动态发布记录(2026年)
函数开发
1. 登录 数据开发治理平台 WeData 控制台,进入函数开发页面。
2. 单击左侧菜单中的项目列表,找到需要操作函数开发功能的目标项目。
3. 选择项目后,单击进入数据开发模块。
4. 单击左侧菜单中的函数开发。
函数概览
资源管理功能中上传的 UDF 函数可以在函数开发中使用,通过函数分类、类名、标明用法后,即可在数据开发过程中使用。目前支持 Hive SQL、Spark SQL 与 DLC SQL 类型函数创建。
创建函数
1. 在函数开发页面,单击 


2. 在弹窗中配置函数,单击保存并提交后,即可完成函数注册。
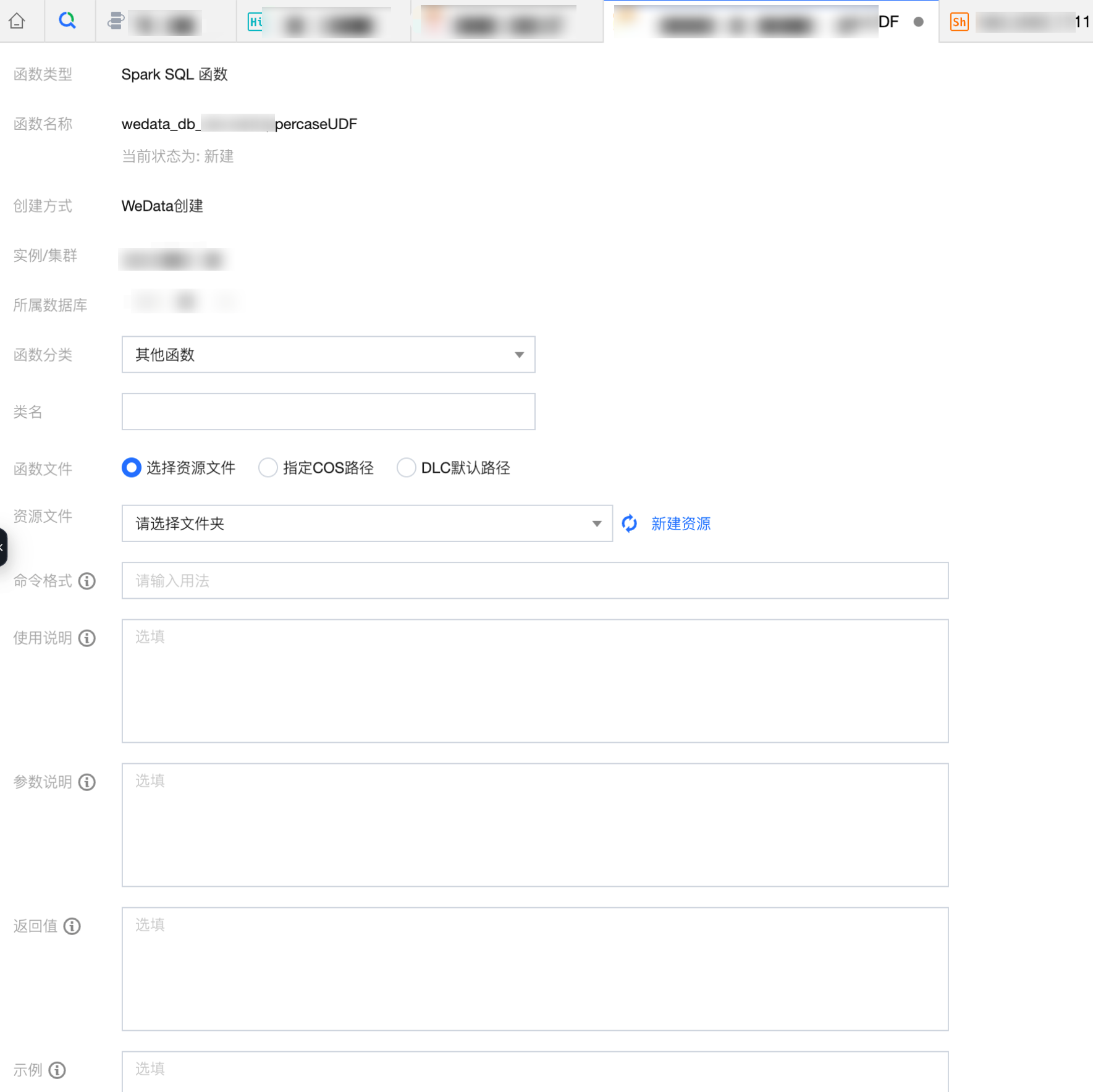
配置信息如下表所示:
信息 | 描述 |
函数分类 | 按照函数性质将其创建在预设的函数分类下,函数分类包括:分析函数、加密函数、聚合函数、逻辑函数、日期与时间函数、数学函数、转换函数、字符串函数、IP 与域名函数、窗口函数、其他函数。 |
类名 | 输入函数的类名。 |
函数文件 | 选择函数来源文件的地址: 选择资源文件:从资源管理功能上传的 jar 或 zip 资源中选择函数文件。 指定 COS 路径:从平台 COS 桶路径中获取函数文件。 |
资源文件 | 函数文件选项为选择资源文件,需要在资源管理目录中选定所需的函数文件。 |
COS 路径 | 函数文件选项为指定 COS 路径,需要输入平台 COS 桶内函数文件所在路径。 |
