操作场景
腾讯云容器服务 云原生监控 兼容 Prometheus 与 Grafana 的 API,同时也兼容主流 prometheus-operator 的 CRD 用法,为云原生监控提供了极大的灵活性与扩展性,结合 Prometheus 开源生态工具可以解锁更多高级用法。
本文将介绍如何通过辅助脚本和迁移工具,快速将自建 Prometheus 迁移到云原生监控。 前提条件
已在自建 Prometheus 集群的一个节点上安装 Kubectl 并配置好 Kubeconfig,保证通过 Kubectl 能够管理集群。 操作步骤
迁移动态采集配置
自建 Prometheus 若使用 prometheus-operator,通常需要通过 ServiceMonitor 和 PodMonitor 这类 CRD 资源来动态添加采集配置,云原生监控同样支持该用法。若只将自建 Prometheus 集群的 prometheus-operator 迁移到云原生监控,并未迁移集群,则无需迁移动态配置,只需使用云原生监控关联自建集群,自建 Prometheus 创建的 ServiceMonitor 和 PodMonitor 资源即可自动在云原生监控中生效。
如需跨集群迁移,可以将自建 Prometheus 的 CRD 资源导出,并选择性的在被关联的云原生监控的集群中重新应用。以下为您介绍如何在自建 Prometheus 集群中批量导出 ServiceMonitor 和 PodMonitor。
1. 创建脚本 prom-backup.sh,脚本内容如下:
_ns_list=$(kubectl get ns | awk '{print $1}' | grep -v NAME)
count=0
declare -a types=("servicemonitors.monitoring.coreos.com" "podmonitors.monitoring.coreos.com")
for _ns in ${_ns_list}; do
