使用单行-完全正则提取模式采集日志
Download
聚焦模式
字号
操作场景
单行-完全正则模式适用于日志文本中每行内容为一条原始日志,且每条日志可按正则表达式提取为多个 key-value 键值的日志解析模式。若不需要提取 key-value,请参见 单行全文格式 进行配置。
配置单行-完全正则模式时,您需要先输入日志样例,再自定义正则表达式。配置完成后,系统将根据正则表达式中的捕获组提取对应的 key-value。
本文将为您详细介绍如何采集单行-完全正则模式日志。
前提条件
目标文件所在服务器已安装 LogListener。详情请参见:
LogListener Linux 版本为2.2.2及以上或 LogListener Windows 版本为2.9.7及以上。
效果预览
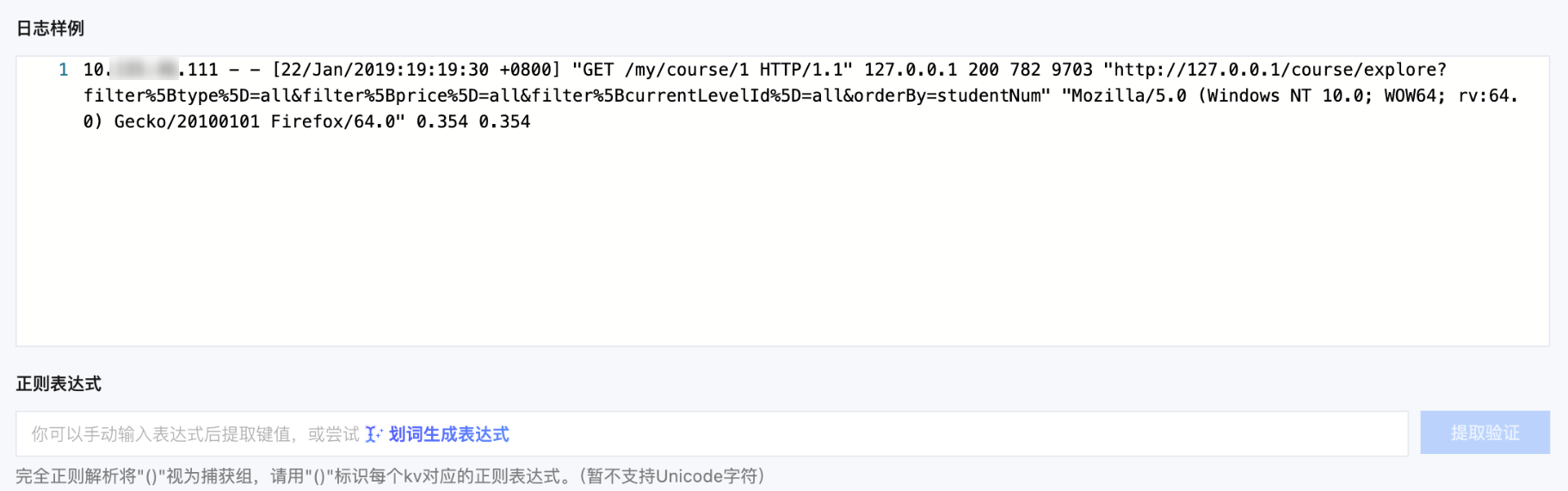
假设您的一条日志原始数据为:
10.135.46.111 - - [22/Jan/2019:19:19:30 +0800] "GET /my/course/1 HTTP/1.1" 127.0.0.1 200 782 9703 "http://127.0.0.1/course/explore?filter%5Btype%5D=all&filter%5Bprice%5D=all&filter%5BcurrentLevelId%5D=all&orderBy=studentNum" "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:64.0) Gecko/20100101 Firefox/64.0" 0.354 0.354
配置的自定义正则表达式为:
(\\S+)[^\\[]+(\\[[^:]+:\\d+:\\d+:\\d+\\s\\S+)\\s"(\\w+)\\s(\\S+)\\s([^"]+)"\\s(\\S+)\\s(\\d+)\\s(\\d+)\\s(\\d+)\\s"([^"]+)"\\s"([^"]+)"\\s+(\\S+)\\s(\\S+).*
系统根据
()捕获组提取对应的 key-value 后,您可以自定义每组的 key 名称如下所示:body_bytes_sent: 9703http_host: 127.0.0.1http_protocol: HTTP/1.1http_referer: http://127.0.0.1/course/explore?filter%5Btype%5D=all&filter%5Bprice%5D=all&filter%5BcurrentLevelId%5D=all&orderBy=studentNumhttp_user_agent: Mozilla/5.0 (Windows NT 10.0; WOW64; rv:64.0) Gecko/20100101 Firefox/64.0remote_addr: 