命令格式 | 格式为:函数名(入参)。如:sum 函数命令格式为 sum(col) |
使用说明 | 自定义函数的使用说明。如:sum函数使用说明为:计算汇总值。 |
参数说明 | 自定义函数的参数说明。如:sum函数参数说明为:col:必填。列值可以为 DOUBLE、DECIMAL 或 BIGINT 类型。如果输入为 STRING 类型,会隐式转换为 DOUBLE 类型后参与运算。 |
返回值 | 自定义函数的返回值说明。如:sum 函数返回值为:返回 DOUBLE 类型。 |
示例 | 自定义函数的示例说明。如:sum 函数示例为:计算所有商品销售(sales)总额,命令示例为:select sum(sales) from table。 |
3. 函数变更后可以通过版本功能保存下历史记录,包括版本号、提交人、提交时间、变更类型、备注,并且支持回滚历史版本的操作。
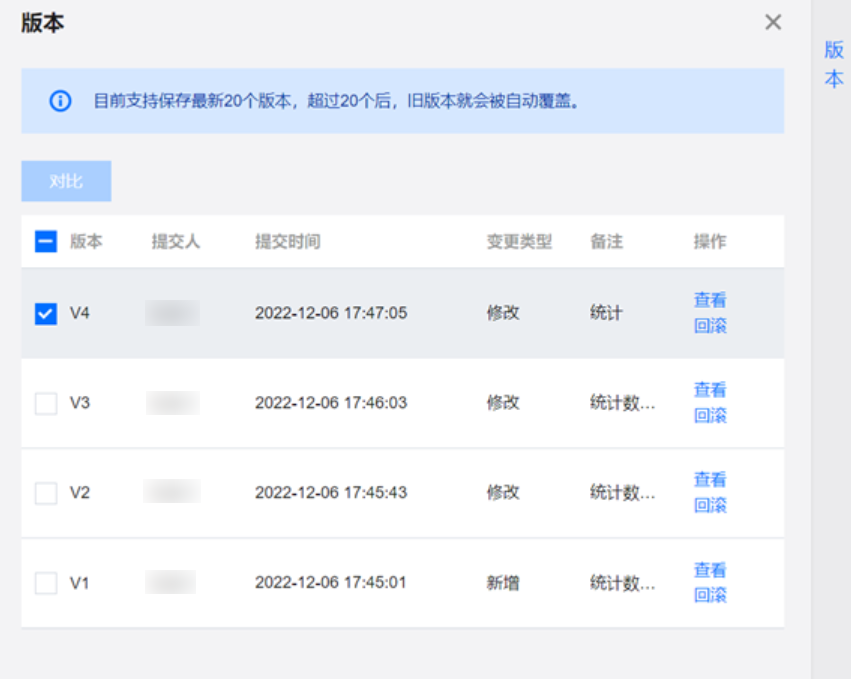
函数示例
Spark SQL 函数开发示例
1. 创建工程
创建 maven 工程并引入 hive-exec 依赖。使用 mvn 命令行创建工程,也可以通过 IDEA 工具进行创建,其中 groupId 和 artifactId 换成自己定义的名字。
mvn archetype:generate -DgroupId=com.example -DartifactId=demo-hive -Dveriosn=1.0-SNAPSHOT -Dpackage=com.example
