tke-monitor-agent 说明
Download
聚焦模式
字号
组件介绍
为了提升容器服务基础监控及告警服务的稳定性,腾讯云升级了基础监控服务架构。新版基础监控会在用户集群的 kube-system 命名空间下部署一个 DaemonSet,名称为 tke-monitor-agent,并创建对应的认证授权 K8s 资源对象 ClusterRole、ServiceAccount、ClusterRoleBinding,名称均为 tke-monitor-agent。
组件作用
该组件会采集每个节点上容器、Pod、节点、以及官方组件的监控数据,该数据源用于控制台基础监控指标展示、指标告警和基于基础指标的 HPA 服务。部署该组件,可极大程度改善之前因基础监控运行不稳定导致的监控数据无法正常获取的问题,获得更稳定的监控、告警及 HPA 服务。
组件影响
部署该组件不会影响集群服务的正常运行。
如果您的节点资源分配不合理或者节点负载过高、节点资源不够,部署基础监控组件时可能会导致监控组件 DaemonSet tke-monitor-agent 对应的 Pod 处于 Pending、Evicted、OOMKilled、CrashLoopBackOff 状态,这属于正常现象。对于 DaemonSet tke-monitor-agent 对应 Pod 出现的意外状态描述如下:
Pending 状态:表示集群的节点上没有足够的资源进行 Pod 的调度,尝试将 DaemonSet tke-monitor-agent 的资源申请量设置为0,可将组件调度上去(详情见 Pod 处于 pending 状态的排错指南)。
Evicted 状态:DaemonSet tke-monitor-agent 的 Pod 如果处于此状态,可能是您的节点资源不够或者节点本身负载就已经过高,可通过如下方式去查看具体的原因,并进行排查和解决:
执行
kubectl describe pod -n kube-system <podName>,通过 Message 字段的描述信息来查看具体被驱逐的原因。执行
kubectl describe pod -n kube-system <podName>,通过 Events 字段描述的信息来查看具体被驱逐的原因。CrashLoopBackOff 或者 OOMKilled 状态:可以通过
kubectl describe pod -n kube-system <podName> 查看是否为 OOM,如果是,可以通过提升 memory limits 的数值解决,limits 值最多不超过100M,如果设置为100M仍然出现 OOM,请 提交工单 来寻求帮助。ContainerCreating 状态:执行命令
kubectl describe pod -n kube-system <pod 名称>,查看 Events 字段。若显示如下内容:Failed to create pod sandbox: rpc error: code = Unknown desc = failed to create a sandbox for pod "<pod 名称 >": Error response from daemon: Failed to set projid for /data/docker/overlay2/xxx-init: no space left on device,则表明容器数据盘已满,清理节点上数据盘后即可恢复。说明:
