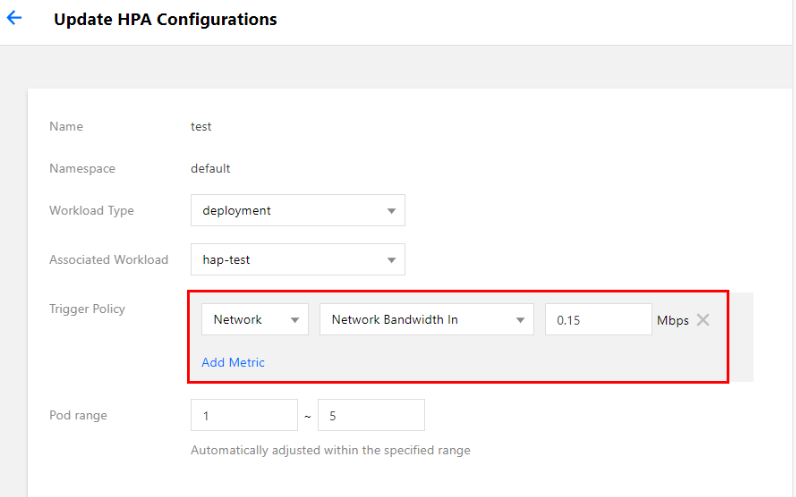
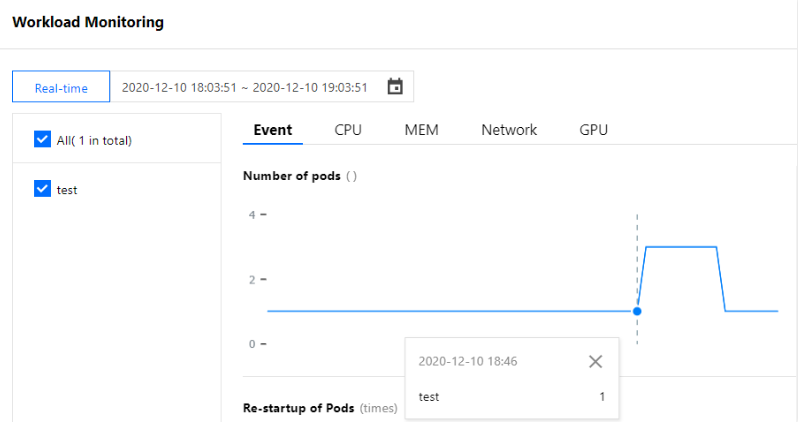
Kubernetes Pod 水平自动扩缩(Horizontal Pod Autoscaler,以下简称 HPA)可以基于 CPU 利用率、内存利用率和其他自定义的度量指标自动扩缩 Pod 的副本数量,以使得工作负载服务的整体度量水平与用户所设定的目标值匹配。本文将介绍和使用腾讯云容器服务 TKE 的 HPA 功能实现 Pod 自动水平扩缩容。
使用场景
HPA 自动伸缩特性使容器服务具有非常灵活的自适应能力,能够在用户设定内快速扩容多个 Pod 副本来应对业务负载的急剧飙升,也可以在业务负载变小的情况下根据实际情况适当缩容来节省计算资源给其他的服务,整个过程自动化无须人为干预,适合服务波动较大、服务数量多且需要频繁扩缩容的业务场景,例如:电商服务、线上教育、金融服务等。