2. 编写代码
引入 hive-exec 和 junit 测试 pom 依赖。
<dependencies><dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>2.3.8</version><exclusions><exclusion><groupId>org.pentaho</groupId><artifactId>pentaho-aggdesigner-algorithm</artifactId></exclusion><exclusion><groupId>javax.servlet</groupId><artifactId>servlet-api</artifactId></exclusion><exclusion><groupId>org.eclipse.jetty.orbit</groupId><artifactId>javax.servlet</artifactId></exclusion></exclusions></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.11</version><scope>test</scope></dependency></dependencies>
在 src/main/java/com/example 目录中创建 java 类,并继承 org.apache.hadoop.hive.ql.exec.UDF 类,编写 evaluate 方法,实现自定义函数的具体行为,例:将输入的字符串转换成大写形式。
package com.example;import org.apache.hadoop.hive.ql.exec.UDF;public class UppercaseUDF extends UDF {public String evaluate(String input) {return input.toUpperCase();}}
3. 编译打包
引入 maven 打包插件,在项目根路径下,执行 mvn package 命令进行编译打包,这里生成的包名:demo-hive-1.0-SNAPSHOT.jar。
<build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.8.1</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><!--(start) for package jar with dependencies --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.0.0</version><configuration><archive><!--指定main方法所在的类--><manifest><mainClass>com.example.UppercaseUDF</mainClass></manifest></archive><!