CoreDNS 日志仪表盘使用指南
下载
聚焦模式
字号
TKE 容器服务部署了 CoreDNS 以提供集群内的域名服务解析。由于网络故障或者 CoreDNS 负载压力过大等多种原因,可能会出现 DNS 请求异常、请求延迟高以及多副本 CoreDNS 请求不均衡等多种问题,从而影响用户正常业务的 DNS 请求。为了快速排查 DNS 异常,发现潜在的业务和安全隐患,TKE 基于 CoreDNS 的 log 插件和 CLS 日志平台构建了全面的 CoreDNS 日志能力。本文将指导您如何在 TKE 集群中启用 CoreDNS 日志,并利用相应的仪表盘功能进行问题排查。
前置条件
1. 集群需要开启日志服务。
2. CoreDNS 相关的 Corefile 配置中需要添加 log 插件。
说明:
请按照下面的方式添加 Corefile 配置中的 log 插件,编辑 kube-system 下的 coredns 名称的 configmap。
data:Corefile: |2-.:53 {template ANY HINFO . {rcode NXDOMAIN}log #请在此处添加 log 插件errorshealth {lameduck 30s}readykubernetes cluster.local. in-addr.arpa ip6.arpa {pods insecurefallthrough in-addr.arpa ip6.arpa}prometheus :9153forward . /etc/resolv.conf {prefer_udp}cache 30reloadloadbalance}kind: ConfigMap
保存配置后退出,Corefile 会被自动 reload;如果 Corefile 没有配置 reload,需要重建 CoreDNS 以使配置生效。
3. 确保集群 CoreDNS 版本 >= 1.8.4。如果需要升级 CoreDNS 版本到 1.8.4,请参见 升级到 1.8.4。