原理概述
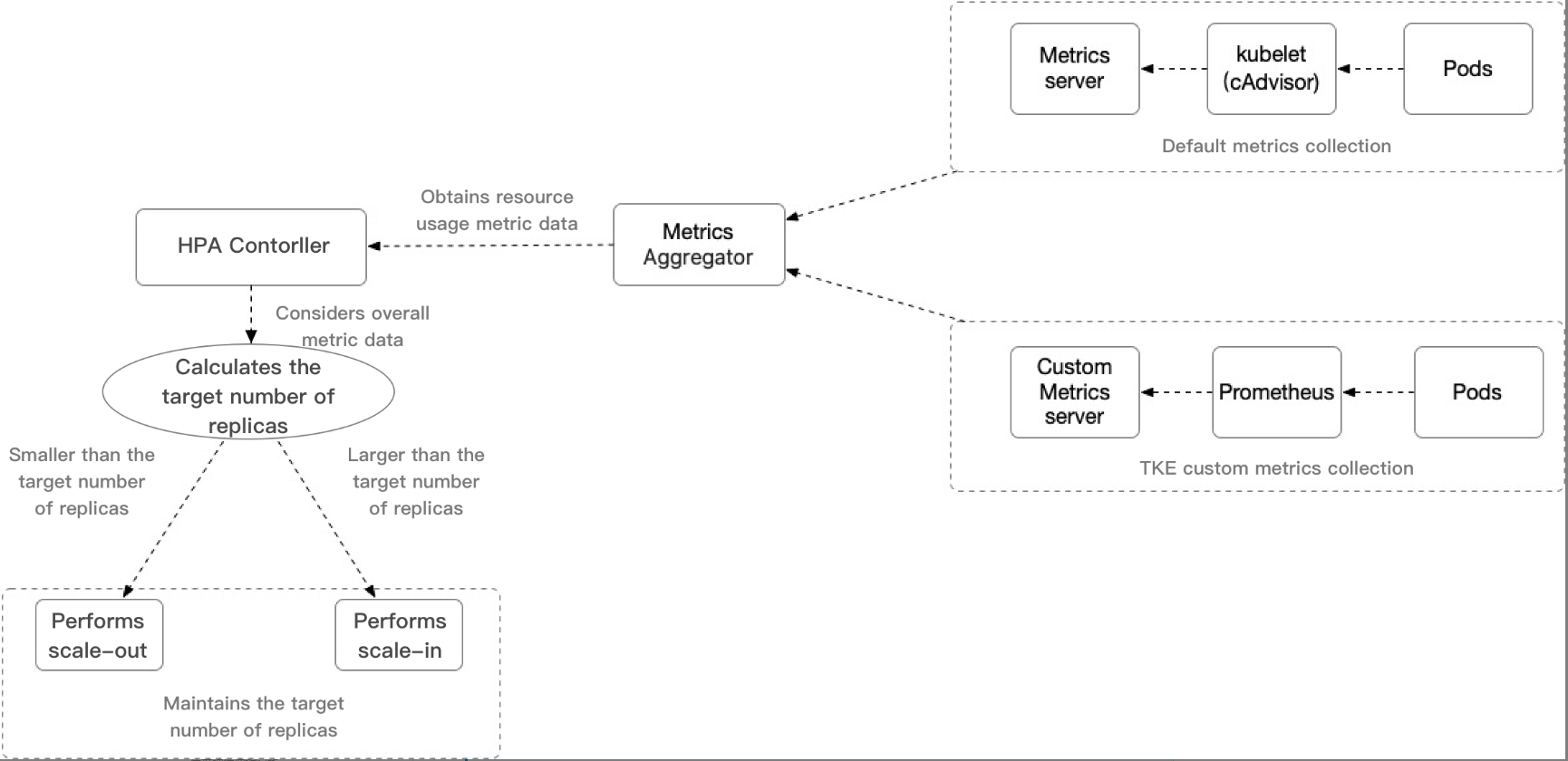
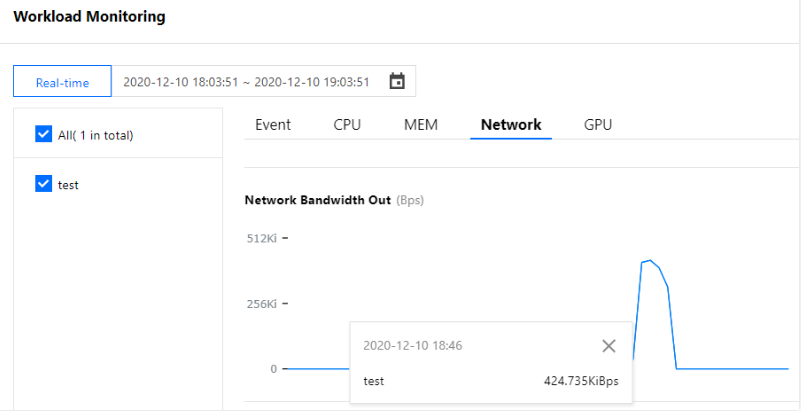
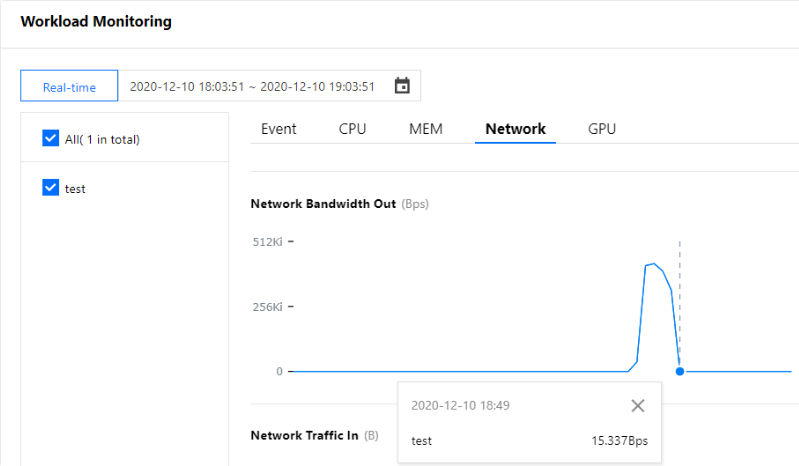
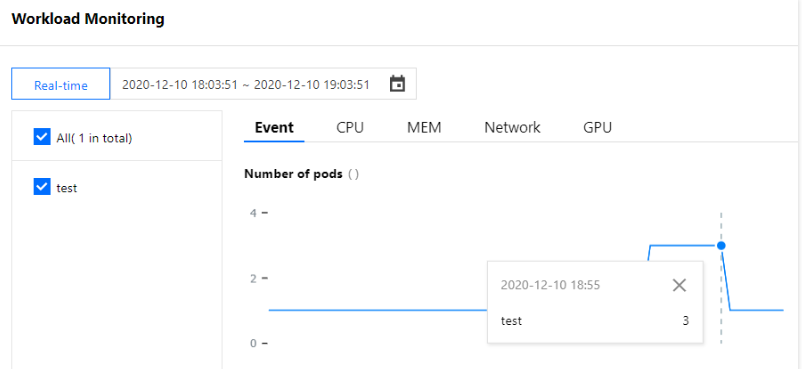
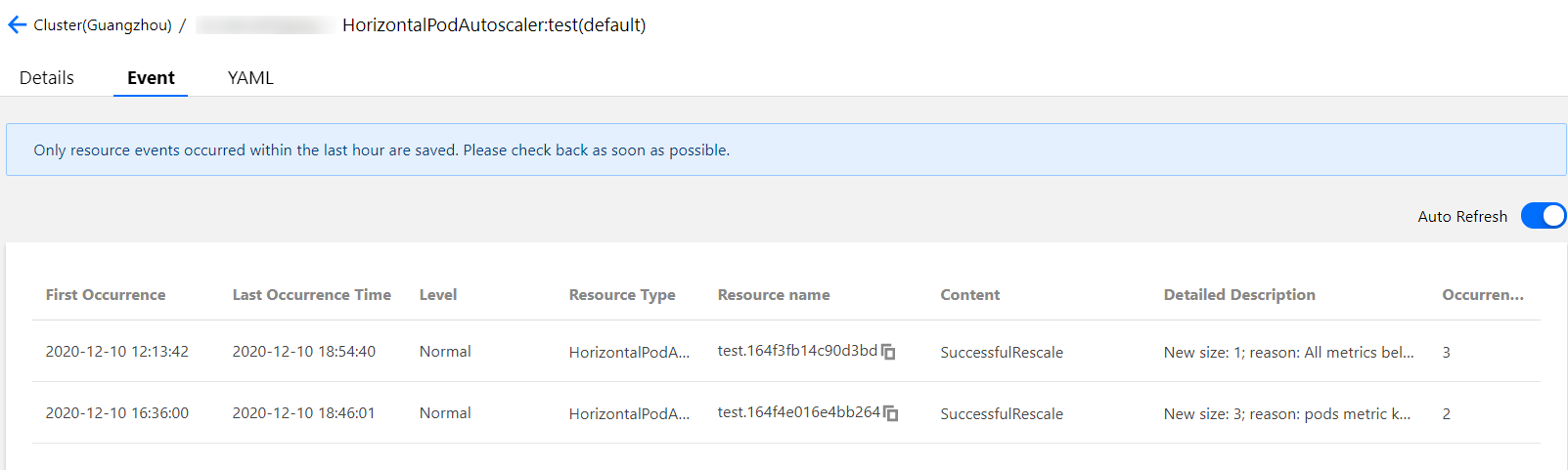
Pod 水平自动扩缩特性由 Kubernetes API 资源和控制器实现。资源利用指标决定控制器的行为,控制器会周期性的根据 Pod 资源利用情况调整服务 Pod 的副本数量,以使得工作负载的度量水平与用户所设定的目标值匹配。其扩缩容流程如下图所示:
注意
Pod 自动水平扩缩不适用于无法扩缩的对象,例如 DaemonSet 资源。
重点内容说明:
HPA Controller:控制 HPA 扩缩逻辑的控制组件。
Metrics Aggregator:度量指标聚合器。通常情况下,控制器将从一系列的聚合 API(metrics.k8s.io、custom.metrics.k8s.io 和 external.metrics.k8s.io)中获取度量值。metrics.k8s.io API 通常由 Metrics 服务器提供,社区版可提供基本的 CPU、内存度量类型。相比于社区版,TKE 使用自定义 Metrics Server 采集可支持更广泛的 HPA 的度量指标触发类型,提供包括 CPU 、内存、硬盘、网络和 GPU 相关指标,了解更多详细内容请参见 TKE 自动伸缩指标说明。