动态发布记录(2026年)
附录
Magic 语法
Magic 语法是 Jupyter Notebook 中的一种特性,允许用户通过特定的命令来执行一些特殊的操作,通常以 % 或 %% 开头。Magic 命令可以用于简化常见任务,提高工作效率。
Jupyter Notebook 原生魔法命令
行魔法命令(Line Magics)通常以 % 开头,作用于当前行。
举例说明
Magic 命令 | 含义说明 | 使用示例 |
%run | 运行指定的 Python 脚本或者 Notebook 文件 |
|
%pip | 安装指定的 Python 包 |
|
单元魔法命令(Cell Magics)通常以 %% 开头,作用于整个单元格。
举例说明
Magic 命令 | 含义说明 | 使用示例 |
%%python | 以 Python 语法执行当前单元格(通常不必要,默认为 Python ) |
|
%%markdown | 在单元格中渲染 Markdown 文本 |
|
WeData Notebook 特殊魔法命令
多语言切换
默认情况下,Notebook 使用 Python 语法进行代码编写,如果您想切换当前单元格的语法,可以在单元格的前面增加 %%<language>。
执行下面的 magic 代码需要先执行以下初始化命令:
%load_ext dlcmagic.kyuubikernel.magics.dlcenginemagics%load_ext dlcmagic.pythonkernel.magics
举例说明
Magic 命令 | 含义说明 | 使用示例 |
%%py | 以 PySpark 语法执行当前单元格。使用前需要执行下面的初始化命令 |