for _type in "${types[@]}"; do
echo "Backup type [namespace: ${_ns}, type: ${_type}]."
_item_list=$(kubectl -n ${_ns} get ${_type} | grep -v NAME | awk '{print $1}' )
for _item in ${_item_list}; do
_file_name=./${_ns}_${_type}_${_item}.yaml
echo "Backup kubernetes config yaml [namespace: ${_ns}, type: ${_type}, item: ${_item}] to file: ${_file_name}"
kubectl -n ${_ns} get ${_type} ${_item} -o yaml > ${_file_name}
count=$[count + 1]
echo "Backup No.${count} file done."
done;
done;
done;
2. 执行以下命令,运行 prom-backup.sh 脚本:
3. prom-backup.sh 脚本会将每个 ServiceMonitor 与 PodMonitor 资源导出成单独的 YAML 文件。可执行 ls 命令查看输出的文件列表,示例如下:
$ ls
kube-system_servicemonitors.monitoring.coreos.com_kube-state-metrics.yaml
kube-system_servicemonitors.monitoring.coreos.com_node-exporter.yaml
monitoring_servicemonitors.monitoring.coreos.com_coredns.yaml
monitoring_servicemonitors.monitoring.coreos.com_grafana.yaml
monitoring_servicemonitors.monitoring.coreos.com_kube-apiserver.yaml
monitoring_servicemonitors.monitoring.coreos.com_kube-controller-manager.yaml
monitoring_servicemonitors.monitoring.coreos.com_kube-scheduler.yaml
monitoring_servicemonitors.monitoring.coreos.com_kube-state-metrics.yaml
monitoring_servicemonitors.monitoring.coreos.com_kubelet.yaml
monitoring_servicemonitors.monitoring.coreos.com_node-exporter.yaml
4. 您可以自行筛选和修改,将 YAML 文件重新应用到被关联的云原生监控的集群中(请勿应用已经存在或功能相同的采集规则),云原生监控会自动感知这部分动态采集规则并进行采集。
说明:
若后续需增加 ServiceMonitor 或 PodMonitor,可以通过 TKE 控制台进行可视化添加,也可脱离控制台直接用 YAML 创建,用法与 Prometheus 社区的 CRD 完全兼容。
迁移静态采集配置
若自建 Prometheus 系统直接使用 Prometheus 原生配置文件,只需在 TKE 控制台进行简单的几步操作,即可将其转换为云原生监控的 RawJob,使其兼容 Prometheus 原生配置文件的 scrape_configs 配置项。
2. 在左侧菜单栏中单击 云原生监控进入云原生监控页面。
3. 单击需要配置的云原生监控 ID/名称,进入基本信息页面。
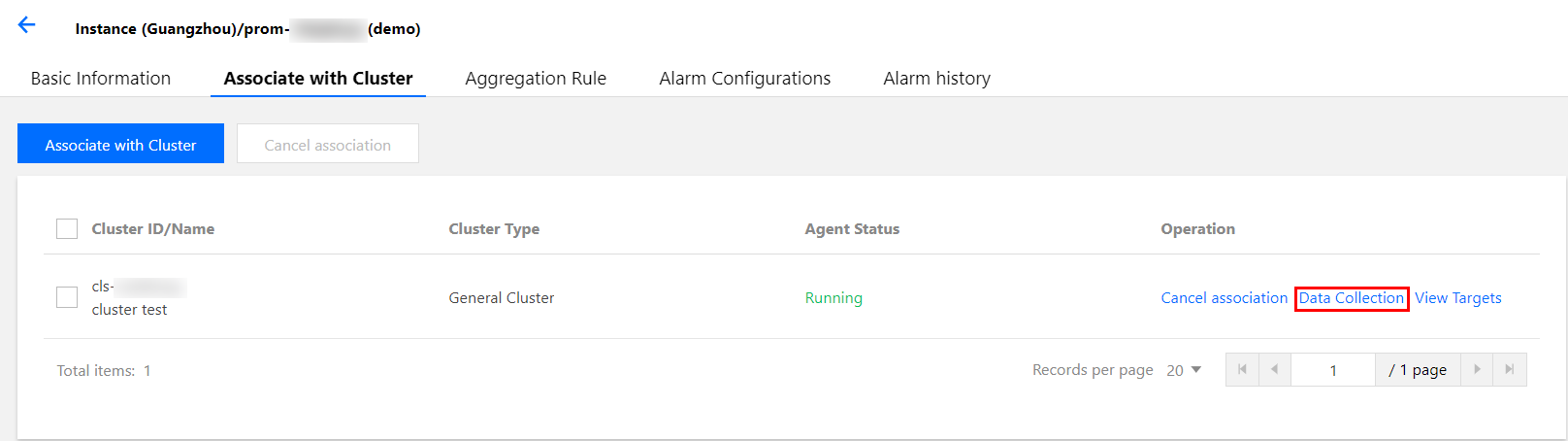
4. 选择关联集群页签,在对应的集群右侧操作列项下单击数据采集配置。