开启 CoreDNS 日志
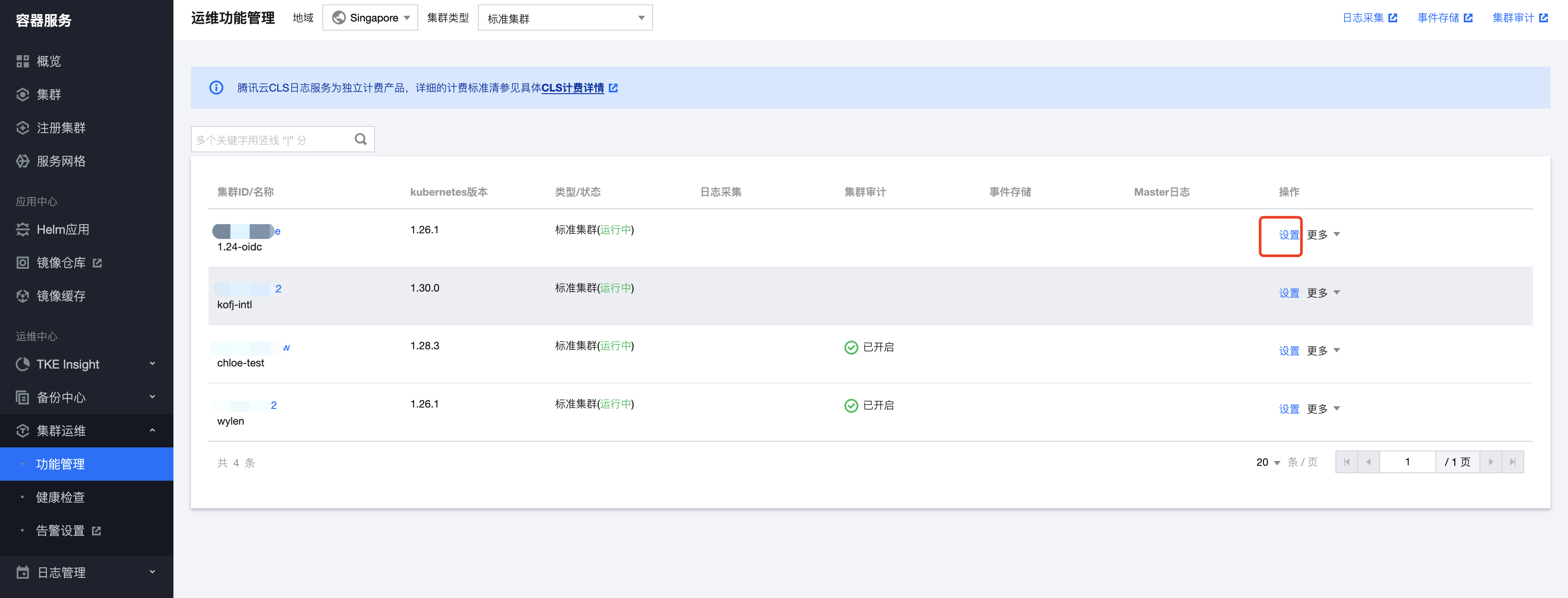
1. 登录 容器服务控制台,选择左侧导航栏中的运维功能管理。
2. 选择您需要开启 CoreDNS 日志的集群,单击集群右侧的设置。如下图所示:
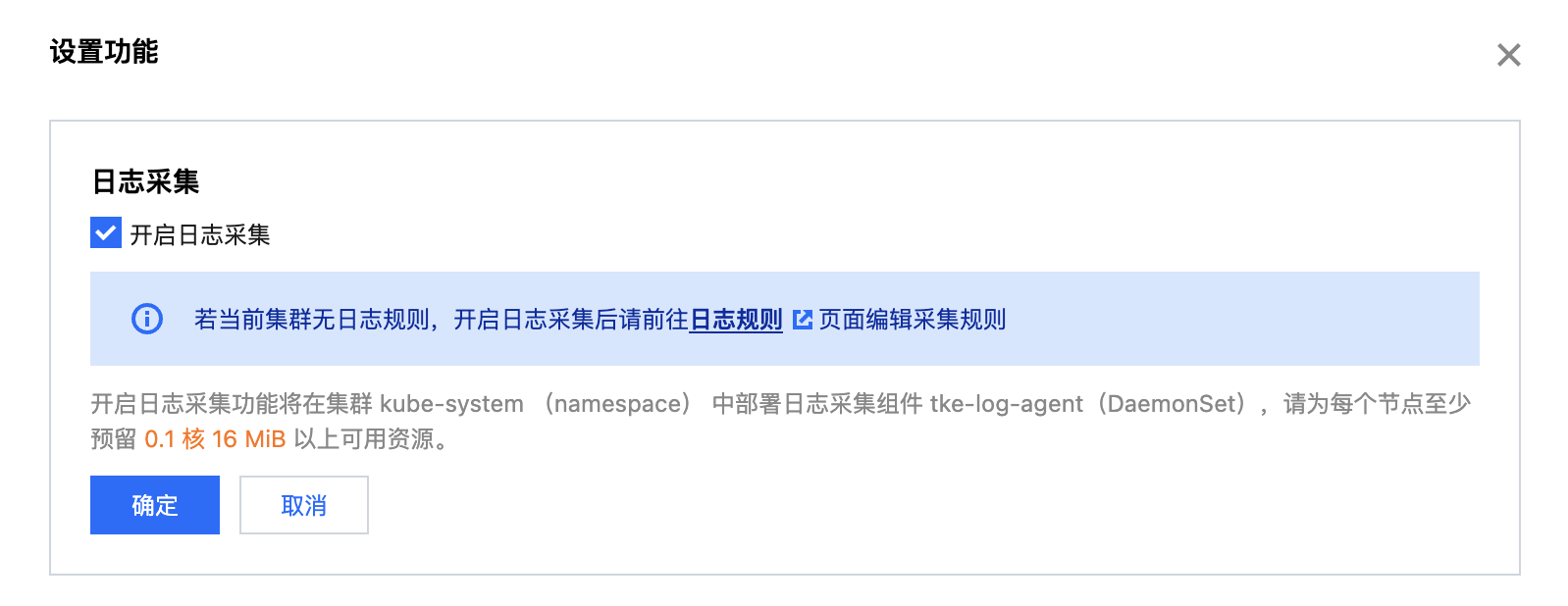
3. 在设置功能页面,单击日志采集右侧的编辑。
4. 勾选开启日志采集,单击确定。如下图所示:
注意:
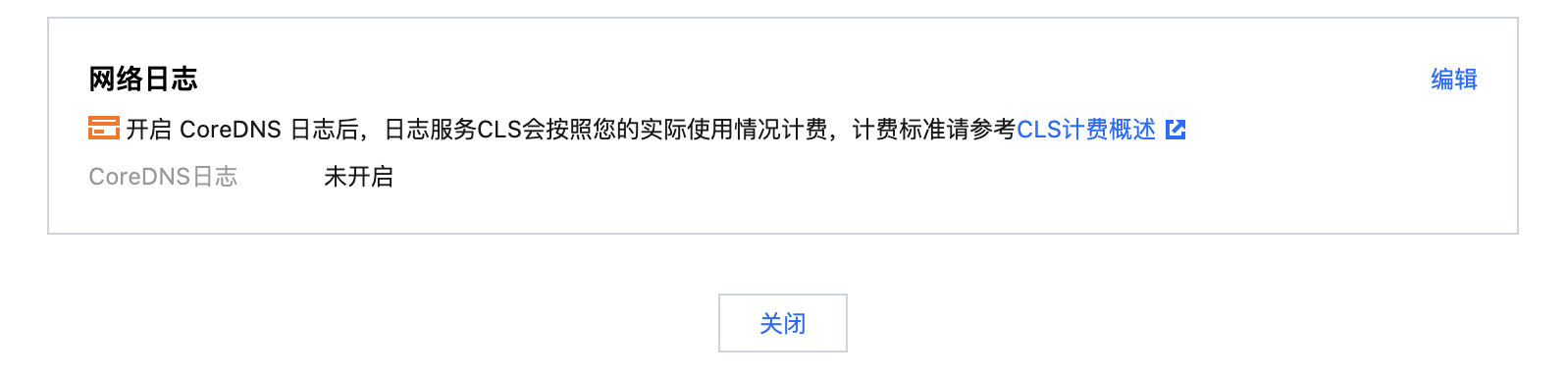
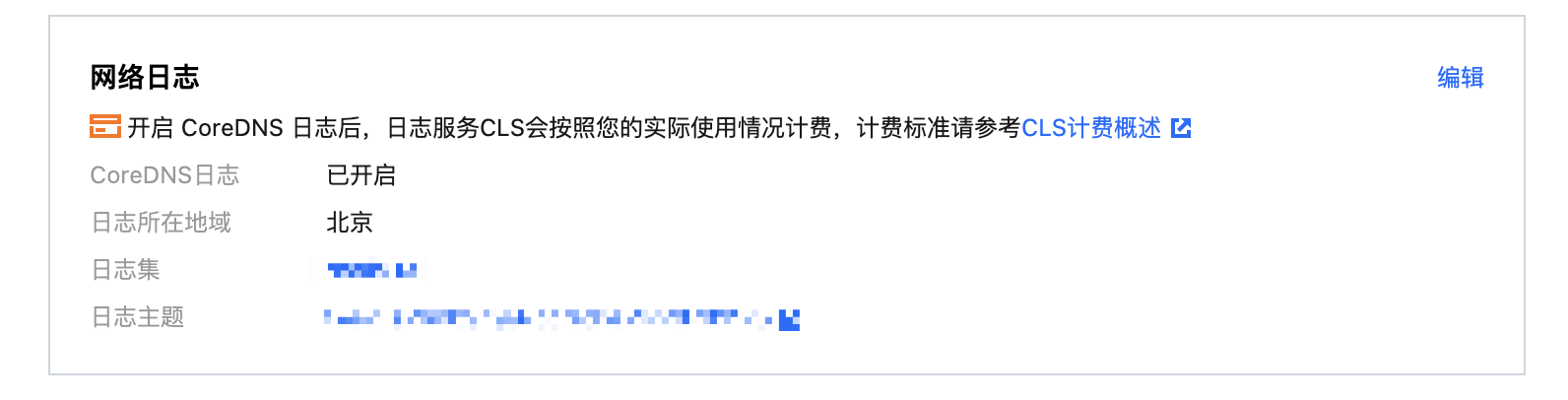
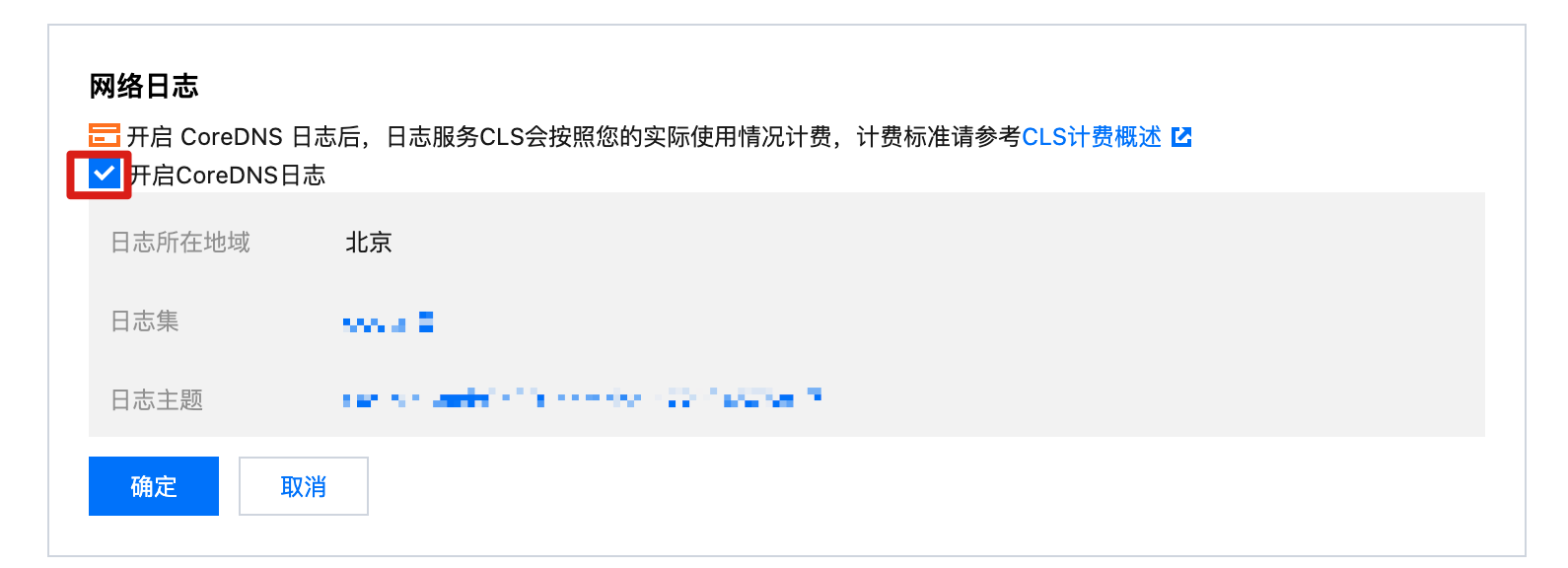
5. 单击网络日志右侧的编辑。如下图所示:
6. 勾选开启 CoreDNS 日志,并输入以下信息:
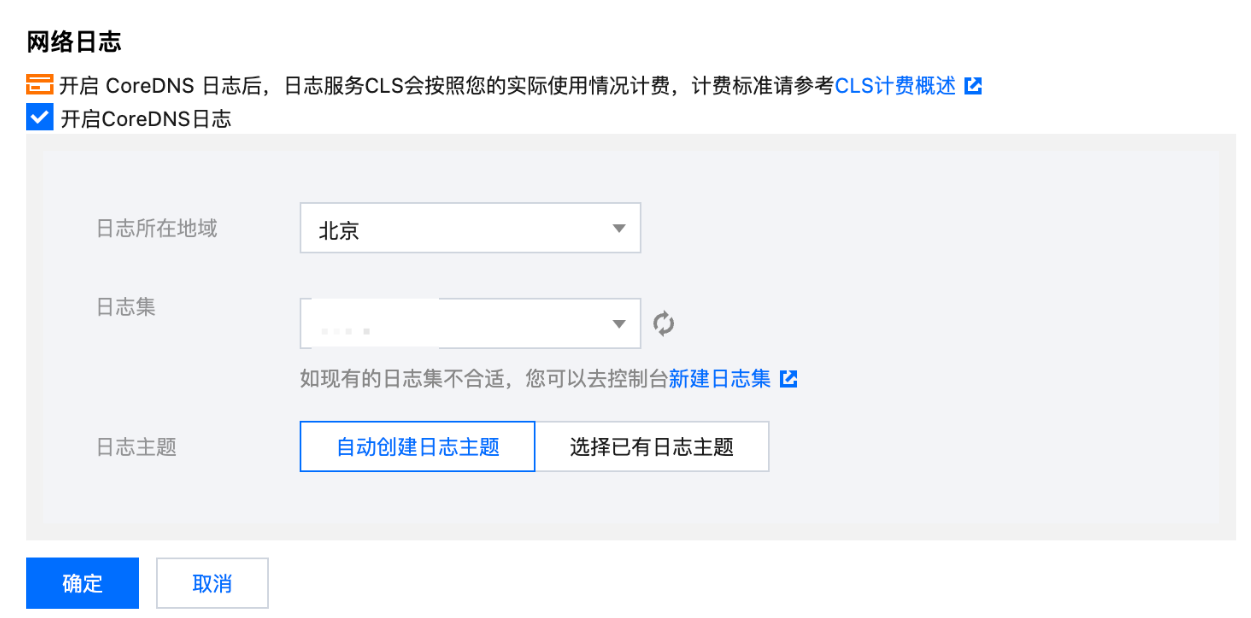
日志所在地域:选择 cls 日志集存储地域。
日志集:选择 cls 日志集名称。如果没有合适的日志集,可以新建日志集。
日志主题:可以选择自动创建日志主题,或者选择已有的日志主题。
7. 单击确定,完成 CoreDNS 日志开启。
单击日志主题链接,进入 CLS 页面进行日志检索等操作。日志索引字段含义如下:
字段名称 | 字段含义 | 示例 |
class | 请求类别。 | IN |
do | 查询中是否设置了 "DNSSEC OK"(DNS 安全扩展确认)。 | false |
duration | 响应时间(单位秒)。 | 0.000098921 |
id | 请求 ID,标识特定的 DNS 请求和响应。 | 30008 |
level | 日志级别。 | INFO |
name | DNS 请求中查询的目标域名。 | craned.crane-system.svc.cluster.local. |
port | 发送 DNS 请求的客户端端口。 | 50424 |
proto | 使用协议。 | udp |
rcode | 响应代码。 | NXDOMAIN |
remote | 客户端 IP 地址。 | 10.99.10.128 |
rflags | 响应报文中的标志字段,用于表示 DNS 查询的状态和结果。 | qr,aa,rd |
rsize | 限制 DNS 响应的最大值。 | 162 |
size | 限制 DNS 请求的最大值。 | 69 |
bufsize | DNS 请求和响应的内部缓冲区大小。 | 65535 |
type | 请求类型。 | A |
在日志管理中使用 CoreDNS 仪表盘
1. 登录 容器服务控制台,选择左侧导航栏中的日志管理 > CoreDNS 日志。
2. 进入 CoreDNS 日志页面,选择地域,集群类型,和您需要查看的集群。如下图所示:
3. 查看仪表盘数据。如下图所示:
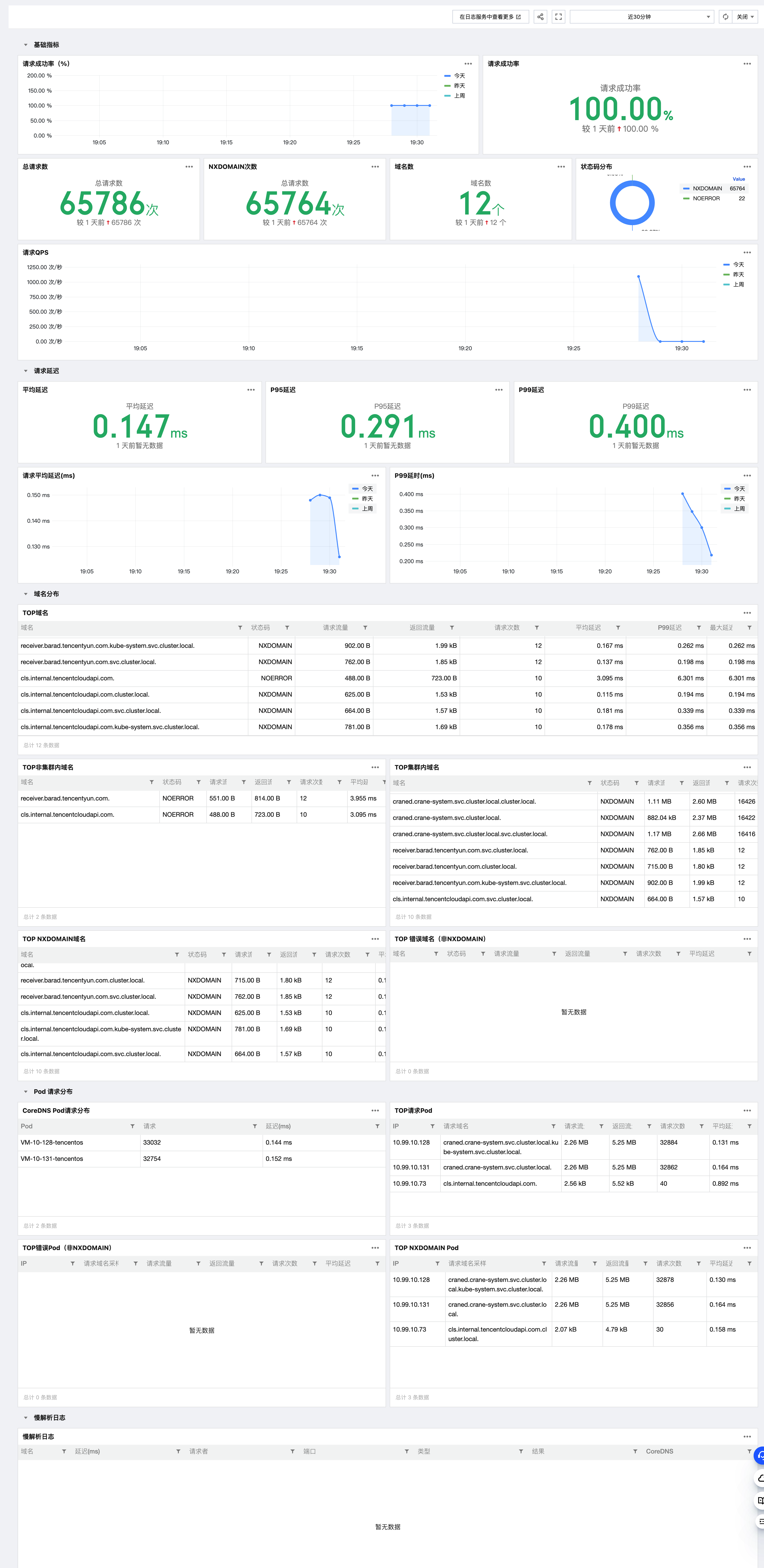
请求成功率:统计所有 DNS 响应正常数目(NOERROR 和 NXDOMAIN)占总请求的比例。用户可以根据此指标,发现当前 CoreDNS 是否存在解析失败的情况。
域名数:当前 CoreDNS 服务中响应的域名总数。
请求 QPS:反应一段时间周期内,CoreDNS 服务的 QPS 性能情况(请求次/秒)。用户可以根据此时序图,定位 CoreDNS 相应的性能问题。
平均延迟/P95 延迟/P99 延迟:通过最近1w个请求的延迟,反应 CoreDNS 服务的平均延迟/P95和 P99 延迟,用于定位 CoreDNS 响应慢的问题。
CoreDNS Pod 请求分布:多副本 CoreDNS 的情况下,此表格可以展示每个副本的请求分布数以及平均延迟,用于定位 CoreDNS 副本请求不均的问题。
慢解析日志:当 DNS 请求的处理时间超过特定阈值时,CoreDNS 会在慢解析日志中记录相关信息。通过分析慢解析日志,用户可以发现哪些类型的请求最耗时,然后针对这些问题进行优化。
关闭 CoreDNS 日志
如果您不再需要 CoreDNS 日志采集,可以通过下面的方式关闭 CoreDNS 日志采集能力:
1. 登录 容器服务控制台,选择左侧导航栏中的运维功能管理。
2. 选择您需要关闭 CoreDNS 日志的集群,单击集群右侧的设置。
3. 在设置功能页面,单击网络日志右侧的编辑。如下图所示:
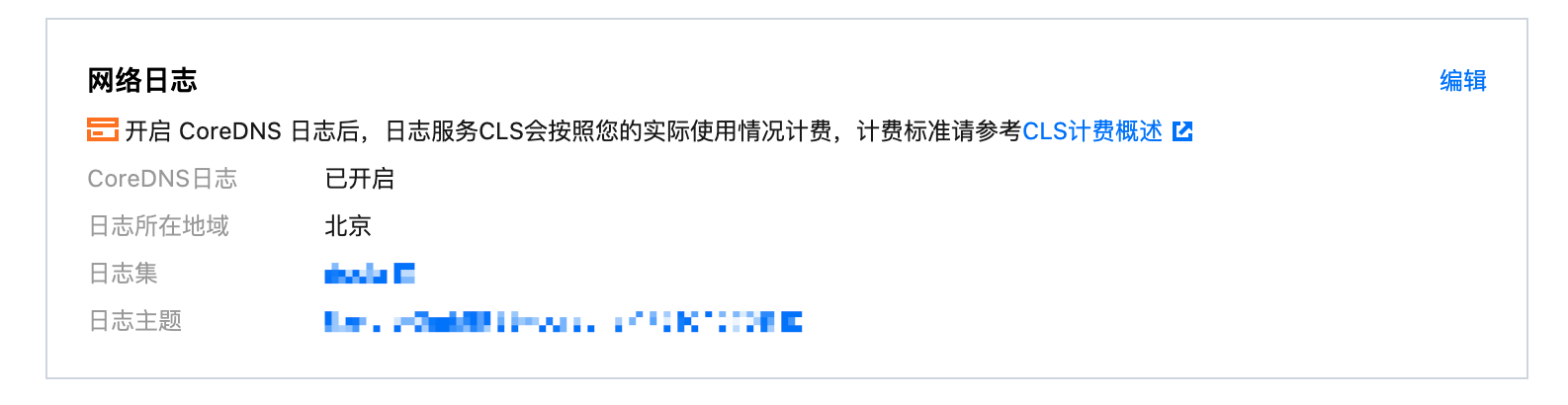
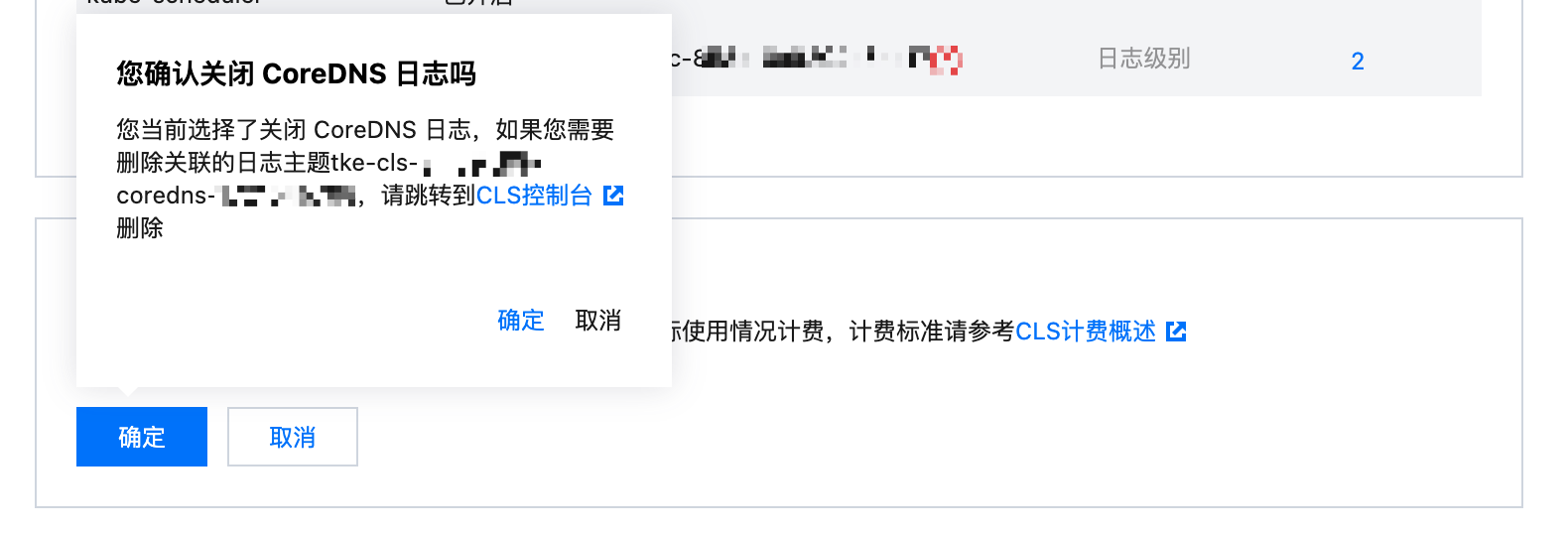
4. 取消选择开启 CoreDNS 日志。如下图所示:
5. 单击确定。如果是自动创建的日志主题,这里会提示有关联的日志主题,如果您不再需要该日志主题,请单击跳转到 CLS 控制台删除相应的日志主题。否则关联的日志主题会一直保存,产生相应的计费。
文档反馈