|
%%scala | 以 Scala 语法执行当前单元格 |
|
%%sql | 以 Spark SQL 语法执行当前单元格 |
|
注意:
以上 WeData Notebook 的特殊魔法命令,仅适用于连接 DLC 引擎机器学习资源组进行使用。
DLC Utilities(dlcutils)
dlcutils 是 WeData 基于 DLC 引擎提供的一个实用工具库,主要用于简化在 Notebook 环境中的各种操作,可以帮助用户执行与数据处理、参数传递、环境配置等相关的任务。
Data utility(dlcutils.notebook)
函数名称 | 含义说明 | 使用示例 |
summarize(df: Object): void | 对 DataFrame 的统计指标进行计算和展示,便于对数据结构进行了解。 适用于 Python 代码、PySpark 代码。 |
|
Notebook utility(dlcutils.notebook)
函数名称 | 含义说明 | 使用示例 |
exit(value: String): void | 退出当前 notebook ,并打印指定返回值,可以用这个方式将 notebook 的参数传递给下游任务。 |
|
run(path: String, timeoutSeconds: int, arguments: Map): String | 运行 notebook 文件 path:指定 notebook 文件路径 timeoutSeconds:超时时间 arguments:变量 |
|
Parameters utility(dlcutils.params)
函数名称 | 含义说明 | 使用示例 |
text(name: String, defaultValue: String, label: String): void | 设置变量值 |
|
get(name: String): String | 获取指定变量 |
|
remove(name: String): void | 清除指定变量 |
|
removeAll(): void | 清除当前上下文设置的变量 |
|
注意:
以上 dlcutils 函数仅适用于连接 DLC 引擎机器学习资源组进行使用。
MLFlow 函数
MLFlow 是一个开源的机器学习平台,它提供了数据科学生命周期的端到端支持,包括实验管理、模型版本控制、模型部署和模型监控。
腾讯云 WeData 基于 MLFlow 提供了机器学习实验管理和模型管理能力,如果在 Notebook 工作空间中启用了 MLFlow 服务,便可以在实验中通过调用 MLFlow 的相关函数来记录每一次实验的参数、指标和结果,并在 WeData 机器学习模块 > 实验管理和模型管理中进行查看,从而实现实验的追踪和可复现性。
常用的 MLFlow 函数包括:
MLFlow 函数 | 函数名称 | 函数功能和用法 |
实验管理 | mlflow.create_experiment(name) | 创建一个新的实验。 需要保证实验名称的唯一性,如果实验名称已经存在,create_experiment 将引发异常。 |
| mlflow.set_experiment(name) | 设置当前实验。 它可以直接用于已存在的实验名,以便在后续的运行中记录参数和指标。 如果指定的实验不存在,则会自动创建一个新的实验。 |