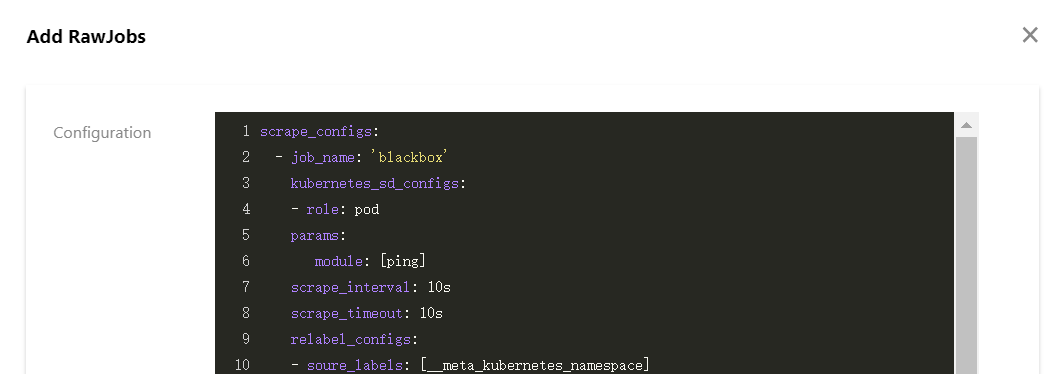
5. 选择RawJob>新增,打开添加 RawJobs 窗口。将原生 Prometheus 配置文件中的 Job 配置复制粘贴到此配置窗口中。
6. 可以将所有需要导入的 Job 数组都粘贴到云原生监控,单击确定后会自动拆分成多个 RawJob,名称为每个 Job 的 job_name 字段。
迁移全局配置
云原生监控提供 Prometheus CRD 资源,可以通过修改该资源来修改全局配置。
1. 执行以下命令,获取 Prometheus 相关信息。
$ kubectl get ns
prom-fnc7bvu9 Active 13m
$ kubectl -n prom-fnc7bvu9 get prometheus
NAME VERSION REPLICAS AGE
tke-cls-hha93bp9 11m
$ kubectl -n prom-fnc7bvu9 edit prometheus tke-cls-hha93bp9
2. 执行以下命令,修改 Prometheus 相关配置。
$ kubectl -n prom-fnc7bvu9 edit prometheus tke-cls-hha93bp9
在弹出的编辑页面,您可修改以下参数:
scrapeInterval:采集抓取间隔时长(默认为15s)。
externalLabels:可为所有时序数据增加默认的 label 标识。
迁移聚合配置
2. 在左侧菜单栏中单击 云原生监控进入云原生监控页面。
3. 单击需要配置的云原生监控 ID/名称,进入基本信息页面。
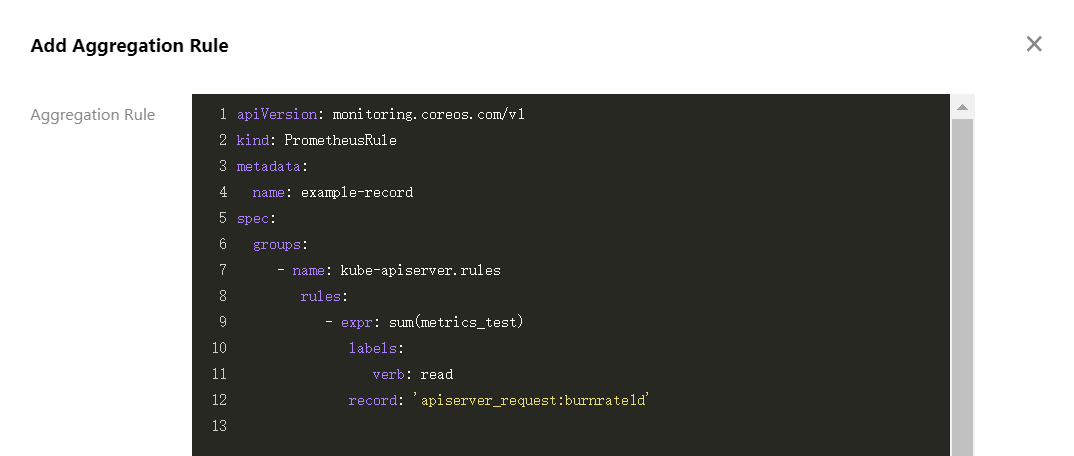
4. 选择聚合规则>新建聚合规则,打开新建聚合规则窗口。使用 PrometheusRule 格式将每条规则粘贴到 groups 数组中。如下图所示:
说明:
