监控和告警配置
Download
聚焦模式
字号
概述
云原生 etcd 默认为您提供节点资源使用率、集群业务指标、实例级别指标、实例接口四个维度的监控指标数据,均支持设置告警,此外,如果您有自定义监控指标展示的需求,也支持使用 Prometheus 监控 作为额外的监控服务,配置自定义的监控指标。
前提条件
操作步骤
1. 登录 云原生 etcd 控制台。
2. 进入 etcd 集群列表页面,在页面上方选择相关地域,在下方集群列表中找到您需要操作的 etcd 集群。
查看监控指标
可从实例列表页,单击对应集群 
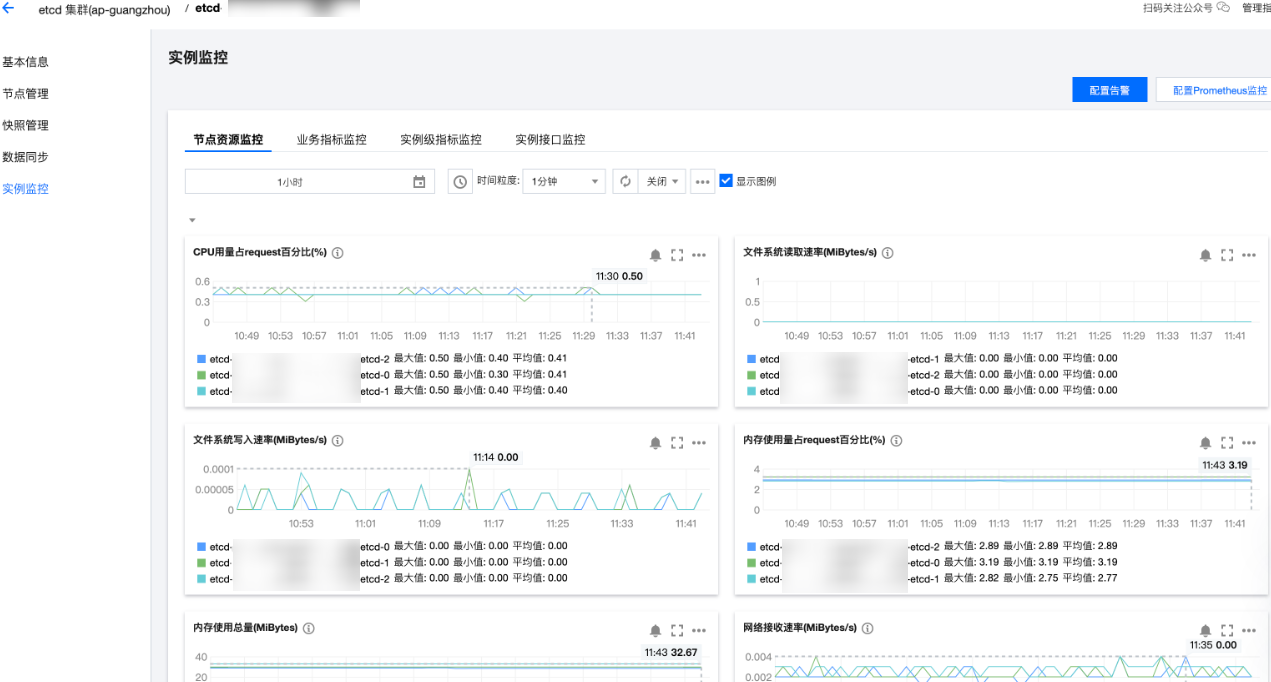
指标释义
聚合方式:

1. 时长:监控图表中展示的数据所属时间范围。
2. 粒度:图表中每个数据点的聚合方式,原始数据默认为15s采集一次,控制台可选择按1分钟、5分钟聚合展示平均值。
3. 自动刷新:图表自动刷新的周期,支持按30s/5min/30min/1h自动刷新图表,默认关闭。
指标概览:
指标维度 | 指标名称 | 单位 | 指标说明 |
节点资源 | CPU 用量占 request 百分比 | 百分比 | 节点当前 CPU 用量占用当前节点 Pod CPU request 值(用户创建实例时选择的 CPU 规格)的比例 |
节点资源 | 文件系统读取速率 | MiBytes/s | 节点数据盘读操作每秒数据量 |
节点资源 | 文件系统写入速率 | MiBytes/s | 节点数据盘写操作每秒数据量 |
节点资源 | 内存使用量占 request 百分比 | 百分比 | 节点内存当前用量占 Pod MEM request 值(用户创建实例时选择的内存规格)的比例 |
节点资源 | 内存使用总量 | MiBytes | 节点内存使用量 |
节点资源 | 网络接收速率 | MiBytes | 节点网卡数据接收速率 |
节点资源 | 网络发送速率 | MiBytes | 节点网卡数据发送速率 |
业务指标 | 数据库 key 数量 | 个 | 节点中 key 的数量,数据来源 etcd metrics,计算公式:etcd_debugging_mvcc_keys_total{job="$job"} |
业务指标 | 数据库 MVCC 写入次数 | 次 | 节点中数据写入次数,计算公式:etcd_mvcc_put_total{job="$job"} |
业务指标 | 数据库大小 | MiBytes | 节点中统计的数据库大小,计算公式:etcd_debugging_mvcc_db_total_size_in_bytes{job="$job"} |
业务指标 | 共识提议 apply 速率 | 次/s | 通常应该很小(即使在高负载下也只有几千个)。如果指标差异持续上升,则表明 etcd 服务器过载。可能是高耗查询导致的(如大范围查询或大型 txn 操作),计算公式:rate(etcd_server_proposals_applied_total{job="$job"}[5m]) |
业务指标 | 共识提议 commit 速率 | 次/s | 通常会随着时间的推移而增加,单个 member 与 leader 之间持续较大的延迟表明该成员运行缓慢或不健康,计算公式:rate(etcd_server_proposals_committed_total{job="$job"}[5m]) |
业务指标 | 排队等待共识提议总量 | 个 | 该指标上升表示存在高客户端负载或成员无法提交提议,计算公式:etcd_server_proposals_pending{job="$job"} |
业务指标 | 失败共识提议增长速率 | 次/s | 该指标通常与两个问题有关:与 leader 选举相关的临时故障或由于集群中的仲裁损失而导致的较长时间故障,计算公式:ate(etcd_server_proposals_failed_total{job="$job"}[5m]) |
实例级指标 | 集群是否有 Leader | 布尔值 | 如果没有 leader ,则实例不可用,计算公式:max(etcd_server_has_leader{job="$job"}) |
实例级指标 | Leader 切换总次数 | 次 | 如果没有 leader,频繁的 leader 变动会显着影响 etcd 的性能,可能是由于网络连接问题或 etcd 集群的负载过大,计算公式:max(etcd_server_leader_changes_seen_total{job="$job"}) 说明: 当前指标采集的数据为实例创建成功后的汇总值,和告警周期的选择无关。 |
实例接口监控 | gRPC 调用速率 | 次/s | 特定 method 操作的 grpc 调用速率,计算公式:sum(rate(grpc_server_handled_total{job="$job"}[1m])) by (job,grpc_method,instance) |
文档反馈