--不能改jar-with-dependencies--><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs><appendAssemblyId>false</appendAssemblyId></configuration><executions><execution><id>make-assembly</id> <!-- this is used for inheritance merges --><phase>package</phase> <!-- bind to the packaging phase --><goals><goal>single</goal></goals></execution></executions></plugin><!--(end) for package jar with dependencies --></plugins></build><repositories><repository><id>alimaven</id><name>aliyun maven</name><url>http://maven.aliyun.com/nexus/content/groups/public/</url></repository></repositories>
执行 mvn package 命令:
mvn package -Dmaven.test.skip=true
4. 操作函数
进入 WeData 函数开发页面,创建自定义函数,填写函数类全路径名:com.example.UppercaseUDF,选择对应的资源文件,即实现自定义函数编码的 jar 包,如果没有资源文件,则进行资源的创建。
4.1 资源上传:
通过资源管理功能上传 demo-hive-1.0-SNAPSHOT.jar 函数包。
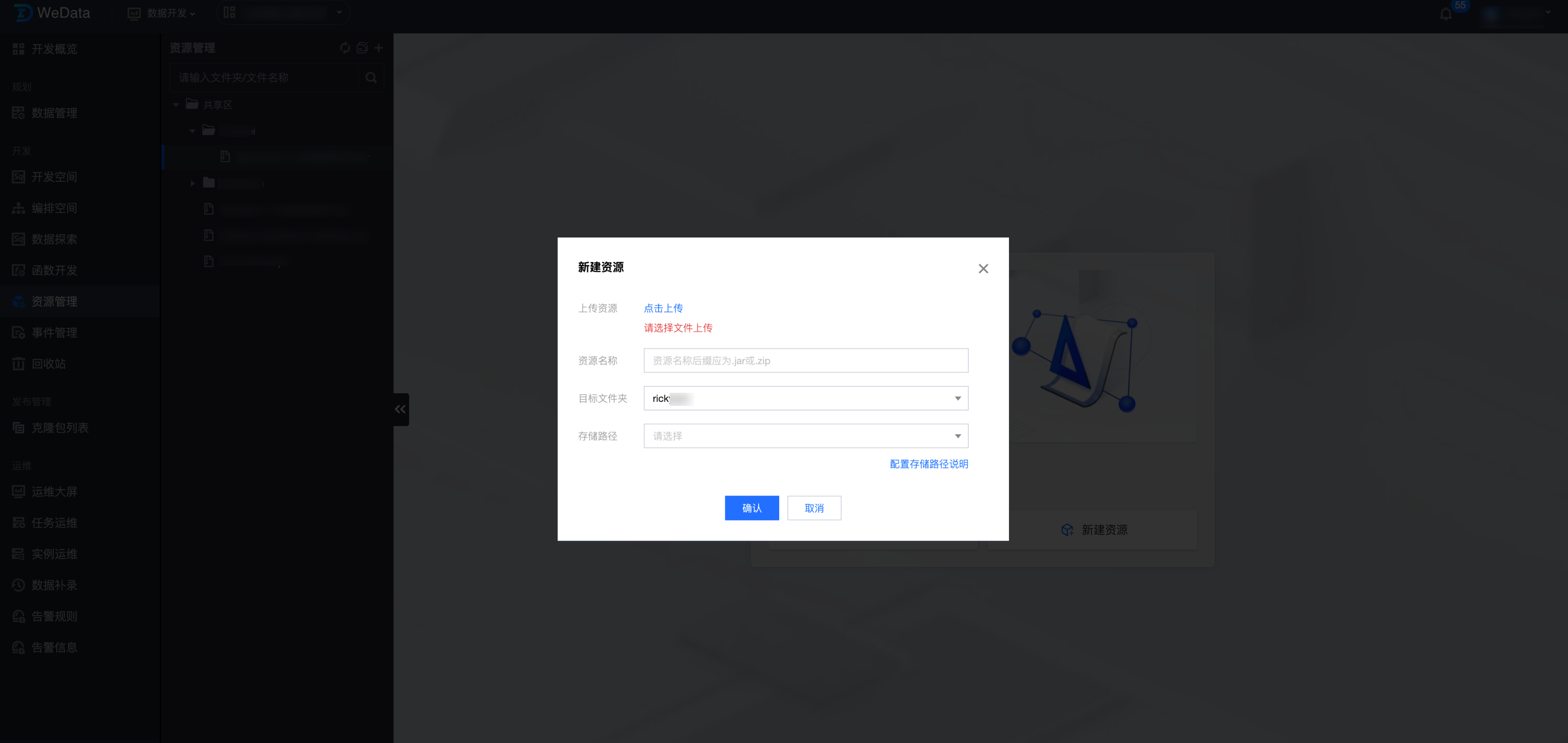
4.2 函数创建:
通过函数开发功能创建 Spark SQL 函数。
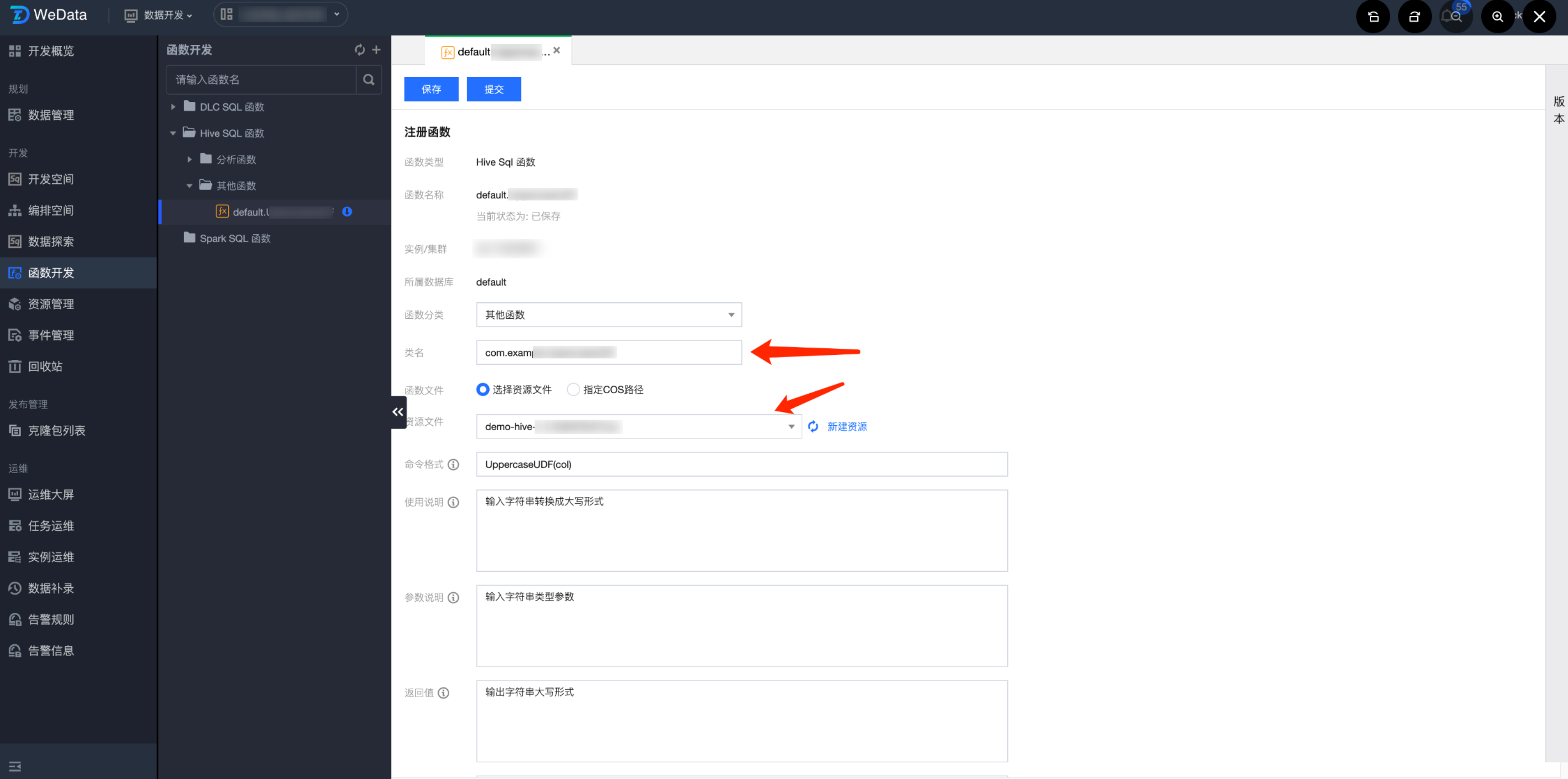
示例函数信息:
信息 | 内容 |
函数分类 | 其他函数 |
类名 | com.example.UppercaseUDF |
函数文件 | 选择资源文件 |
资源文件 | demo-hive-1.0-SNAPSHOT.jar |
命令格式 | UppercaseUDF(col) |
使用说明 | 输入字符串转换成大写格式 |
参数说明 | 输入字符串类型参数 |
返回值 | 输出字符串大写形式 |
4.3 函数使用:
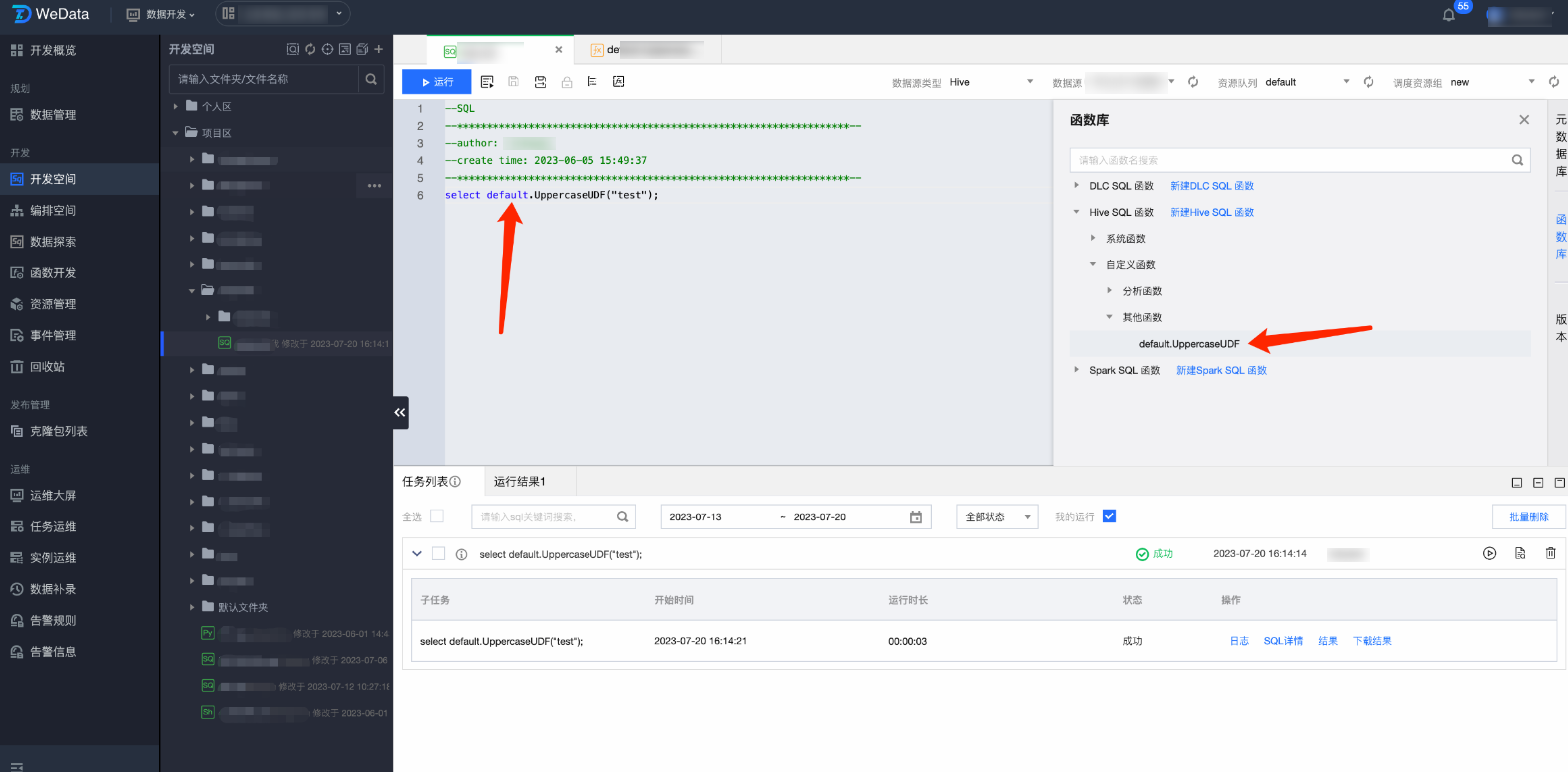
在开发空间中,新建 SQL 文件,使用创建成功的函数,验证其功能。
DLC SQL 函数开发示例
可以直接使用上述 UppercaseUDF 的例子进行 DLC 函数的创建和使用。
文档反馈