若自建 Prometheus 本身使用 PrometheusRule 定义的聚合规则,仍建议将其按照上述步骤进行迁移。若直接使用 YAML 方式在集群中创建 PrometheusRule 资源,云原生监控暂时无法将其显示到控制台。
迁移告警配置
本文提供以下自建 Prometheus 告警原始配置 YAML 文件为例,介绍如何将其转换为云原生监控类似的监控配置。
- alert: NodeNotReady
expr: kube_node_status_condition{condition="Ready",status="true"} == 0
for: 5m
labels:
severity: critical
annotations:
description: 节点 {{ $labels.node }} 长时间不可用 (集群id {{ $labels.cluster }})
2. 在左侧菜单栏中单击 云原生监控进入云原生监控页面。
3. 单击需要配置的云原生监控 ID/名称,进入基本信息页面。
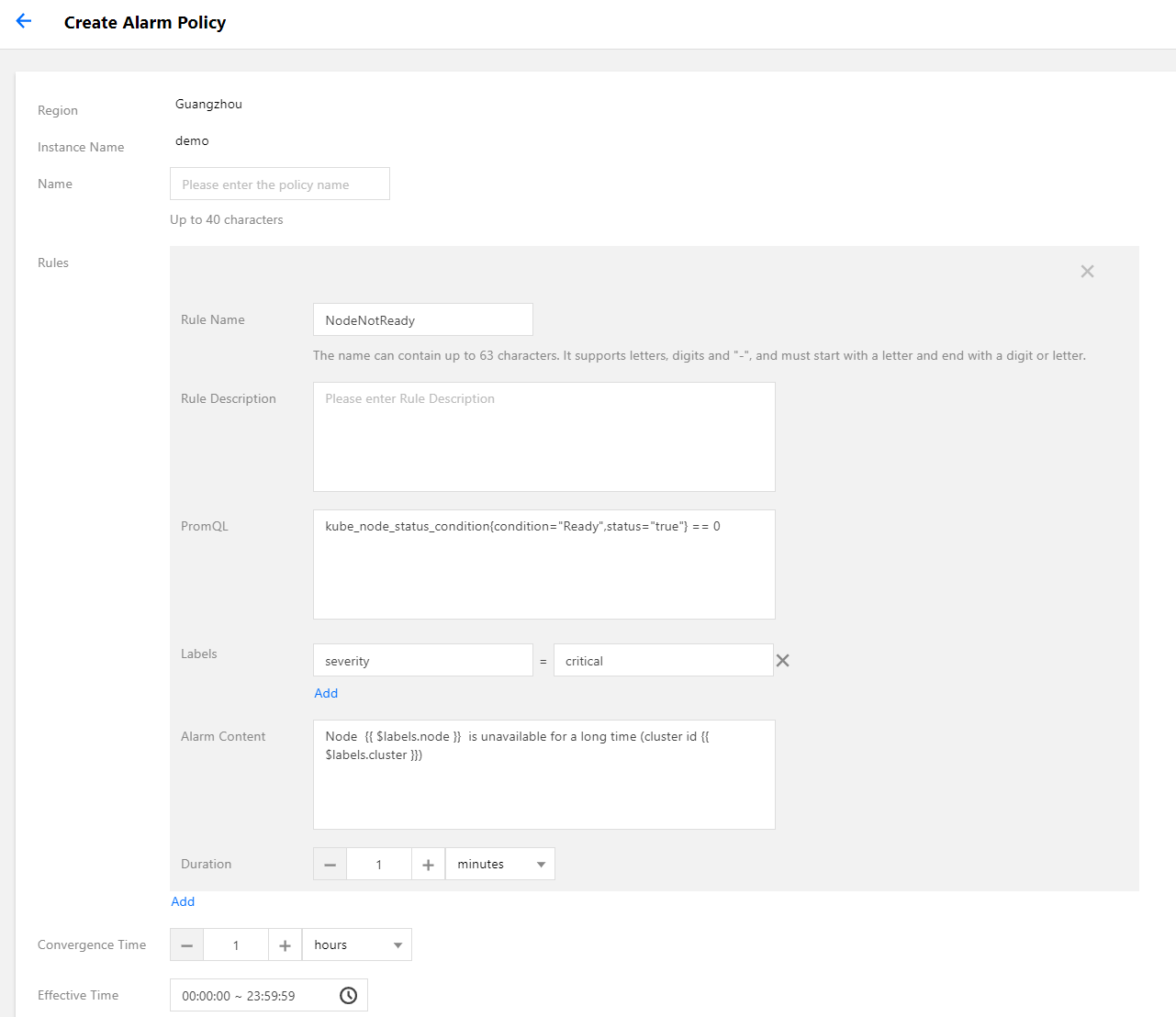
4. 选择 告警配置>新建告警策略,配置告警策略:
主要参数信息如下: PromQL:等同于 原始配置 的 expr 字段,为告警的核心配置,用于指示告警触发条件的 PromQL 表达式。 Labels:等同于 原始配置 的 labels 字段,为告警添加额外的 label。 告警内容:表示推送的告警内容,通常使用模板,可插入变量。建议带上集群 ID,可使用变量 {{ $labels.cluster }} 表示集群 ID。
持续时间:等同于 原始配置 的 for 字段,表示达到告警条件多久之后还未恢复就推送告警。本文示例配置为5分钟。 收敛时间:等同于 AlertManager 的 repeat_interval 配置,表示某个告警推送之后多久之后还未恢复就再次推送,即相同告警的推送间隔时长。本文示例配置为1小时。 说明:
上述告警配置示例表示节点状态变为 NotReady 之后,5分钟内未恢复即推送告警,如果长时间未恢复,则间隔1小时再次推送告警。
