使用 TKE 审计和事件服务快速排查问题
Download
聚焦模式
字号
使用场景
容器服务 TKE 的集群审计和事件存储为用户配置了丰富的可视化图表,以多个维度对审计日志和集群事件进行呈现,操作简单且涵盖绝大多数常见集群运维场景,易于发现和定位问题,提升运维效率,将审计和事件数据的价值最大化。本文结合几个具体使用场景和示例,介绍如何利用审计和事件仪表盘快速定位集群问题。
前提条件
使用示例
示例1:排查工作负载消失问题
1. 登录 容器服务控制台。
2. 在左侧导航栏中选择日志管理 > 审计日志,进入“审计检索”页面。
3. 选择 K8S 对象操作概览页签,在过滤项中指定需要排查的操作类型和资源对象,如下图所示:

4. 查询结果如下图所示:

10001****7138 账号在 2020-11-30T03:37:13时删除了 nginx 应用。可根据账号 ID 在访问管理 > 用户列表 中查找关于此账号的详细信息。示例2:排查节点被封锁问题
1. 登录 容器服务控制台。
2. 在左侧导航栏中选择日志管理 > 审计日志,进入“审计检索”页面。
3. 选择节点操作概览页签,在过滤项中指定被封锁的节点名称,如下图所示:

4. 单击过滤开始查询,查询结果如下图所示:

10001****7138 账号在 2020-11-30T06:22:18 时对 172.16.18.13 节点进行了封锁操作。示例3:排查 apiserver 响应变慢问题
1. 登录 容器服务控制台。
2. 在左侧导航栏中选择日志管理 > 审计日志,进入“审计检索”页面。
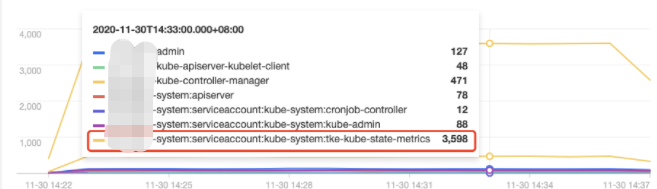
操作用户分布趋势
:
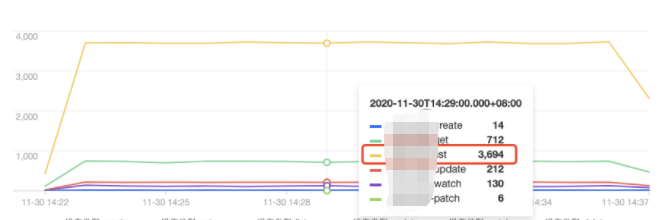
操作类型分布趋势
:
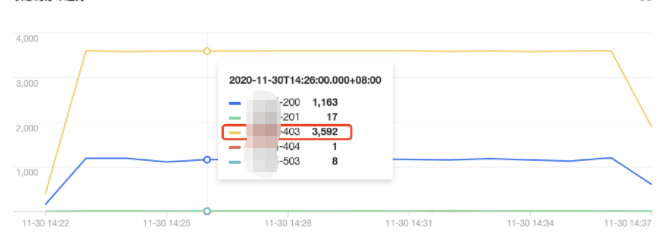
状态码分布趋势
:
tke-kube-state-metrics 的访问量远高于其他用户,并且在 操作类型分布趋势 图中可以看出大多数为 list 操作,在 状态码分布趋势 图中可以看出,状态码大多数为403。结合业务日志可知,由于 RBAC 鉴权问题导致 tke-kube-state-metrics 组件不停的请求 apiserver 重试,导致 apiserver 访问剧增。日志示例如下:E1130 06:19:37.368981 1 reflector.go:156] pkg/mod/k8s.io/client-go@v0.0.0-20191109102209-3c0d1af94be5/tools/cache/reflector.go:108: Failed to list *v1.VolumeAttachment: volumeattachments.storage.k8s.io is forbidden: User "system:serviceaccount:kube-system:tke-kube-state-metrics" cannot list resource "volumeattachments" in API group "storage.k8s.io" at the cluster scope
示例4:排查节点异常问题
1. 登录 容器服务控制台。
2. 在左侧导航栏中,选择日志管理 > 事件日志,进入“事件检索”页面。
3. 选择事件总览页签,在资源对象过滤项中输入异常节点 IP,如下图所示:

4. 单击过滤开始查询。查询结果显示,有一条“节点磁盘空间不足”的事件记录查询结果。
5. 单击该事件,进一步查看异常事件趋势。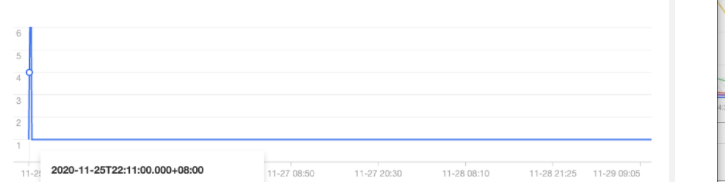

2020-11-25 开始,节点 172.16.18.13 由于磁盘空间不足导致节点异常,此后 kubelet 开始尝试驱逐节点上的 Pod 以回收节点磁盘空间。示例5:查找触发节点扩容的原因
开启了节点池弹性伸缩的集群,CA(cluster-autoscler)组件会根据负载状况自动对集群中节点数量进行增减。如果集群中的节点发生了自动扩(缩)容,用户可通过事件检索对整个扩(缩)容过程进行回溯。
1. 登录 容器服务控制台。
2. 在左侧导航栏中,选择日志管理 > 事件日志,进入“事件检索”页面。
3. 选择全局检索页签,在检索分析栏中输入以下检索命令:
event.source.component : "cluster-autoscaler"
4. 在左侧“隐藏字段”中选择 “
event.reason”、“event.message”、“event.involvedObject.name”、“event.involvedObject.name” 进行显示,单击检索分析开始检索分析日志并将返回检索结果。 5. 将检索结果按照“日志时间”倒序排列,如下图所示:
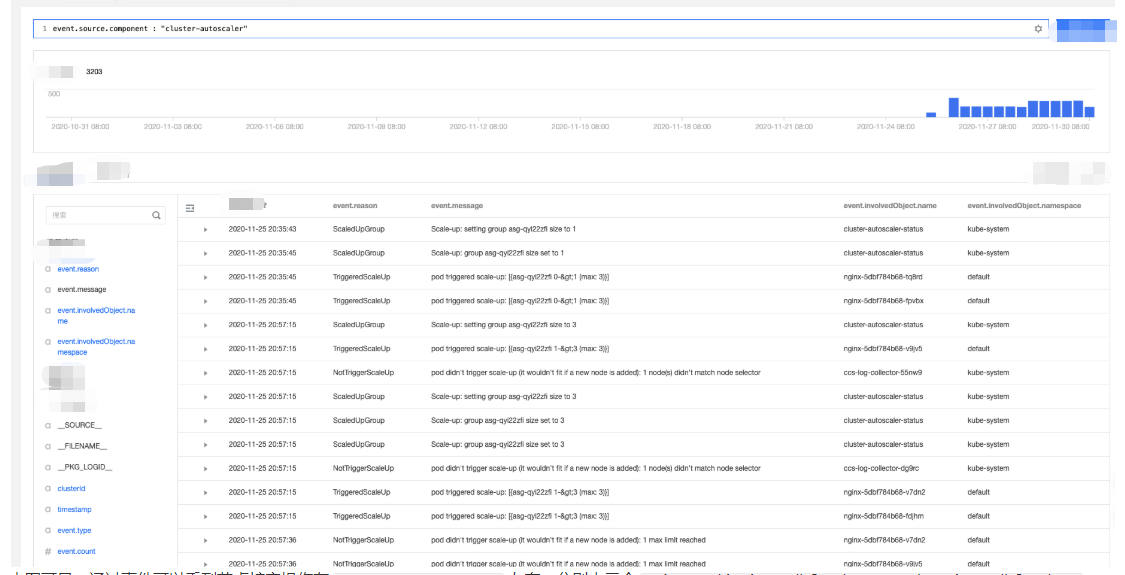
2020-11-25 20:35:45 左右,分别由三个 nginx pod(nginx-5dbf784b68-tq8rd、nginx-5dbf784b68-fpvbx、nginx-5dbf784b68-v9jv5) 进行触发,最终扩增三个节点,后续的扩容由于达到节点池的最大节点数未再次触发。文档反馈