则这里需要选择 T4 机型。
12. 单击选择路径,即选择优化后的模型要保存的位置,该位置和原始模型的主目录不能有重合,当对加速完成的模型单击保存到模型仓库时,会在该路径下将原始模型目录的所有文件复制,放在该路径下的新生成的 m-xxx/mv-xxx 文件夹里,并生成优化后模型 tiacc.pt,优化后的模型放到 model 文件夹下,如果想要对优化后的模型进行部署要符合 TI-ONE 平台的 模型包规范。
13. 单击确定 ,即开始优化任务,并返回到优化任务列表页。
优化任务详情
单击优化任务名称可进入优化任务详情页面,可以查看详细的任务信息和优化报告,并进行相应的操作。
文档反馈