5. 配置告警渠道,目前支持腾讯云与 WebHook 两类:
腾讯云告警渠道集成短信、邮件、微信、电话告警方式,可根据自身需求勾选:
如要配置其他告警渠道,例如钉钉、Zoom 等,可自行部署相关的 WebHook 后端,并在云原生监控指定 WebHook 的 URL:
迁移 Grafana 面板
自建 Prometheus 通常配置了许多自定义的 Grafana 监控面板,如需迁移到其他平台,在面板数量较多的情况下,依次导出再导入方式效率太低。借助 grafana-backup 工具可以实现 Grafana 面板的批量导出和导入,您可以参考以下批量导出导入面板步骤进行快速迁移。 1. 执行以下命令安装 grafana-backup。示例如下:
pip3 install grafana-backup
说明:
推荐使用 Python3,使用 Python2 可能存在兼容性问题。
2. 创建 API Keys。
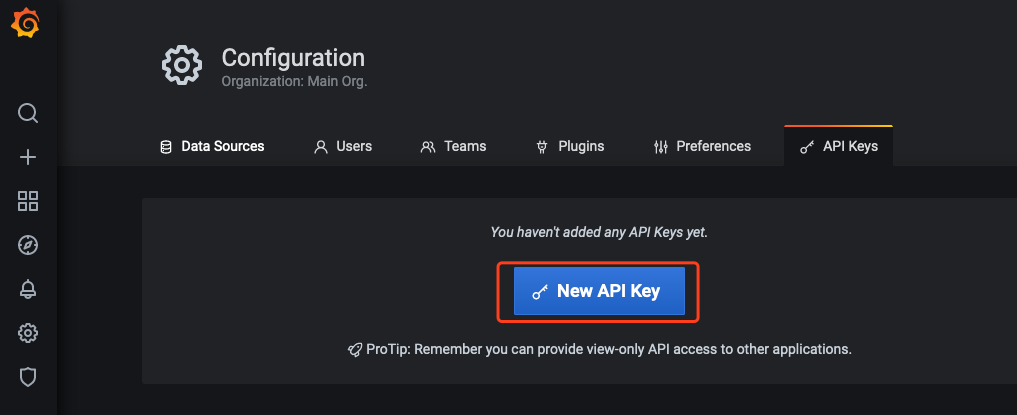
2.1 分别打开自建 Grafana 与云原生监控 Grafana 的配置面板,选择API Keys>New API Key,如下图所示:
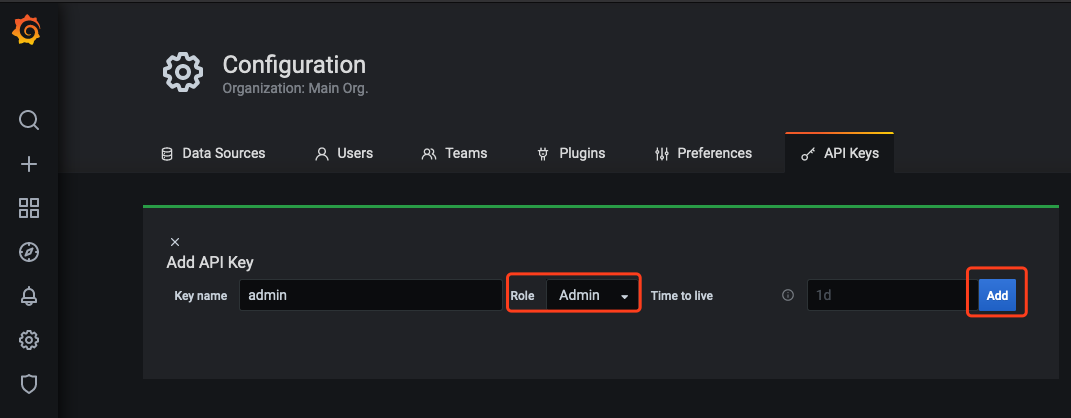
2.2 在 Add API Key 窗口中,创建一个 Role 为 Admin 的 APIKey,如下图所示:
3. 为需要导出的面板准备备份配置文件。
3.1 执行以下命令,获取自建 Grafana 的访问地址。示例如下:
$ kubectl -n monitoring get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
grafana ClusterIP 172.21.254.127 <none> 3000/TCP 25h
说明:
上述 Grafana 集群内访问地址以 http://172.21.254.127:3000 为例。
3.2 执行以下命令,生成 grafana-backup 配置文件(写入 Grafana 地址与 APIKey)。示例如下:
export TOKEN=<TOKEN>
cat > ~/.grafana-backup.json <<EOF
{
"general": {
"debug": true,
"backup_dir": "_OUTPUT_"
},
"grafana": {
"url": "http://172.21.254.127:3000",
"token": "${TOKEN}"
}
}
EOF
说明:
<TOKEN> 需要替换为自建 Grafana 的 APIKey,url 地址需替换为实际环境地址。
4. 执行以下命令,导出所有面板。示例如下:
面板将以一个压缩文件的形式保存在 _OUTPUT_ 目录下,您可以执行以下命令查看该目录下存在的文件。示例如下:
$ tree _OUTPUT_
_OUTPUT_
└── 202012151049.tar.gz
0 directories, 1 file
5. 执行以下命令,准备还原配置文件。示例如下:
export TOKEN=<TOKEN>
cat > ~/.grafana-backup.json <<EOF
{
"general": {
"debug": true,
"backup_dir": "_OUTPUT_"
},
"grafana": {
"url": "http://prom-xxxxxx-grafana.ccs.tencent-cloud.com",
"token": "${TOKEN}"
}
}
EOF
说明:
将 <TOKEN> 替换为云原生监控 Grafana 的 APIKey,url 替换为云原生监控 Grafana 的访问地址(通常用外网访问地址,需开启)。
6. 执行以下命令,将导出的面板一键导入到云原生监控 Grafana。示例如下:
grafana-backup restore _OUTPUT_/202012151049.tar.gz
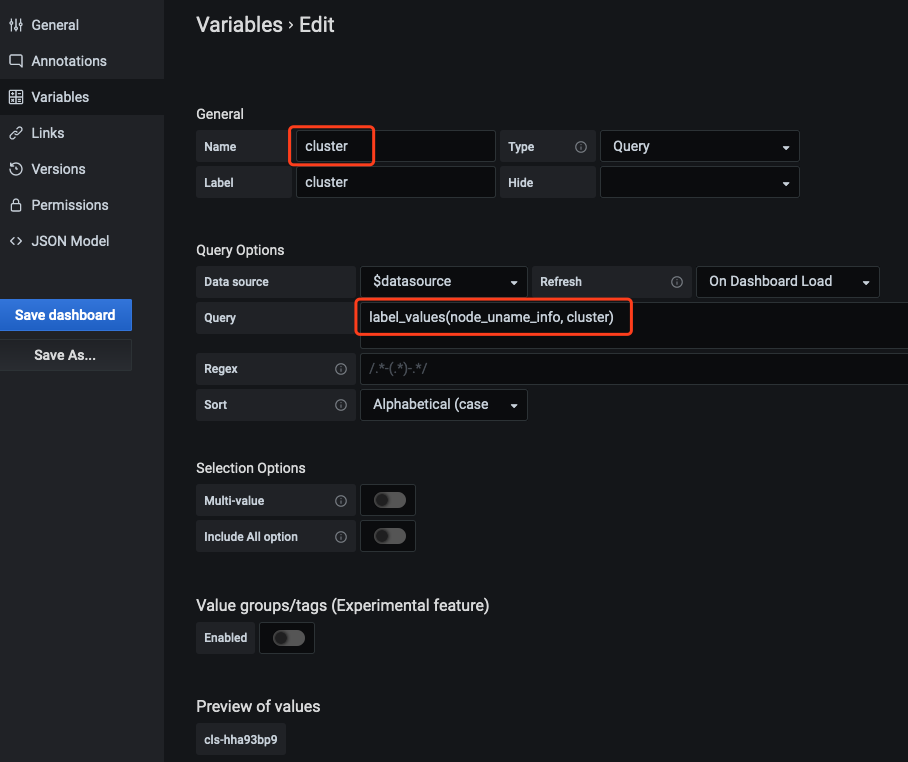
