使用 TKE NPDPlus 插件增强节点的故障自愈能力
Download
聚焦模式
字号
在 Kubernetes 集群运行时,节点有时会因为组件问题、内核死锁、资源不足等原因不可用。Kubelet 默认对节点的 PIDPressure、MemoryPressure、DiskPressure 等资源状态进行监控,但是存在当 Kubelet 上报状态时节点已处于不可用状态的情况,甚至 Kubelet 可能已开始驱逐 Pod。在此类场景下,原生 Kubernetes 对节点健康的检测机制是不完善的,为了提前发现节点的问题,需要添加更加细致化的指标来描述节点的健康状态并且采取相应的恢复策略,实现智能运维,以节省开发和减轻运维人员的负担。
node-problem-detector 介绍
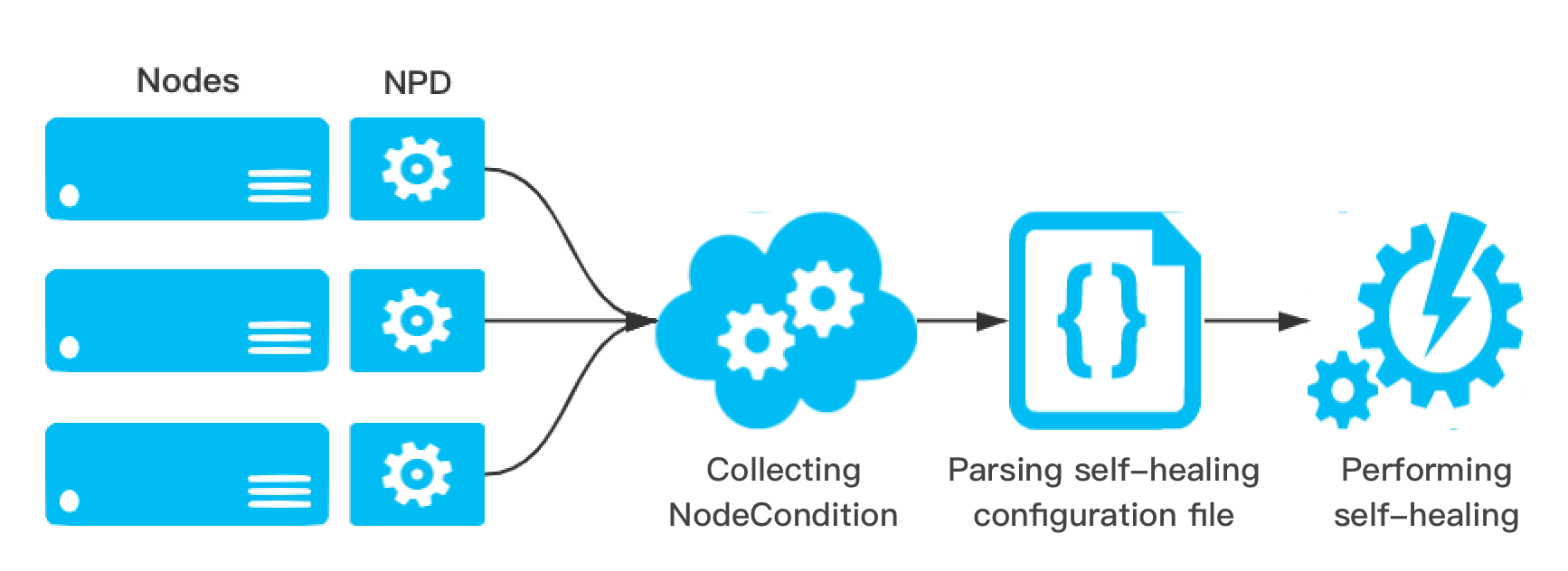
NPD(node-problem-detector)是 Kubernetes 社区开源的集群节点的健康检测组件。NPD 提供了通过正则匹配系统日志或文件来发现节点异常的功能。用户可以通过运维经验,配置可能产生异常问题日志的正则表达式,选择不同的上报方式。NPD 会解析用户的配置文件,当有日志能匹配到用户配置的正则表达式时,可以通过 NodeCondition、Event 或 Promethues Metric 等方式将检测到的异常状态上报。除了日志匹配功能,NPD 还接受用户自行编写的自定义检测插件,用户可以开发自己的脚本或可执行文件集成到 NPD 的插件中,让 NPD 定期执行检测程序。
TKE NPDPlus 组件介绍
在 TKE 中通过扩展组件的形式集成了 NPD,并且对 NPD 的能力做了增强,称为 NodeProblemDetectorPlus(NPDPlus)扩展组件。用户可以对已有集群一键部署 NPDPlus 扩展组件,也可以在创建集群的时候同时部署 NPDPlus。TKE 提取了可以通过特定形式发现节点异常的指标,并将其集成在 NPDPlus 中。例如,可以在 NPDPlus 容器中检测 Kubelet 和 Docker 的 systemd 状态,以及检测主机的文件描述符和线程数压力等。
TKE 使用 NPDPlus 是为了能够提前发现节点的不可用状态,而不是当节点已经不健康后再上报状态。当用户在 TKE 集群中部署了 NPDPlus 后,使用命令
kubectl describe node 后会出现一些 Node Condition,例如,FDPressure 表示该节点上已经使用的文件描述符数量是否已经达到机器允许最大值的80%。ThreadPressure 表示节点上的线程数是否已经达到机器允许的90%等。用户可以监控这些 Condition,当异常状态出现时,提前采取规避策略。详情请参见 Node Conditions。同时,Kubernetes 目前认为节点 NotReady 的机制依赖于 kube-controller-manager 的参数设定,当节点网络完全不通的情况下,Kubernetes 很难在秒级别发现节点的异常。在一些场景下,例如直播、在线会议等,这种延迟是不能接受的。为了解决这个问题,NPDPlus 引入了分布式节点健康检测功能,该功能可以在秒级别快速地检测节点的网络状态,并判断节点是否能够在不依赖于 Kubernetes master 组件通信的情况下,与其他节点相互通信。TKE NPDPlus 组件使用详情请参见 NodeProblemDetectorPlus 使用方法。
节点自愈
采集节点的健康状态是为了能够在业务 Pod 不可用之前提前发现节点异常,从而运维或开发人员可以对 Docker、Kubelet 或节点进行修复。在 NPDPlus 中,为了减轻运维人员的负担,提供了根据采集到的节点状态从而进行不同自愈动作的能力。集群管理员可以根据节点不同的状态配置相应的自愈能力,如重启 Docker、重启 Kubelet 或重启 CVM 节点等。同时为了防止集群中的节点雪崩,在执行自愈动作之前做了严格的限流,防止节点大规模重启。具体策略为:
在同一时刻只允许集群中的一个节点进行自愈行为,并且两个自愈行为之间至少间隔1分钟。
当有新节点添加到集群中时,会给节点2分钟的容忍时间,防止由于节点刚添加到集群的不稳定性导致错误自愈。
当节点触发重启 CVM 自愈动作后还处于异常状态时,在3小时之内此节点不再执行任何自愈动作。
NPDPlus 会将执行过的所有自愈动作记录在 Node 的 Event 中,方便集群管理员了解在 Node 上发生的事件。如下图所示:
文档反馈