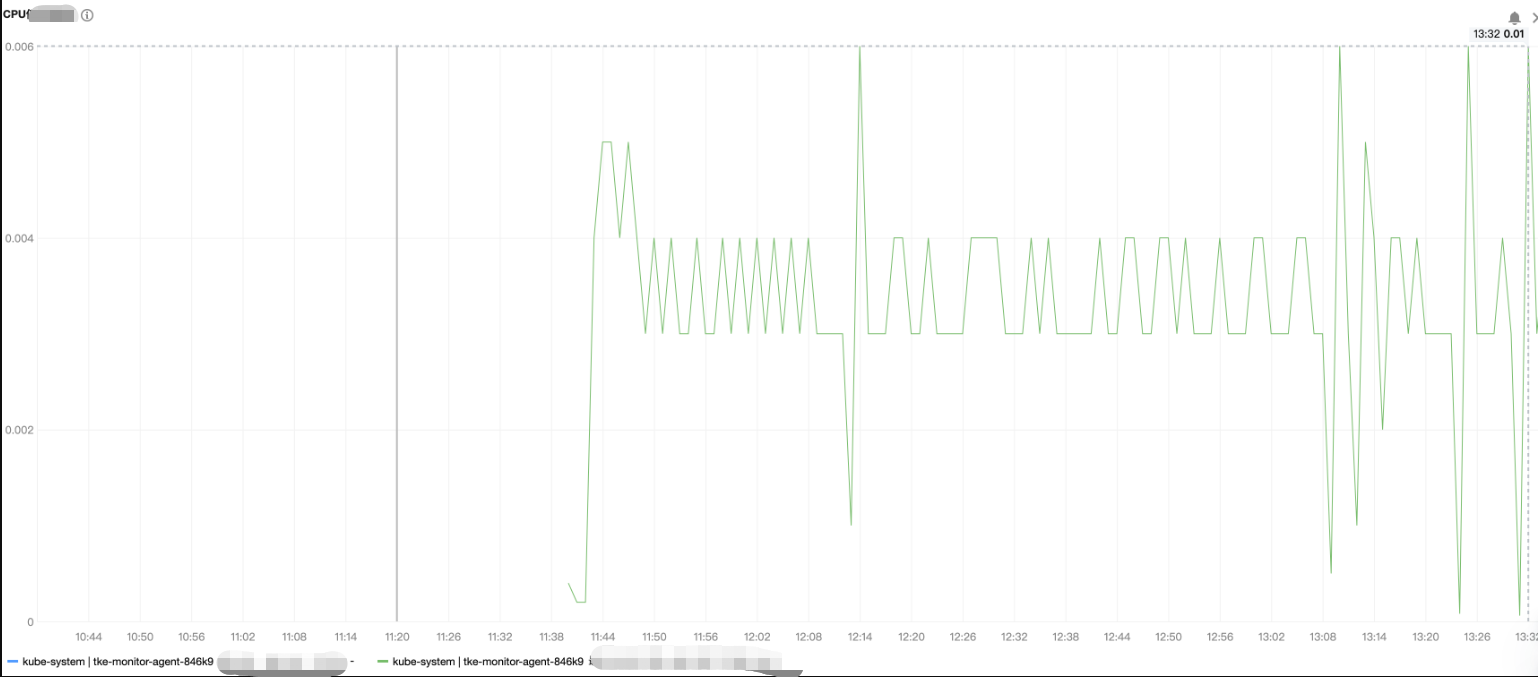
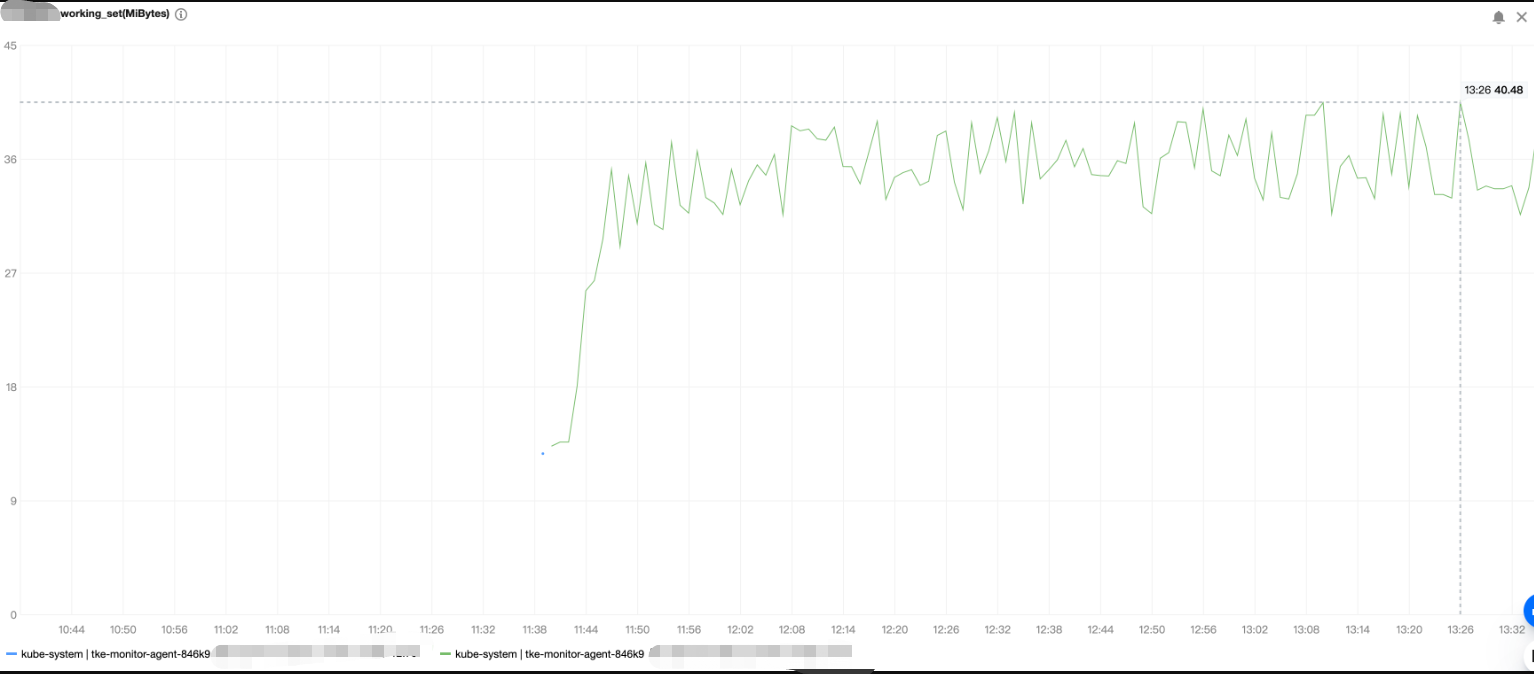
监控组件 DaemonSet(名称为 tke-monitor-agent)所管理的每个 Pod 的资源耗费情况和节点上运行的 Pod 数量和容器数量成正相关,下图为压测示例,内存和 CPU 占用量均很小。
数据规模
节点上有220个 Pod,每个 Pod 有3个容器。
资源消耗
内存(峰值) | CPU(峰值) |
40MiB 左右 | 0.01C |
CPU 使用量压测结果如下:
内存使用量压测结果如下:
组件权限说明
权限说明
该组件权限是当前功能实现的最小权限依赖。
权限场景
功能 | 涉及对象 | 涉及操作权限 |
需要采集集群中 pod 数量和 pod 相关信息 | replicasets、deployments和pods | list/watch |
通过访问节点上 kubelet 的 /metrics 端口获取 cadvisor 的指标信息 | nodes、nodes/proxy、nodes/metrics | list/watch/get |
和 cluster-monitor 传递指标数据 | services | list/watch |
上报指标到 hpa-metrics-server | custommetrics | update |
权限定义
apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRolemetadata:name: tke-monitor-agentrules:- apiGroups: ["apps"]resources: ["replicasets"]verbs: ["list", "watch"]- apiGroups: ["apps"]resources: ["deployments"]verbs: ["list", "watch"]- apiGroups: [""]resources: ["nodes", "nodes/proxy", "nodes/metrics"]verbs: ["list", "watch", "get"]- apiGroups: [""]resources: ["services"]verbs: ["list", "watch"]- apiGroups: [""]resources: ["pods"]verbs: ["list", "watch"]- apiGroups: ["monitor.tencent.io"]resources: ["custommetrics"]verbs: ["update"]
文档反馈