设置分区策略
Download
聚焦模式
字号
操作场景
当用户选择 Kafka 多分区时,可以通过设置分区策略,将业务相互关联的数据路由到同一个分区中,这样方便用户处理消费数据。DTS 支持按表名、按表名+主键、按列名进行分区,将订阅数据经过哈希规则路由到 Kafka 各分区。
Kafka 分区策略 - 按表名分区:将源库的订阅数据按照表名进行分区,设置后相同表名的数据会写入同一个 Kafka 分区中。在数据消费时,同一个表内的数据变更总是顺序获得。
Kafka 分区策略 - 按表名+主键分区:将源库的订阅数据按照表名+主键进行分区,适用于热点数据,设置后热点数据的表,通过表名+主键的方式将数据分散到不同分区中,提升并发消费效率。
自定义分区策略:先通过正则表达式对订阅数据中的库名和表名进行匹配,匹配后的数据再按照表名、表名+主键、列进行分区。
Kafka 分区策略
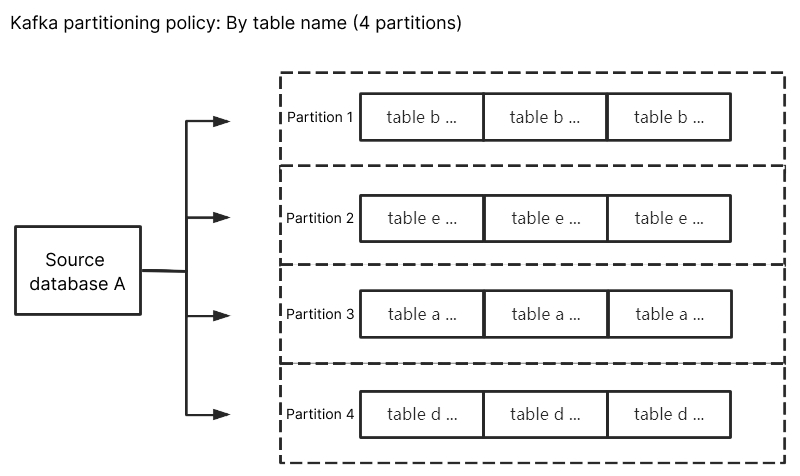
按表名分区
当源数据库变更时,将变更的数据写入订阅 Topic 中,选择按表名分区后,相同表名的订阅数据会写入同一个 Kafka 分区中。在消费数据时,可以保证同一个表内的数据变更总是顺序获得。
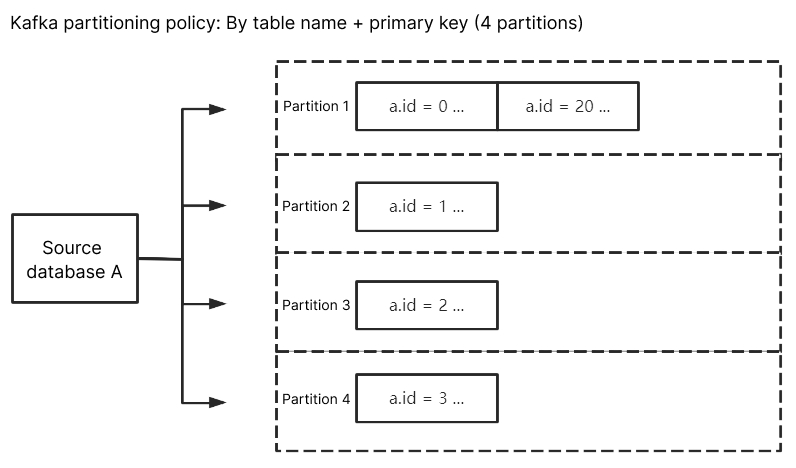
按表名+主键分区
当仅指定按照表名分区时,如果一张表为热点数据,则按照表名分区,该 Kafka 分区的压力会非常大。通过表名+主键分区将数据分散到不同分区中,提升并发消费效率。
自定义分区策略
自定义分区策略,是通过正则表达式对库名和表名进行匹配,匹配后的数据再按照表名、表名+主键、列进行分区。
匹配规则
库表、表名的匹配规则支持 RE2 正则表达式,具体语法请参考 语法说明。
库名的匹配规则,按照正则表达式来匹配库名。表名的匹配规则,按照正则表达式来匹配表名的数据。如果库名和表名需要精确匹配,需要加开始和结束符,如
test 表应该为 ^test$。列名的匹配规则,按照等值
== 来匹配,大小写不敏感。优先匹配自定义分区策略,当自定义分区策略未匹配到时,则应用 Kafka 分区策略的设置进行匹配。当自定义分区策略有多条时,自上向下逐条匹配。
按表名分区
库名匹配模式填入
^A$,表名匹配模式填入 ^test$,选择按表名分区后,A 库中 test 的订阅数据会写入到同一个分区中,test 除外其他未匹配到的库表数据会根据 Kafka 分区策略中设置的策略进行写入。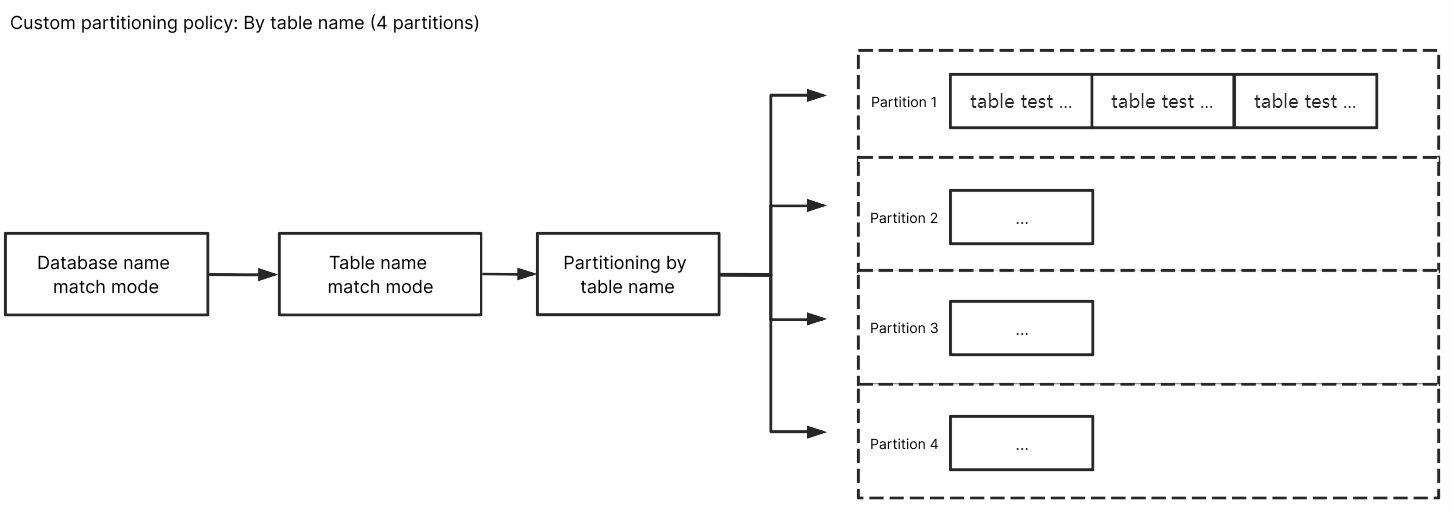
按表名+主键分区
库名匹配模式填入
^A$,表名匹配模式填入 ^test$,选择按表名+主键分区后,A 库中 test 的订阅数据会根据主键数据的不同,随机写入到不同的分区中,最终主键数据相同的数据都写入了同一个分区。test 除外其他未匹配到的库表数据会根据 Kafka 分区策略中设置的策略进行写入。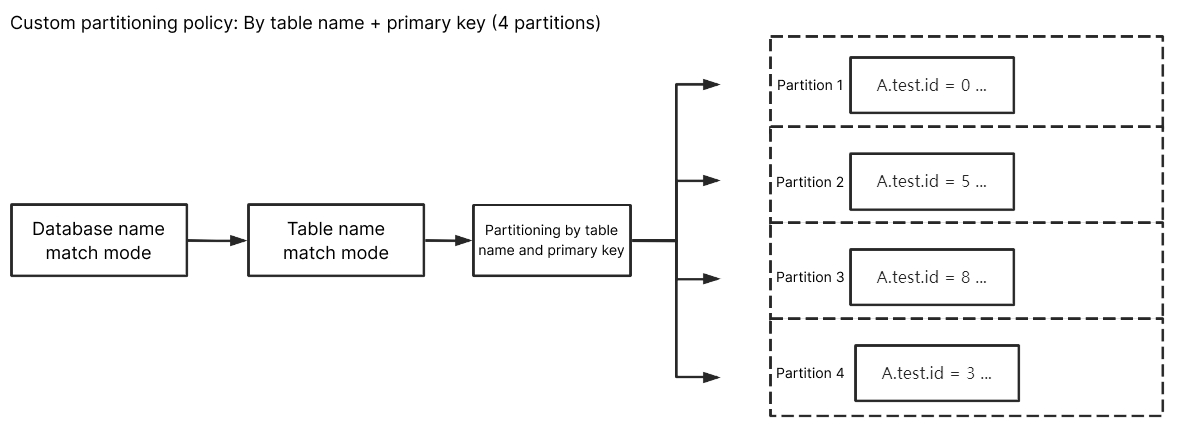
按列分区
库名匹配模式填入
^A$,表名匹配模式填入 ^test$,自定义分区列填入class,选择按列名分区后,A 库中 test 列名为 class 的订阅数据将被随机写入到不同分区中。test 除外其他未匹配到的库表数据会根据 Kafka 分区策略中设置的策略进行写入。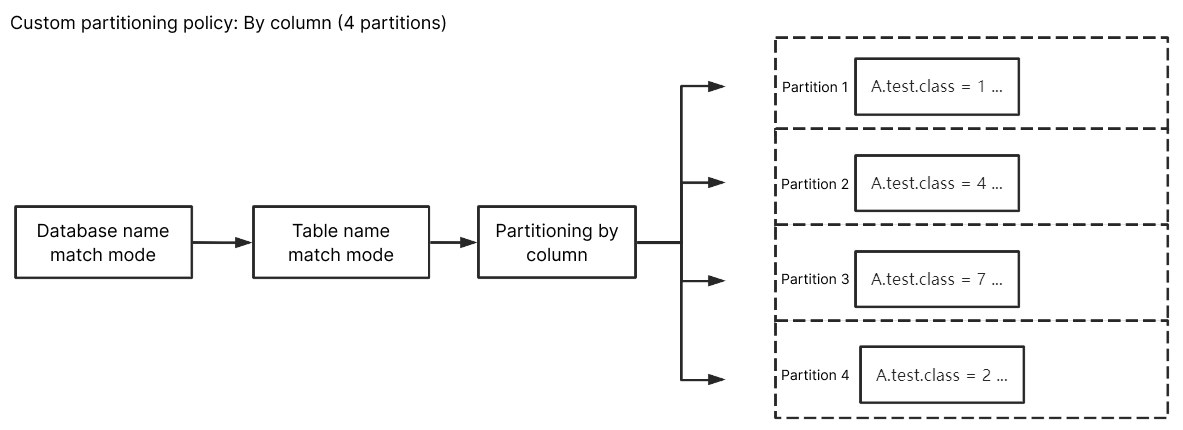
文档反馈