7. 在 Grafana 配置面板选择 Dashboard settings>Variables>New, 新建 cluster 字段。建议为所有面板都加上 cluster 的过滤字段,云原生监控支持多集群,将会给每个集群的数据打上 cluster 标签,用集群 ID 来区分不同集群。如下图所示:
说明:
label_values 中填入当前面板任意涉及到的一个指标名(示例中为 node_uname_info)。
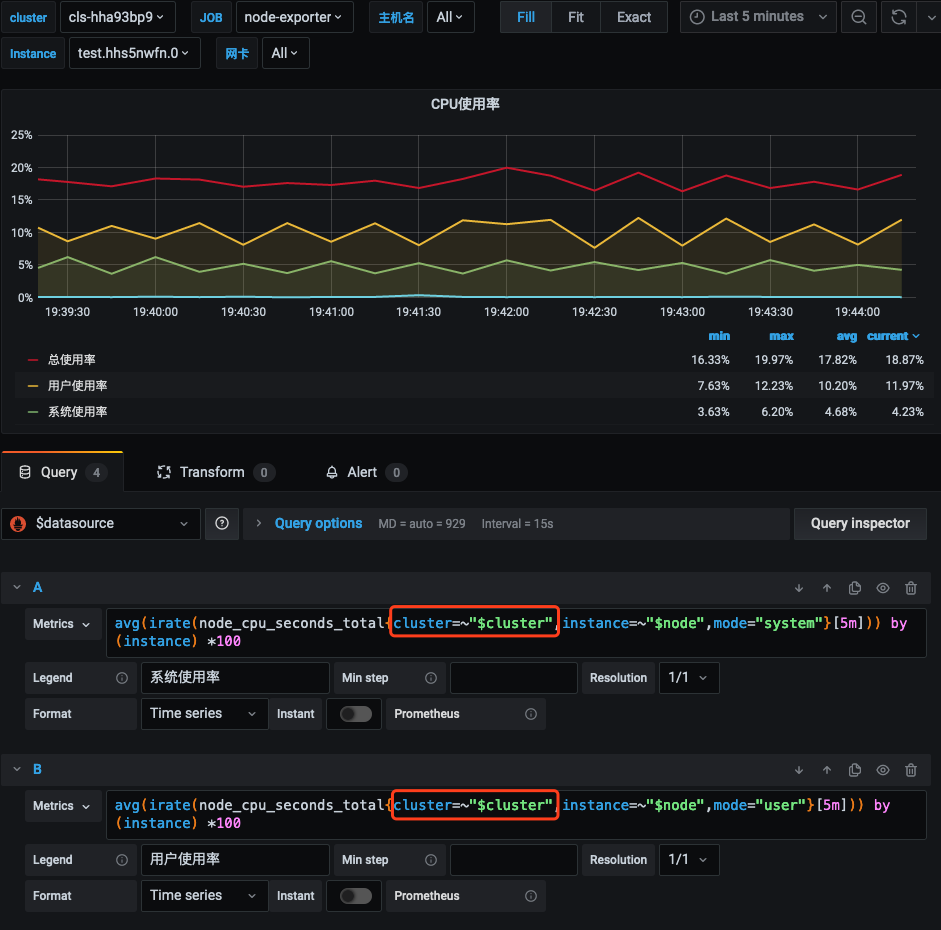
8. 修改所有面板中的 PromQL 查询语句,加入 cluster=~"$cluster" 过滤条件。如下图所示:
与现有系统集成
云原生监控支持接入自建 Grafana 和 AlertManager 系统:
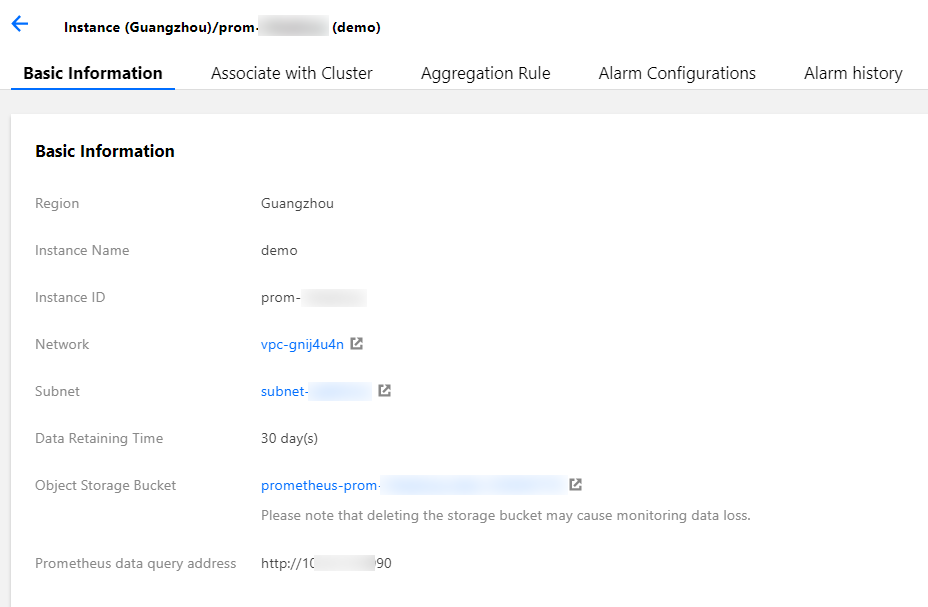
云原生监控提供 Prometheus 的 API,如需使用自建的 Grafana 来展示监控,可以将云原生监控的数据作为一个 Prometheus 数据源添加到自建 Grafana,Prometheus API 的地址可在 TKE 控制台云原生监控基本信息中查到。
2. 在左侧菜单栏中单击 云原生监控进入云原生监控页面。
3. 单击需要配置的云原生监控 ID/名称,进入基本信息页面,获取 Prometheus API 地址。
说明:
确保自建的 Grafana 与云原生监控在同一私有网络 VPC 下或两者网络已打通。
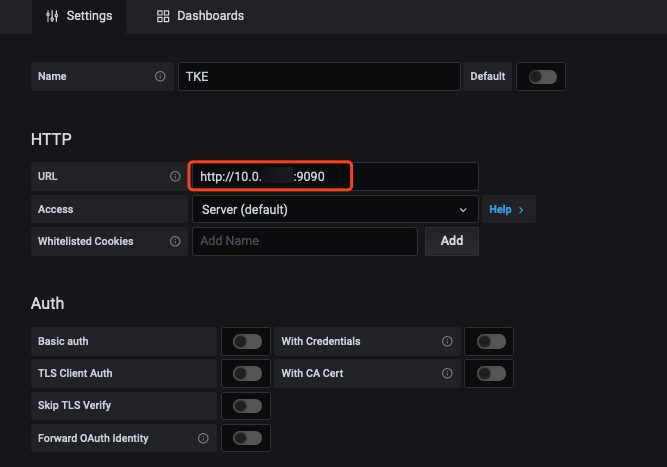
4. 在 Grafana 中添加 Prometheus API 地址作为 Prometheus 数据源。如下图所示:
如需实现更复杂的告警需求,或期望使用自建的 AlertManager 来进行统一告警,可以选择让云原生监控的告警接入自建 AlertManager,您只需在 创建监控实例 时,在高级设置中填入自建 AlertManager 的地址,如下图所示: