数据投递到 Kafka 策略设置
Download
聚焦模式
字号
操作场景
源端数据同步到 Kafka 时,支持灵活的投递策略,可以将不同表的数据投递到不同的 Topic 中,也可以集中投递到单 Topic 中。不同策略的说明如下:
策略类别 | 单 Topic 分区策略 | 功能场景 |
自定义 Topic 名称 | 不涉及 | 可将不同的库、表数据投递到不同的 Topic 中。 |
集中投递到单 Topic | Topic 分区策略(默认分区策略) | 全部投递至 Partition0:全部投递到单 Topic 中的第一个分区。 按表名分区:将同一个表的数据投递到同一个分区。 按表名 + 主键分区:将同一个表中相同主键值的数据投递到同一个分区。适用于热点数据,设置后热点数据的表,可以分散投递到不同分区。 |
| Topic 分区策略(默认分区策略)+自定义分区策略 | 1. 先将匹配到的库、表数据,按照自定义分区策略(支持按表名分区、按表名+主键分区、按列分区)进行投递。 2. 再将剩余未匹配到的库、表数据,按照 Topic 分区策略(默认分区策略),进行投递。 |
自定义 Topic 名称
功能说明
用户自行设置投递的 Topic 名称,DTS 按照填入的 Topic 名称往目标端 Kafka 写入:
如果目标端有该 Topic,或者没有该 Topic 但是 auto.create.topics.enable = ture,DTS 会写入成功。
如果目标端没有该 Topic,并且 auto.create.topics.enable = false,则 DTS 写入失败,同时同步任务会报错。
auto.create.topics.enable 为 Kafka 中的配置参数,用于控制是否允许自动创建 Topic,通常在 Kafka 的配置文件 server.properties 中修改。当设置为 true 时,Kafka 在收到不存在的 Topic 的请求时会自动创建该 Topic。当设置为 false 时,不会自动创建 Topic。
配置规则
选择自定义 Topic 名称,用户设置了多条规则时,DTS 会从上到下逐条匹配。
如果匹配到设置的规则(源端的库名和表名都符合设置的规则),则会投递到该条规则对应的 Topic 中。
如果匹配到多条规则,则会投递到所有匹配规则的 Topic 中。
剩余没有匹配到设置规则的数据,则会投递到最后一条规则的 Topic 中。
匹配规则对库名、表名大小写敏感。
如果源库设置 lower_case_table_names = 0,则设置的匹配规则中库表名需要与源库中的名称大小写严格保持一致。
如果源库设置 lower_case_table_names = 1,则库表名统一转换为小写,设置的匹配规则中库表名统一输入小写。
库表、表名的匹配规则支持 RE2 正则表达式,具体语法请参考 语法说明。如果需要精确匹配,则要加开始符“^”和结束符“$”,如精准匹配“test”表应该为“^test$”。
配置示例
数据库实例 X 中,Users 库里有表 Teacher 、Student、Student1、Student2、Student3。
示例一:将 Users 库中的数据都投递到 Topic_A 中,剩余的数据投递到 Topic_default 中。
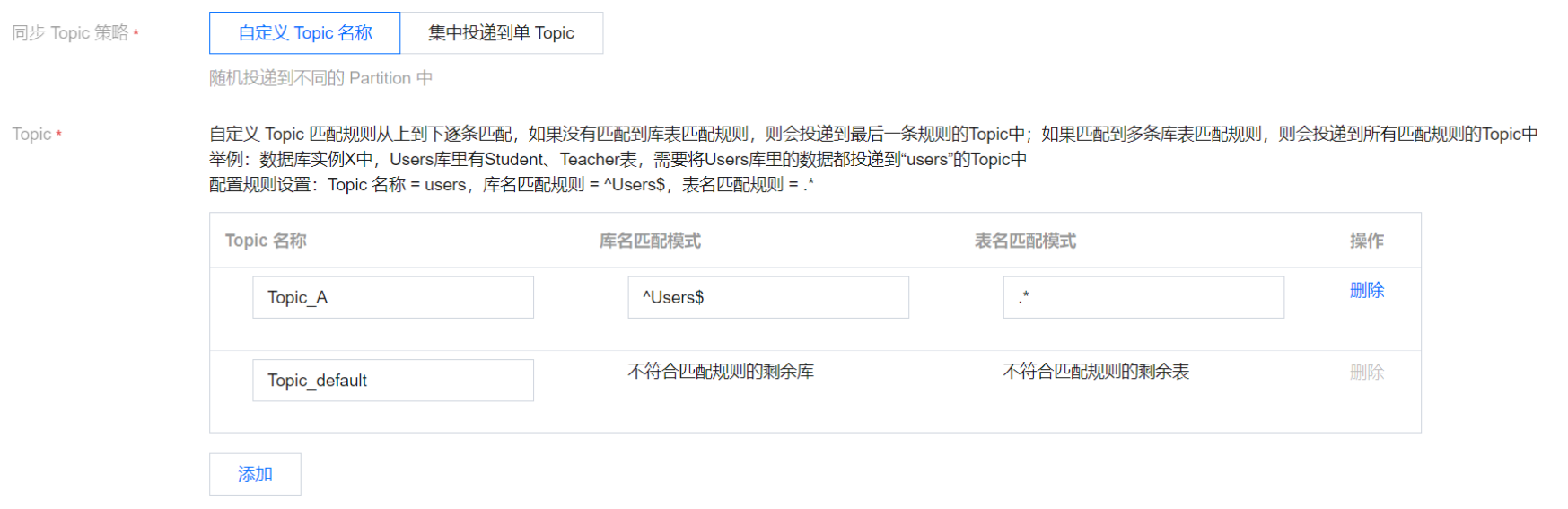
Topic 名称 | 库名匹配模式 | 表名匹配规模式 | 说明 |
Topic_A | ^Users$ | .* | “^Users$”表示精准匹配Users库,“^”为开始符,“$”为结束符;仅填入“Users”表示匹配所有包含Users的库名,如表X_Users_1会匹配上。 “.*”表示匹配所有的表名。 |
Topic_default | 不符合匹配规则的剩余库 | 不符合匹配规则的剩余表 | - |
示例二:将“Teacher”表的数据投递到“Topic_A”,“Student”表的数据投递到“Topic_B”,剩余数据投递到“Topic_default”。
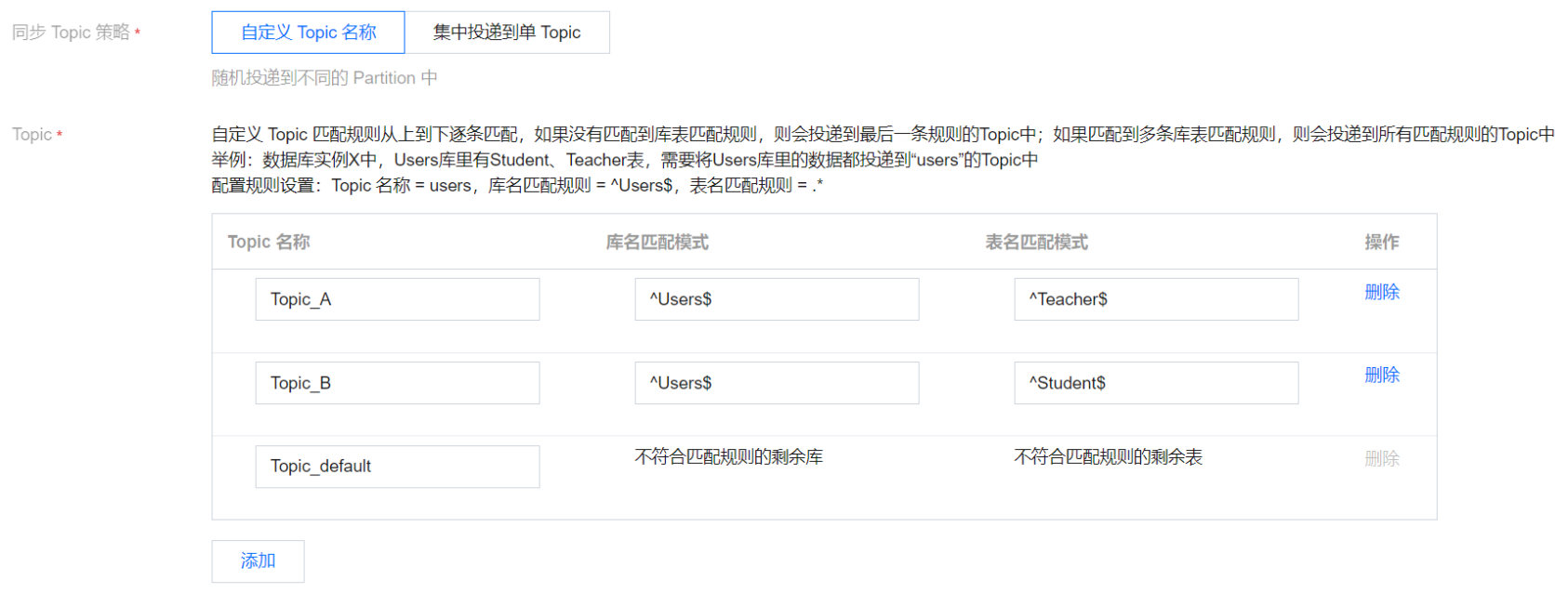
Topic 名称 | 库名匹配模式 | 表名匹配规模式 | 说明 |
Topic_A | ^Users$ | ^Teacher$ | “^Teacher$”表示精准匹配表名 Teacher,“^”为开始符,“$”为结束符;如果仅填入“Teacher”,则会匹配包含 Teacher 的所有表,如 F_Teacher_1会匹配到。 |
Topic_A | ^Users$ | ^Student$ | - |
Topic_default | 不符合匹配规则的剩余库 | 不符合匹配规则的剩余表 | - |
示例三:将“Teacher”表数据投递到“Topic_A ”中,前缀为“Student”的表(即表Student、Student1、Student2、Student3)都投递到“Topic_B”,剩余数据投递到“Topic_default”。
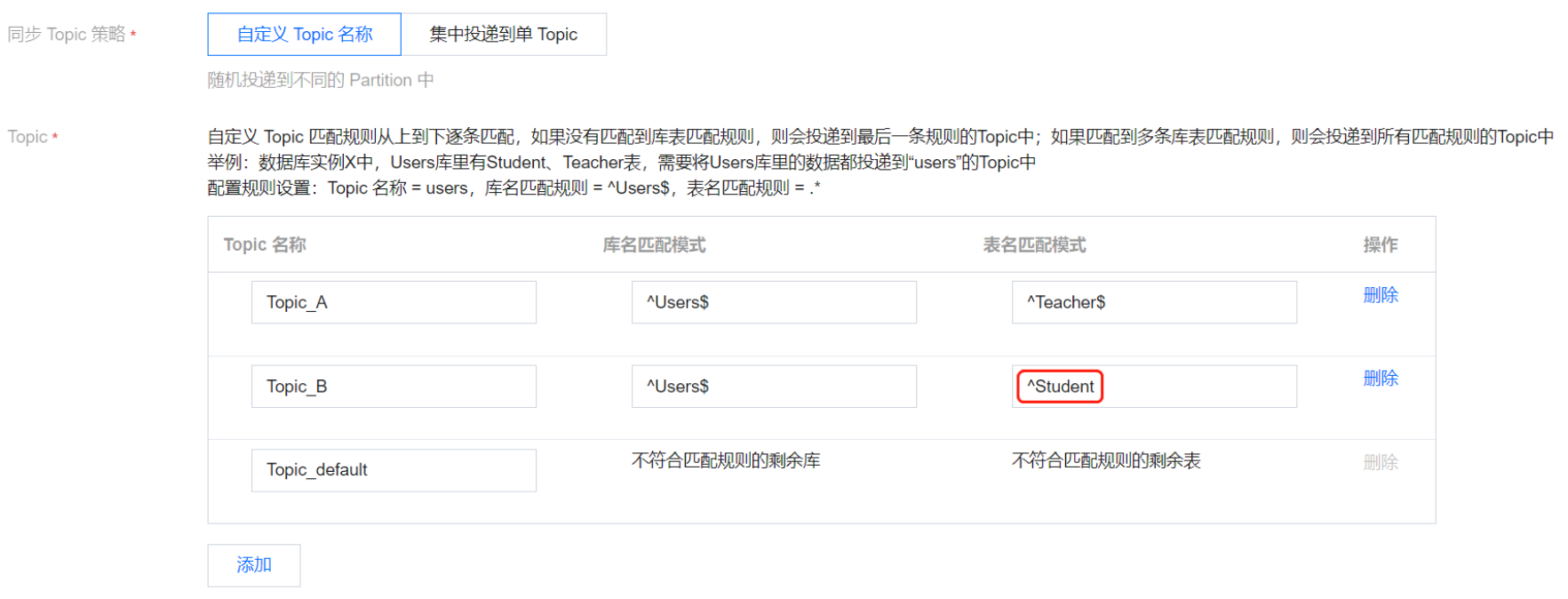
Topic 名称 | 库名匹配模式 | 表名匹配规模式 | 说明 |
Topic_A | ^Users$ | ^Teacher$ | - |
Topic_A | ^Users$ | ^Student | “^Student”表示匹配所有前缀为 Student 的表,即 Student、Student1、Student2、Student3都匹配。 |
Topic_default | 不符合匹配规则的剩余库 | 不符合匹配规则的剩余表 | - |
集中投递到单 Topic(默认分区策略)
选择一个目标端已有的 Topic,然后按照多种分区策略投递,支持“单分区”、“按表名分区”、“按表名 + 主键分区”。
全部投递至 Partition0(即单分区)
将源库的同步数据全部投递到单 Topic 中的第一个分区。
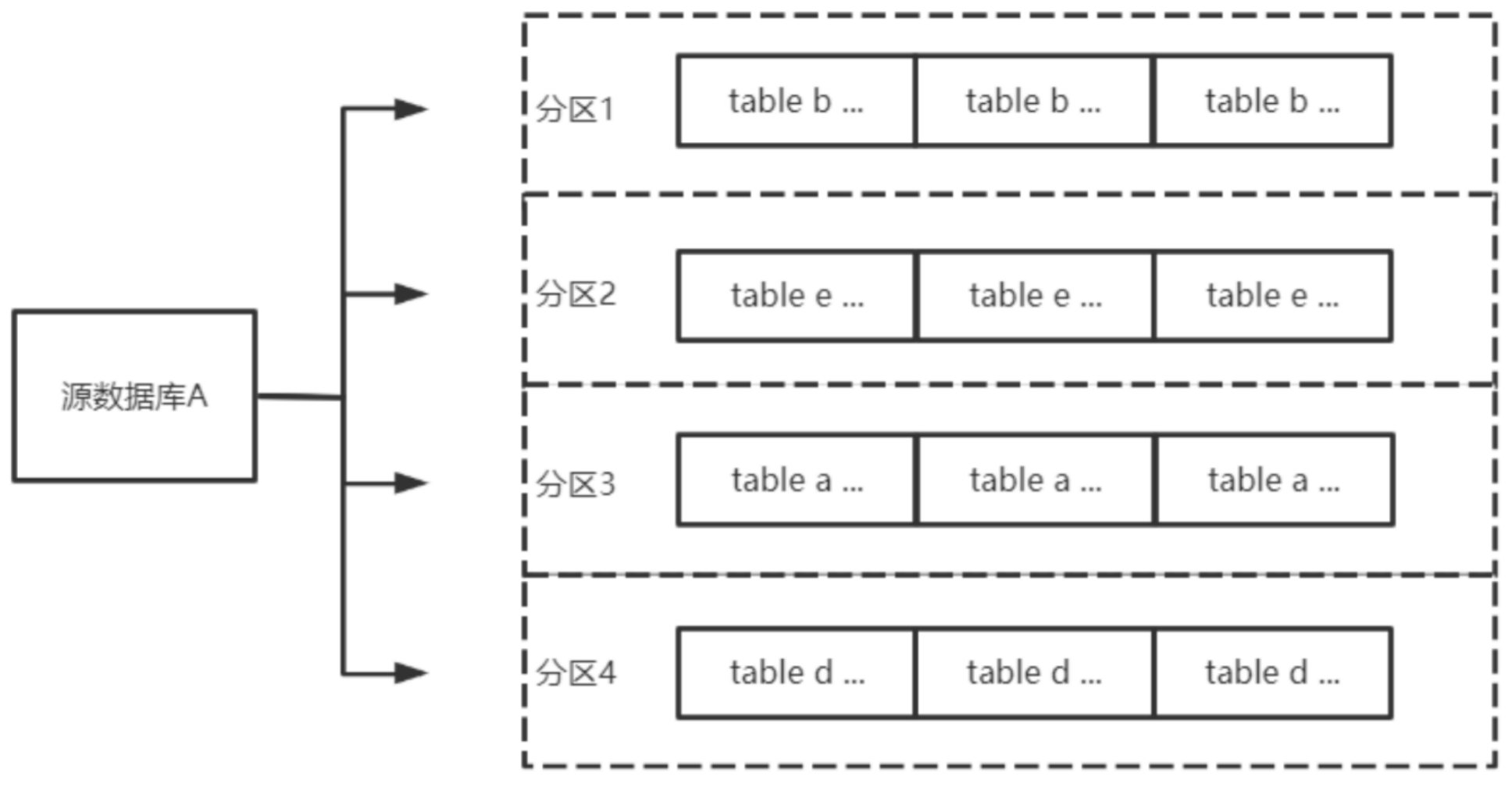
按表名分区
将源库的同步数据按照表名进行分区,设置后相同表名的数据会投递同一个分区中。
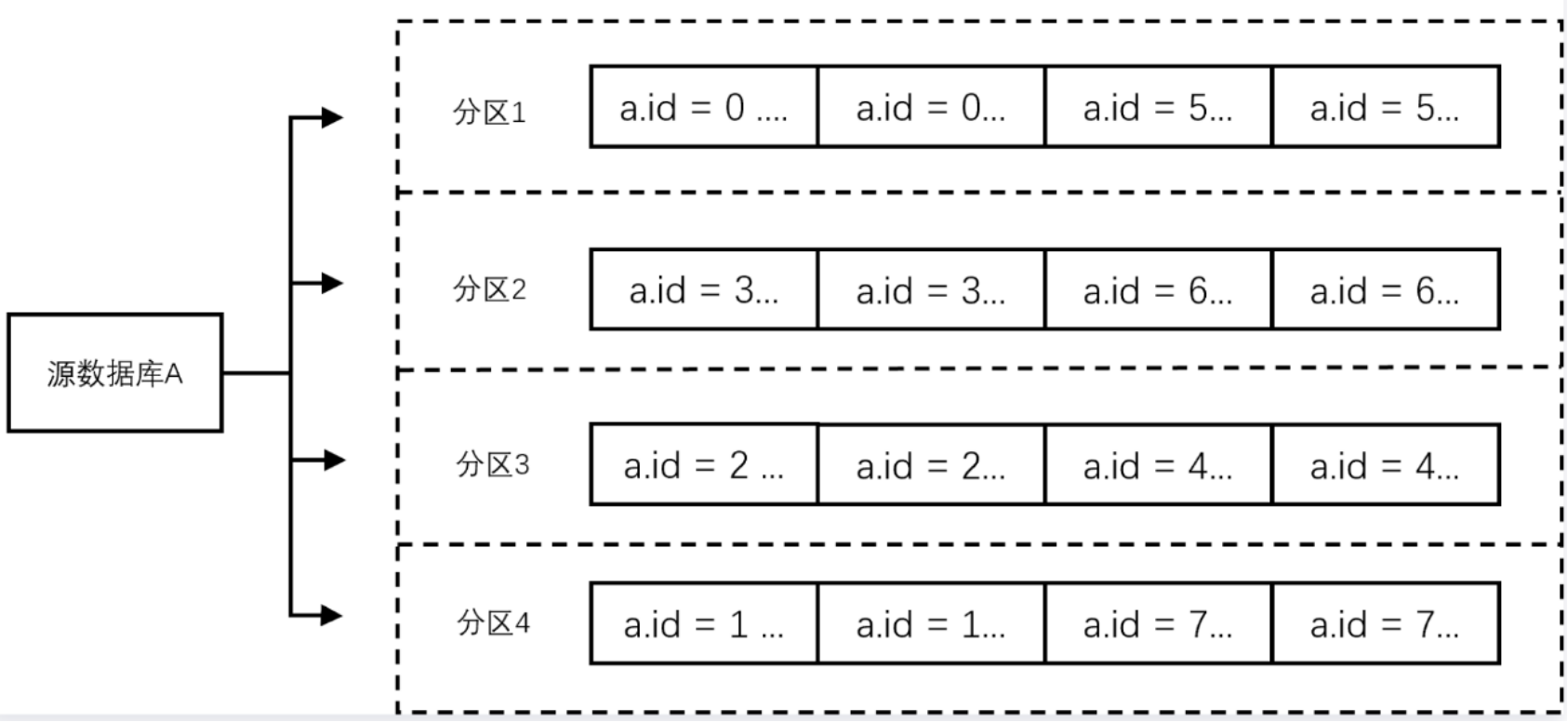
按表名 + 主键分区
将源库的同步数据按照表名 + 主键分区,设置后同一个表中主键值相同的数据会投递同一个分区中。该策略适用于热点数据,设置后热点数据的表,将分散到不同分区中,提升并发消费效率。
自定义分区策略
当 Topic 分区策略(默认分区策略)选择按“表名分区”、“按表名 + 主键分区”时,支持勾选自定义分区策略。
自定义分区策略是通过正则表达式对库名和表名进行匹配,将匹配到的数据按照表名、表名 + 主键、列进行分区,剩余未匹配到的数据再按照 Topic 分区策略(默认分区策略)的设置进行分区。
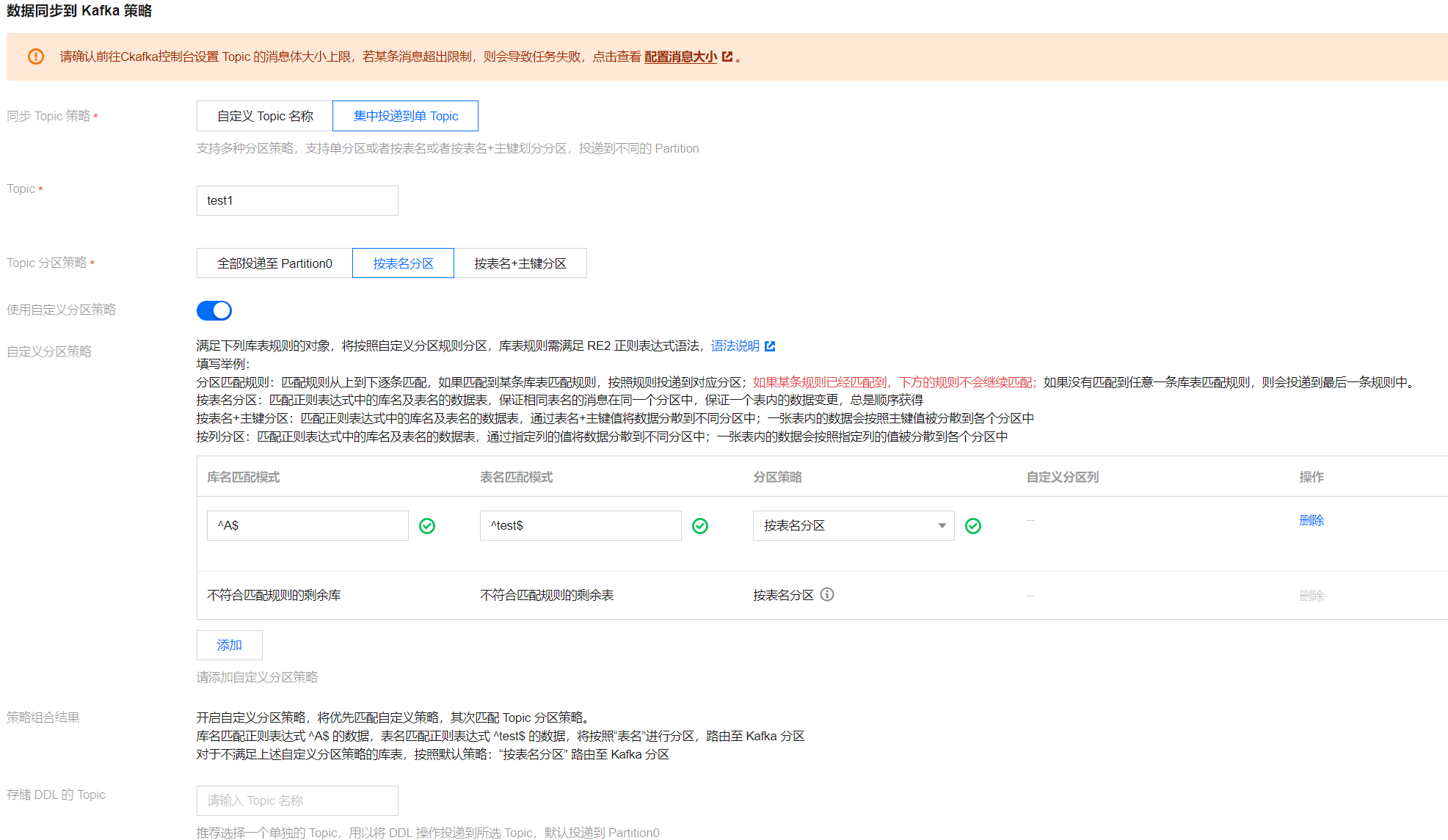
匹配规则
库表、表名的匹配规则支持 RE2 正则表达式,具体语法请参考 语法说明。
库名的匹配规则,按照正则表达式来匹配库名。表名的匹配规则,按照正则表达式来匹配表名的数据。如果库名和表名需要精确匹配,需要加开始和结束符,如
test 表应该为 ^test$。列名的匹配规则,按照等值
== 来匹配,大小写不敏感。优先匹配自定义分区策略,当自定义分区策略有多条时,自上向下逐条匹配。自定义分区策略未匹配到的剩余数据,再按照 Topic 分区策略进行投递。
按表名分区
库名匹配模式填入
^A$,表名匹配模式填入 ^test$,选择按表名分区后,A 库中 test 的数据会投递到同一个分区中,test 除外其他未匹配到的库表数据会根据 Topic 分区策略(默认分区策略)中设置的策略进行投递。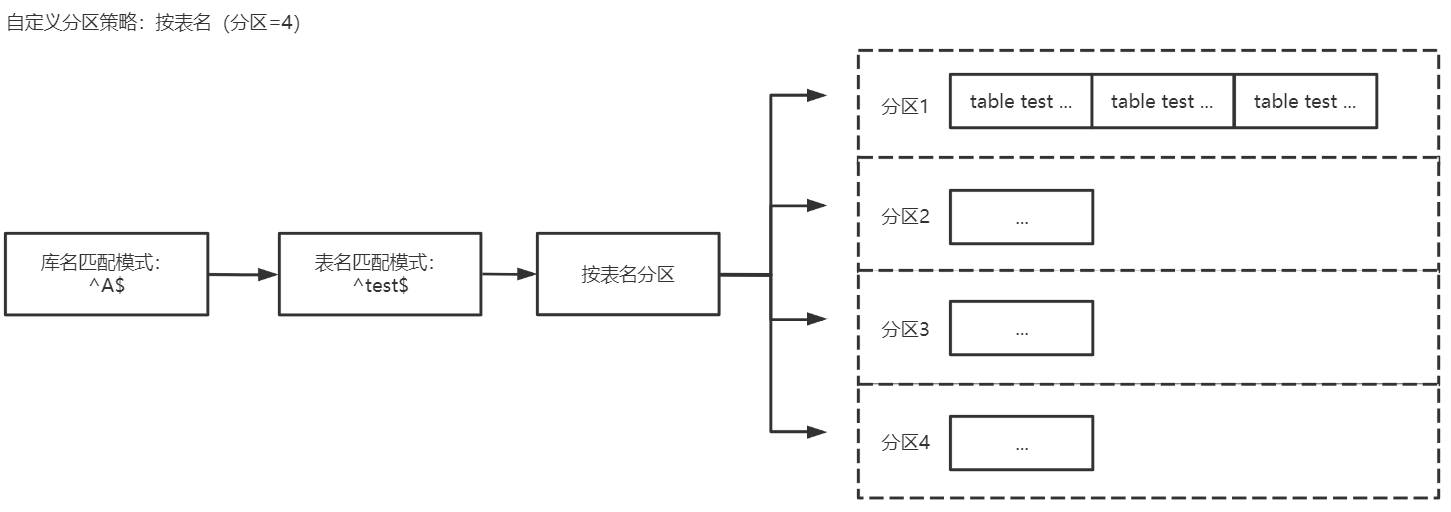
按表名 + 主键分区
库名匹配模式填入
^A$,表名匹配模式填入 ^test$,选择按表名+主键分区后,A 库中 test 的数据会根据主键数据的不同,散列投递到不同的分区中,最终主键数据相同的数据都投递到了同一个分区。test 除外其他未匹配到的库表数据会根据 Topic 分区策略(默认分区策略)中设置的进行投递。
按列分区
库名匹配模式填入
^A$,表名匹配模式填入 ^test$,自定义分区列填入class,选择按列名分区后,A 库中表 test 列名为 class 的数据将被散列到不同分区中,最终同一列的数据更新都投递到了一个分区中。test 除外其他未匹配到的库表数据会根据 Topic 分区策略(默认分区策略)中设置进行投递。
文档反馈