| mlflow.start_run() | 开始一个新的运行。 返回一个 Run 对象,表示当前运行的上下文。 start_run() 通常与 with 语句一起使用,以确保在运行结束后自动调用 end_run()。 |
记录参数和指标 | mlflow.log_param(key, value) | 记录一个参数及其值。 key (str): 参数的名称。 value (str, int, float): 参数的值。可以是字符串、整数或浮点数。 |
| mlflow.log_metric(key, value, step=None) | 记录一个指标及其值。 |
| mlflow.log_artifact(local_path, artifact_path=None) | 记录本地文件或目录,例如模型的配置文件、数据文件、结果文件等。 local_path:要记录的本地文件或目录的路径; artifact_path:在 MLflow 服务器上存储该文件或目录的路径。 |
模型管理 | mlflow.sklearn.log_model(model, artifact_path) | 记录 Scikit-learn 模型。 |
| mlflow.pyfunc.log_model(artifact_path, python_model) | 记录自定义 Python 模型。 |
| mlflow.register_model(model_uri, name) | 注册模型到模型注册表。模型注册表是 MLflow 提供的模型管理和版本控制功能,便于模型的共享、部署和管理。 |
模型部署 | mlflow.pyfunc.serve(model_uri) | 部署模型为 REST API 服务。用于在本地启动一个 HTTP 服务器,以便提供注册的 MLflow 模型的预测服务,启动服务器后,可以通过 HTTP Post 请求发送数据进行预测。 model_uri:指向已注册模型的 URI ,可以是模型注册表中的 URI ,或已记录模型的路径。 |
Notebook 参数使用示例
在 Notebook 中使用项目参数
1. 进入项目管理 > 参数设置界面,单击新增,完成项目参数的新建。
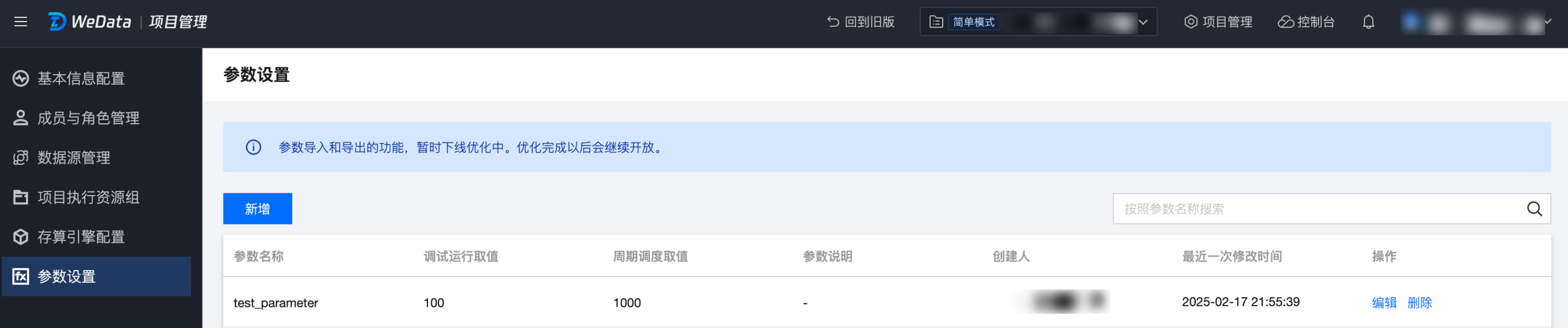
2. 如果在项目管理的参数中已经定义了参数,例如参数名称 test_parameter,取值是100,在 notebook 中可以直接试用项目参数。
# print project parametersprint(dlcutils.params.get("test_parameter"))# output 100
在 Notebook 中使用工作流参数或者任务参数
因为在 Notebook 空间中调试运行 notebook 文件的时候,notebook 还没有关联任务和工作流,所以可以在测试中设置默认值。在 Notebook 周期调度的时候使用工作流和任务上配置的值。
工作流参数可在工作流通用配置中进行配置。
任务参数可在任务的任务属性中进行配置。
例如,任务上配置了任务参数 task_test_param,任务的工作流中配置了 workflow_test_param。
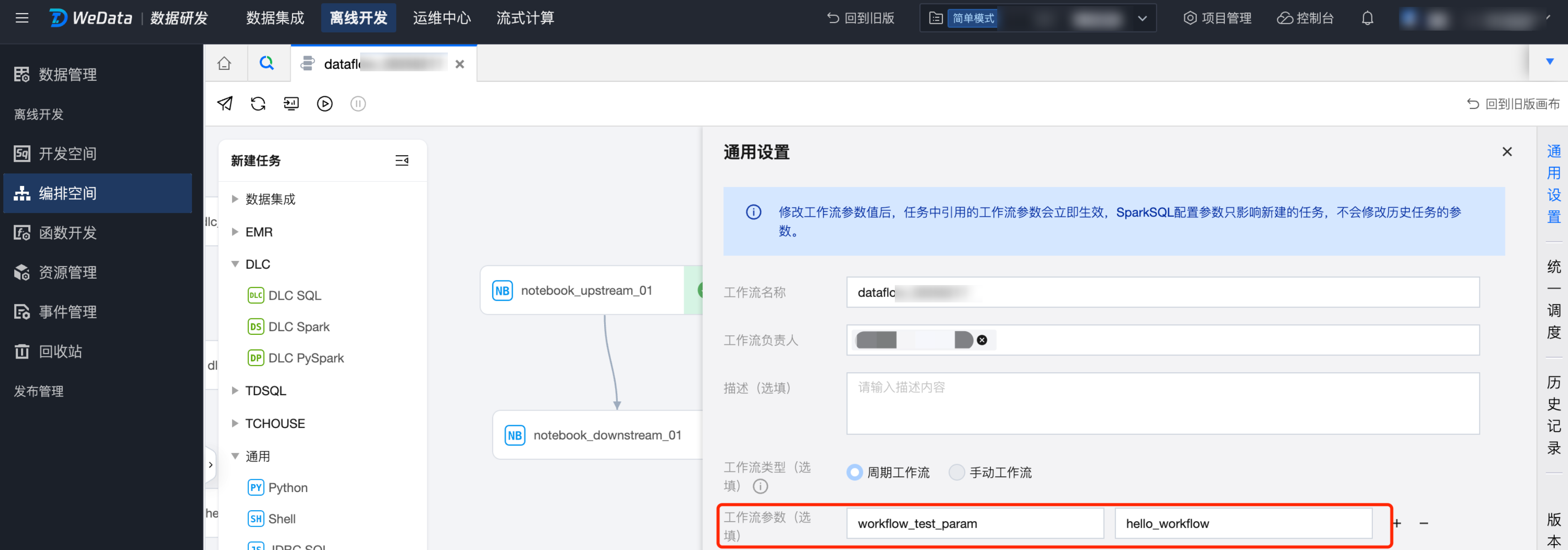
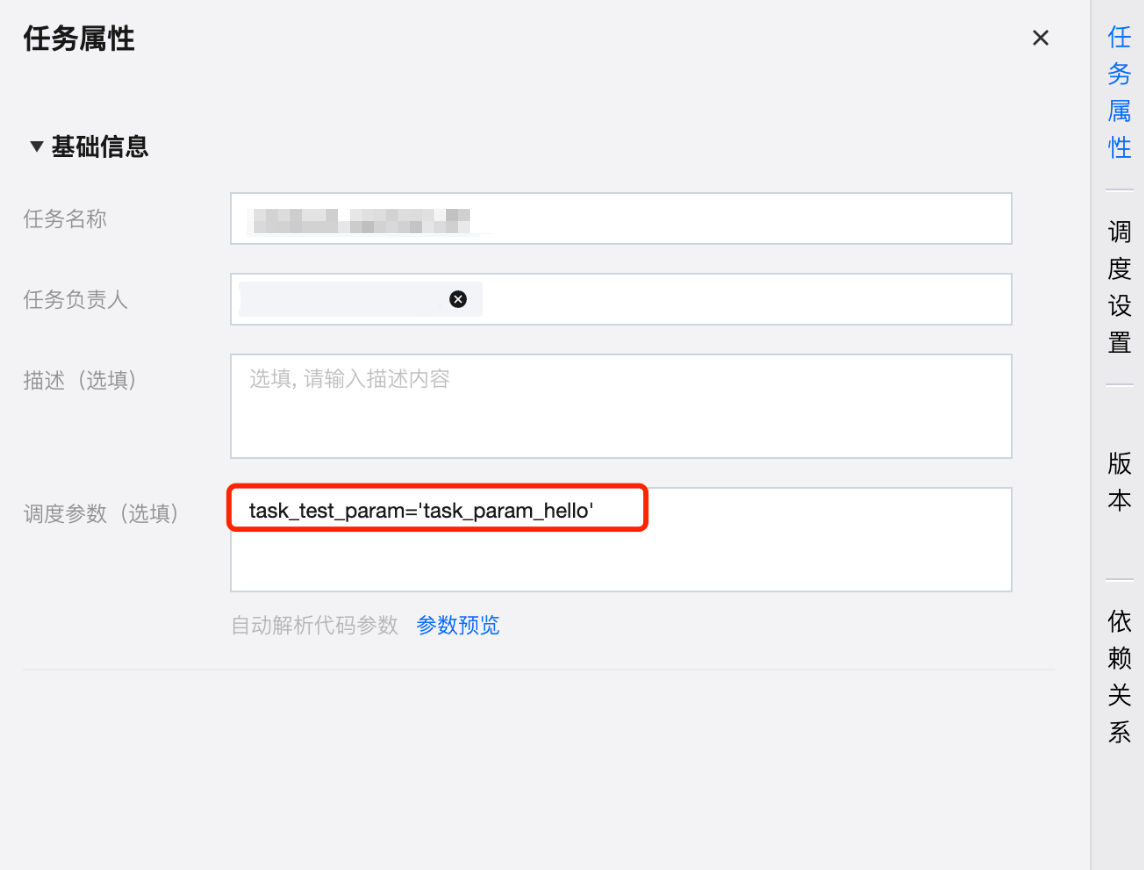
# get task_test_param value# When testing and running in the notebook space,# default values need to be set because the notebook file has not yet been associated with a task.try:task_test_param_value = dlcutils.params.get("task_test_param")if not task_test_param_value: # 如果获取到的值是空字符串task_test_param_value = 'task_default_value'except Exception: # 如果完全获取不到参数task_test_param_value = 'task_default_value'print(f"Using toy value: {task_test_param_value}")
# get workflow_test_param value# When testing and running in the notebook space,# default values need to be set because the notebook file has not yet been associated with a workflow.try:workflow_test_param_value = dlcutils.params.get("workflow_test_param")if not workflow_test_param_value: # 如果获取到的值是空字符串workflow_test_param_value = 'workflow_default_value'except Exception: # 如果完全获取不到参数workflow_test_param_value = 'workflow_default_value'print(f"Using toy value: {workflow_test_param_value}")
notebook 之间参数传递
1. 在 Notebook 空间中,创建两个 notebook 文件:parameter_test_up.ipynb 和 parameter_test_down.ipynb,文件内容如下:
parameter_test_up.ipynb
# Exit the notebook and output parametersdlcutils.notebook.exit('this is output parameter values')
parameter_test_down.ipynb
# get task_input_param value# When testing and running in the notebook space,# default values need to be set because the notebook file has not yet been associated with a task.try:task_input_param = dlcutils.params.get("task_input_param")if not task_input_param: # 如果获取到的值是空字符串task_input_param = 'task_input_default_value'except Exception: # 如果完全获取不到参数task_input_param = 'task_input_default_value'print(f"Using toy value: {task_input_param}")
2. 同时,在编排空间创建两个任务 notebook_upstream_01、notebook_downstream_01,分别选中上面两个 notebook 文件。
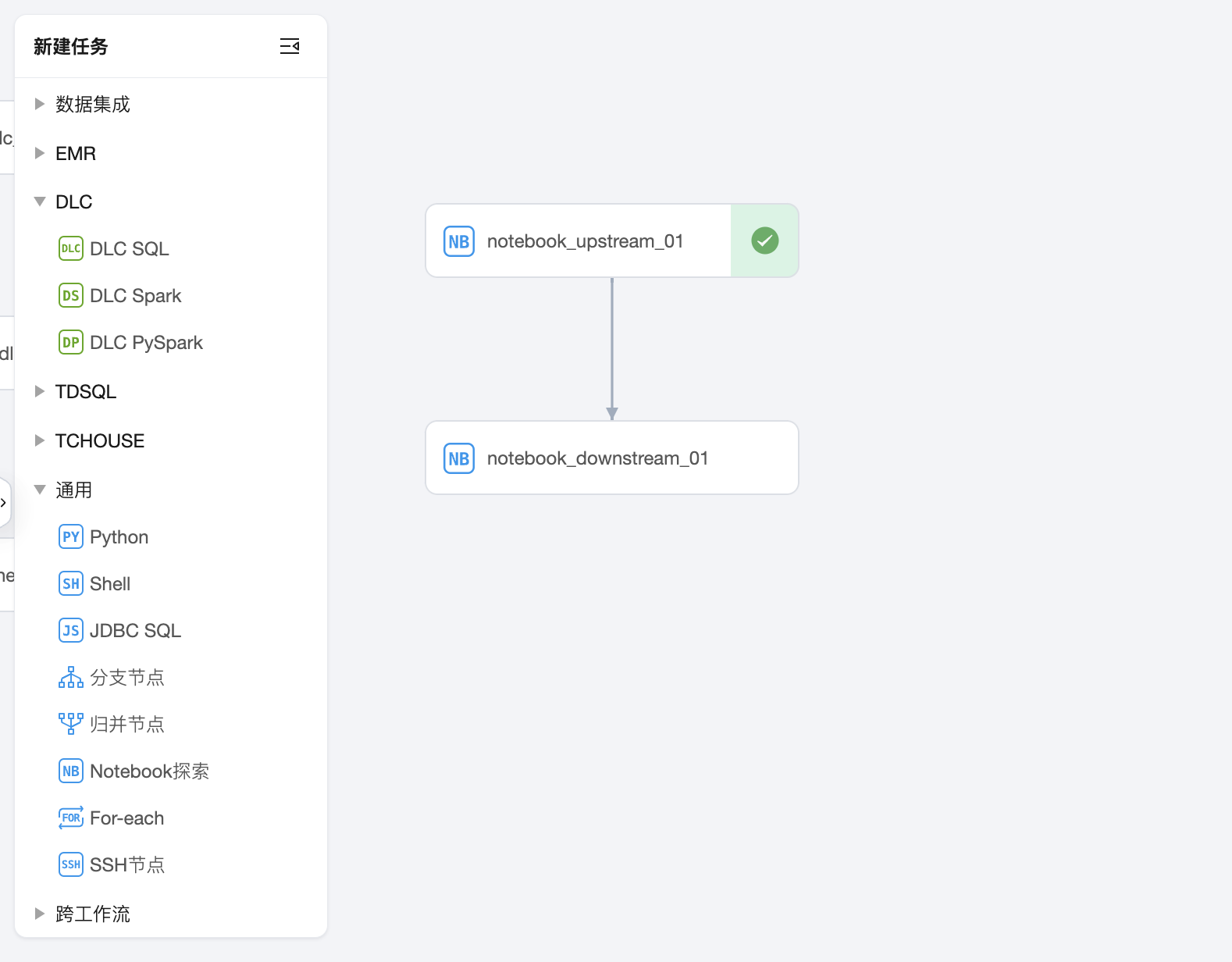
3. 在任务 notebook_upstream_01 的调度设置中,设置输出当前任务参数 task_output_param 为$[0]。
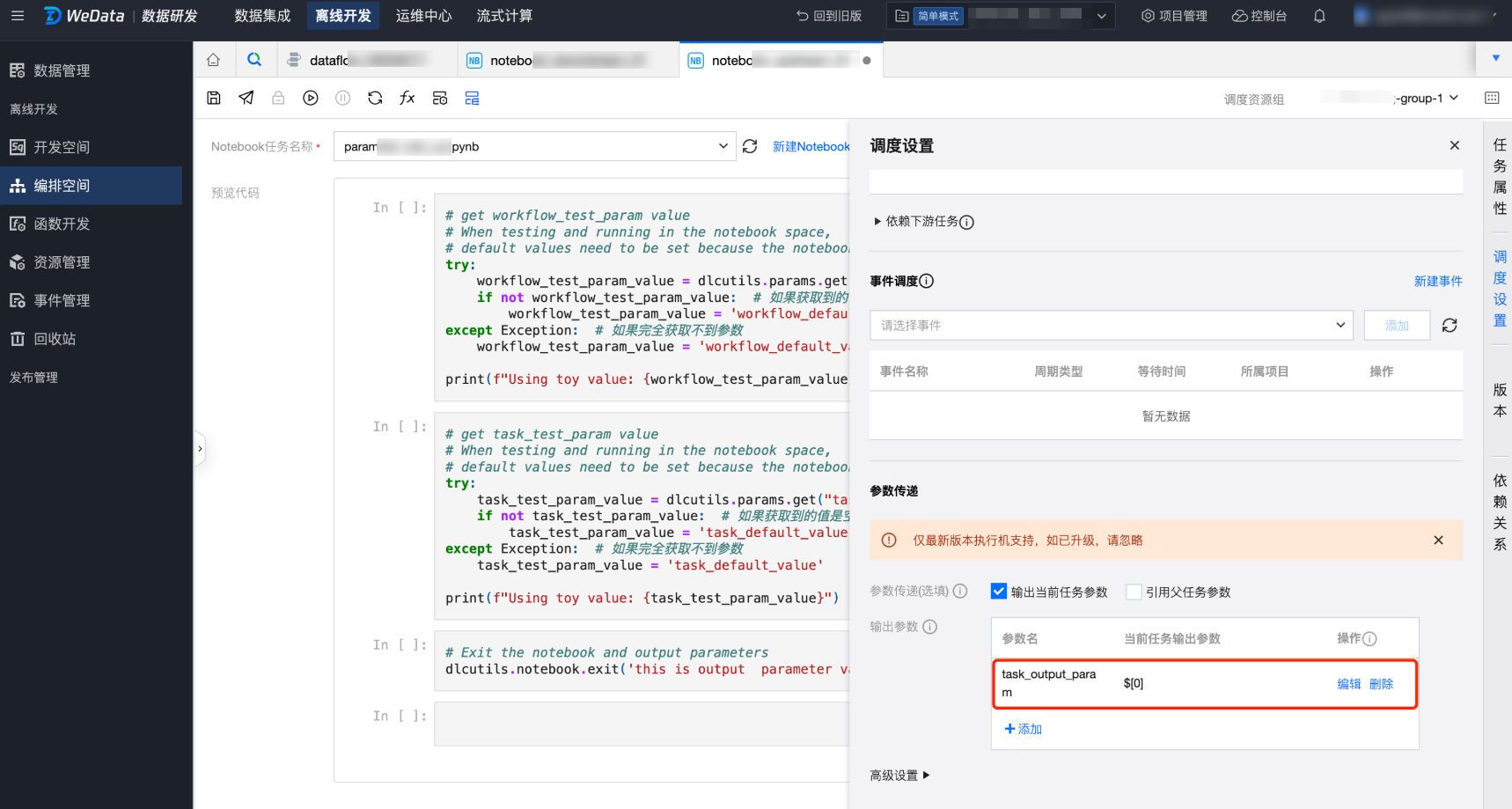
4. 在任务 notebook_downstream_01 的调度设置中,设置输出当前任务参数 task_output_param 为$[0]。
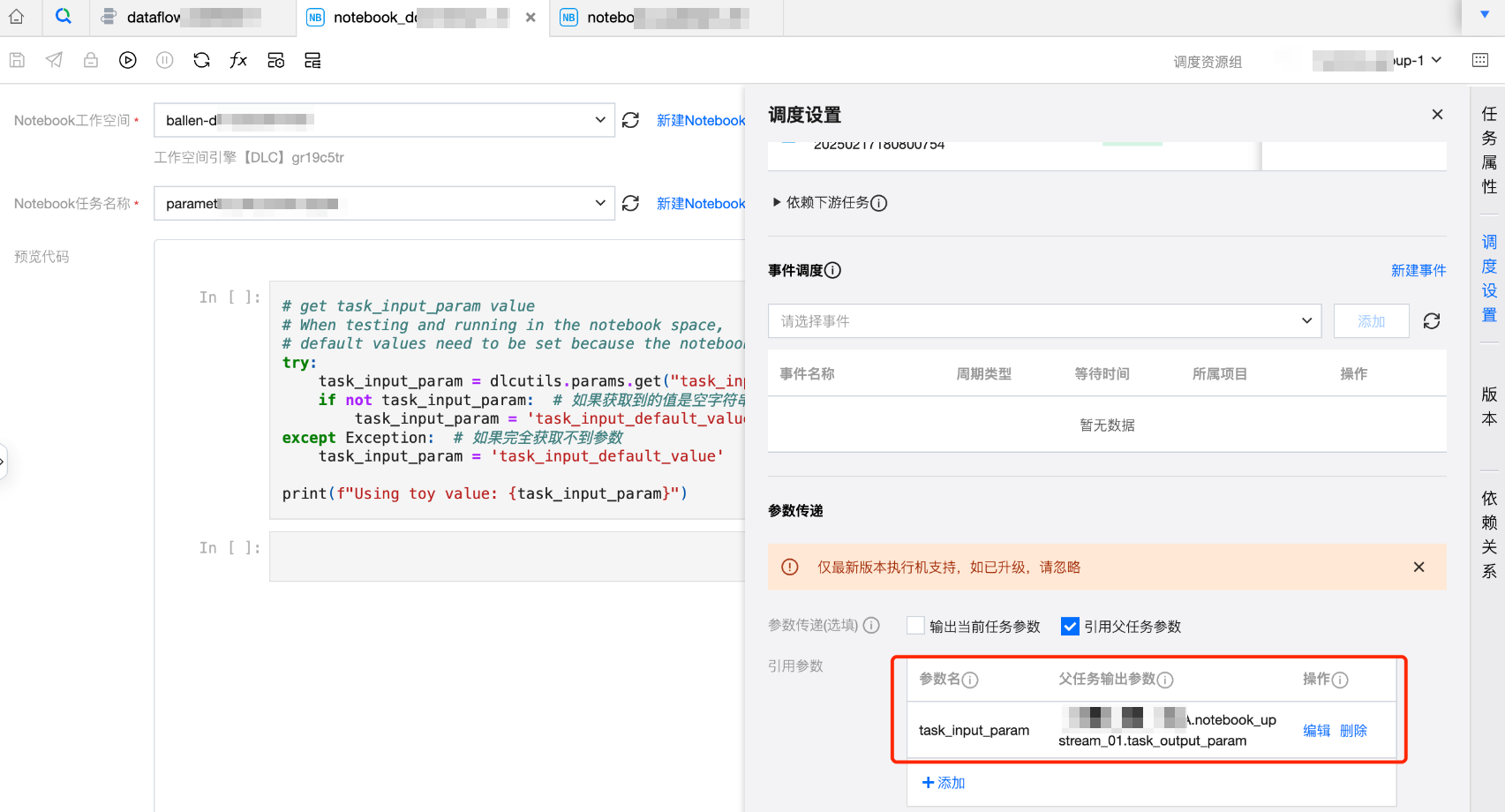
5. 最后,在工作流调试运行或者调度运行中,即可查看 notebook_downstream_01 的输出为 this is output parameter values。
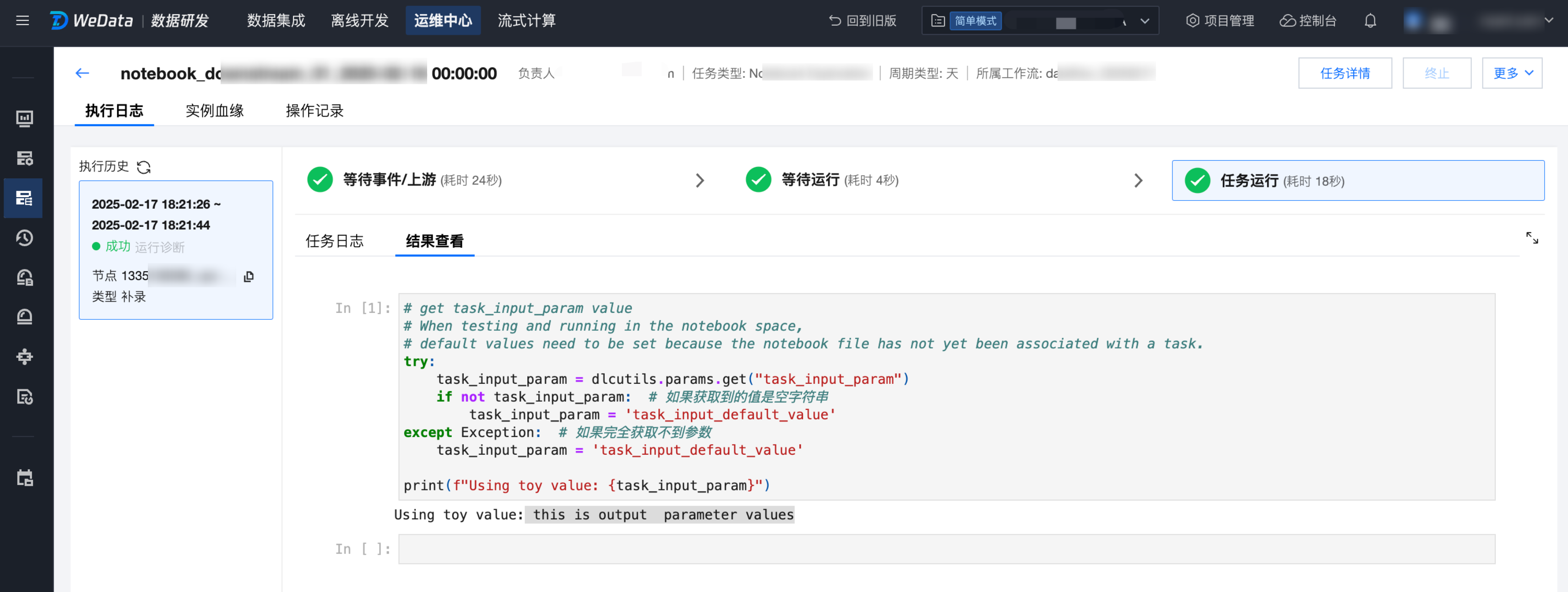
文档反馈