10.135.46.111request_length: 782request_method: GETrequest_time: 0.354request_url: /my/course/1status: 200time_local: [22/Jan/2019:19:19:30 +0800]upstream_response_time: 0.354
操作步骤
步骤1:创建/选择日志主题
如果您想创建新的日志主题,可执行如下操作:
1. 登录 日志服务控制台。
2. 在左侧导航栏中,选择概览,进入概览页面。
3. 在快速接入中,选择服务器及应用,找到并单击单行完全正则-文件日志,进入采集配置流程。
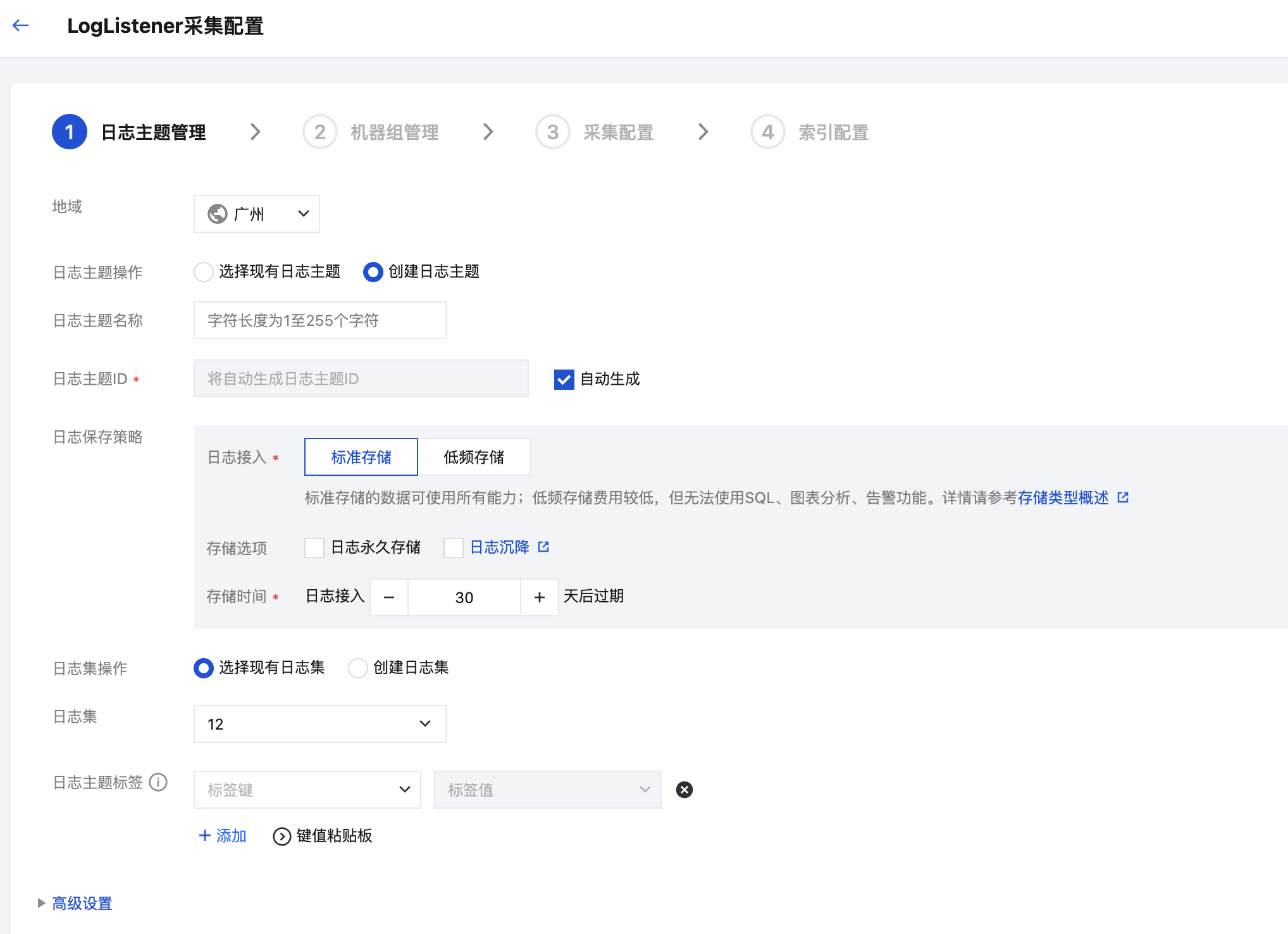
4. 在采集配置流程的创建日志主题页面,根据实际需求,输入日志主题名称,配置日志保存时间等信息,单击下一步。
如果您想选择现有的日志主题,可执行如下操作:
1. 登录 日志服务控制台。
2. 在左侧导航栏中,选择日志主题,然后选择需要投递的日志主题,单击日志主题名称,进入日志主题管理页面。
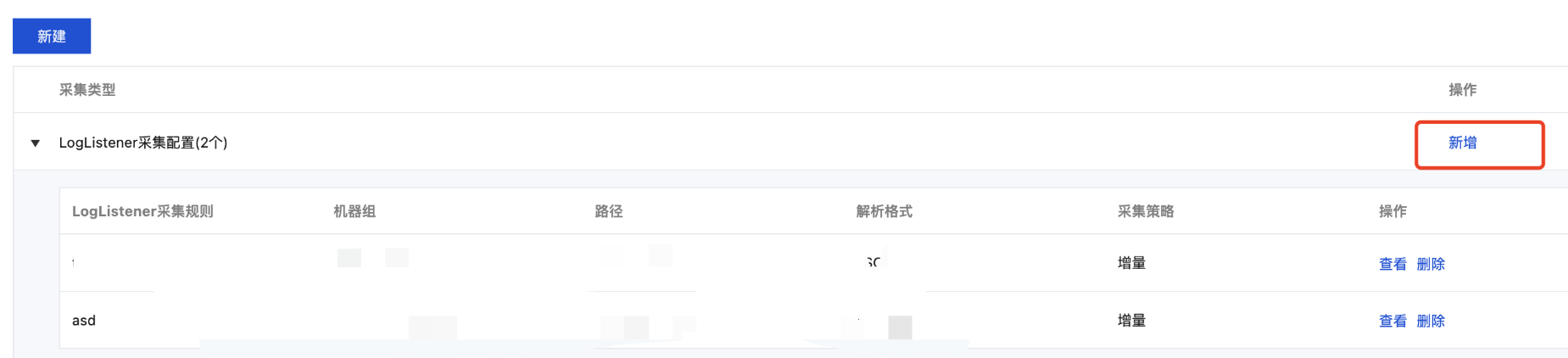
3. 选择采集配置页签,在 LogListener 采集配置栏下单击新增,进入日志数据源选择。
4. 在日志数据源选择页面中,选择服务器及应用,找到并单击单行完全正则-文件日志,进入采集配置流程。
步骤2:机器组管理
若您需要采集的目标服务器未安装 LogListener, 可参见:
如果您想创建新的机器组,可执行如下操作:
1. 单击新建机器组。
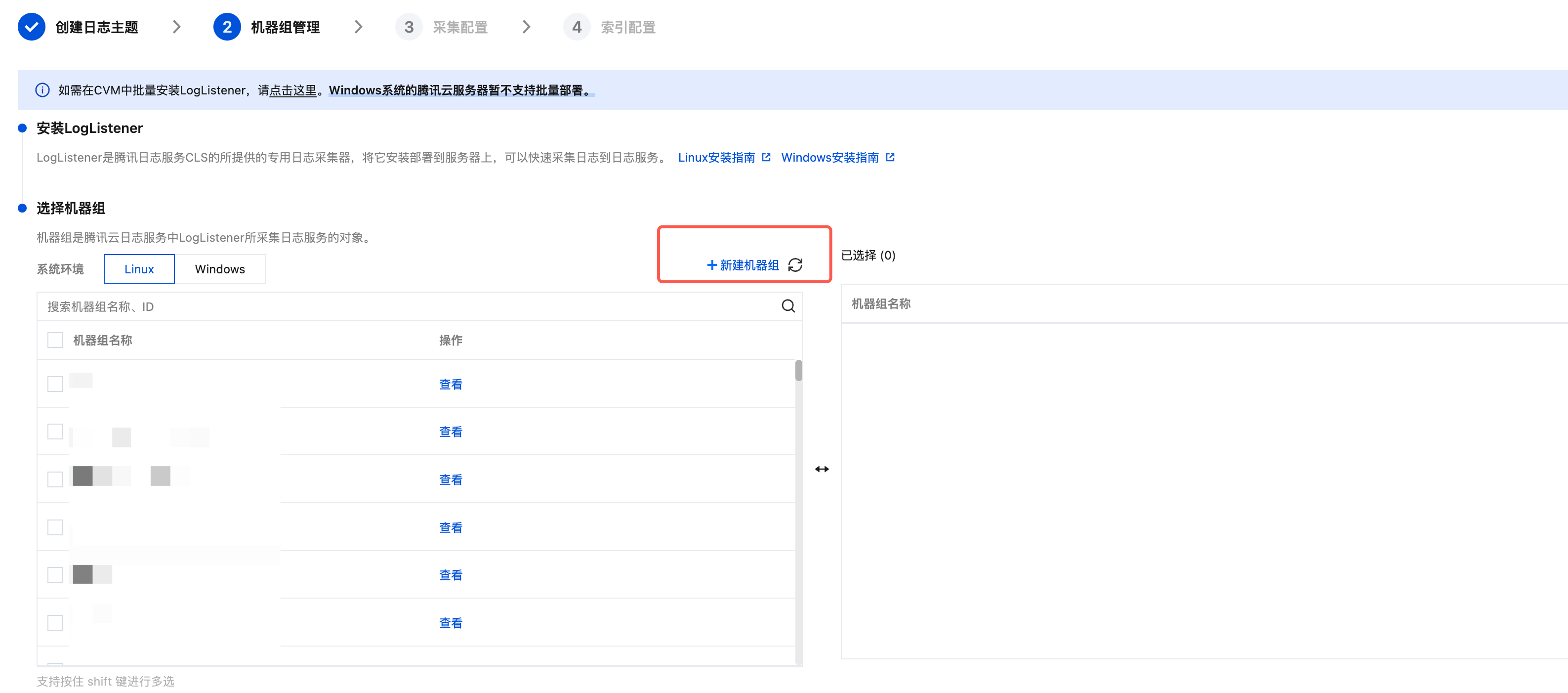
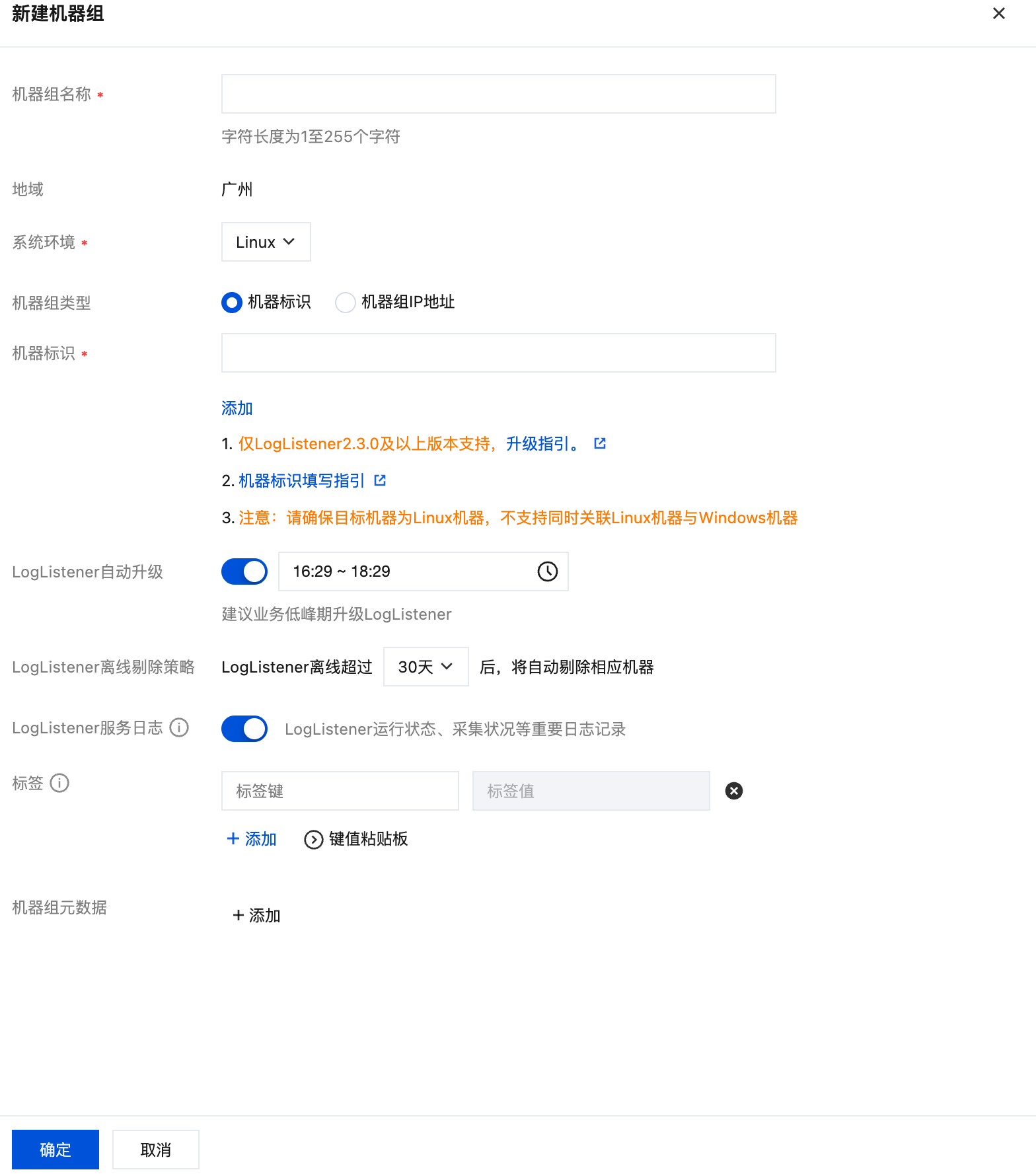
2. 填写机器组名称,通过机器标识的方式关联已安装 LogListener 的目标服务器。详情请参见 机器组,然后单击确定。
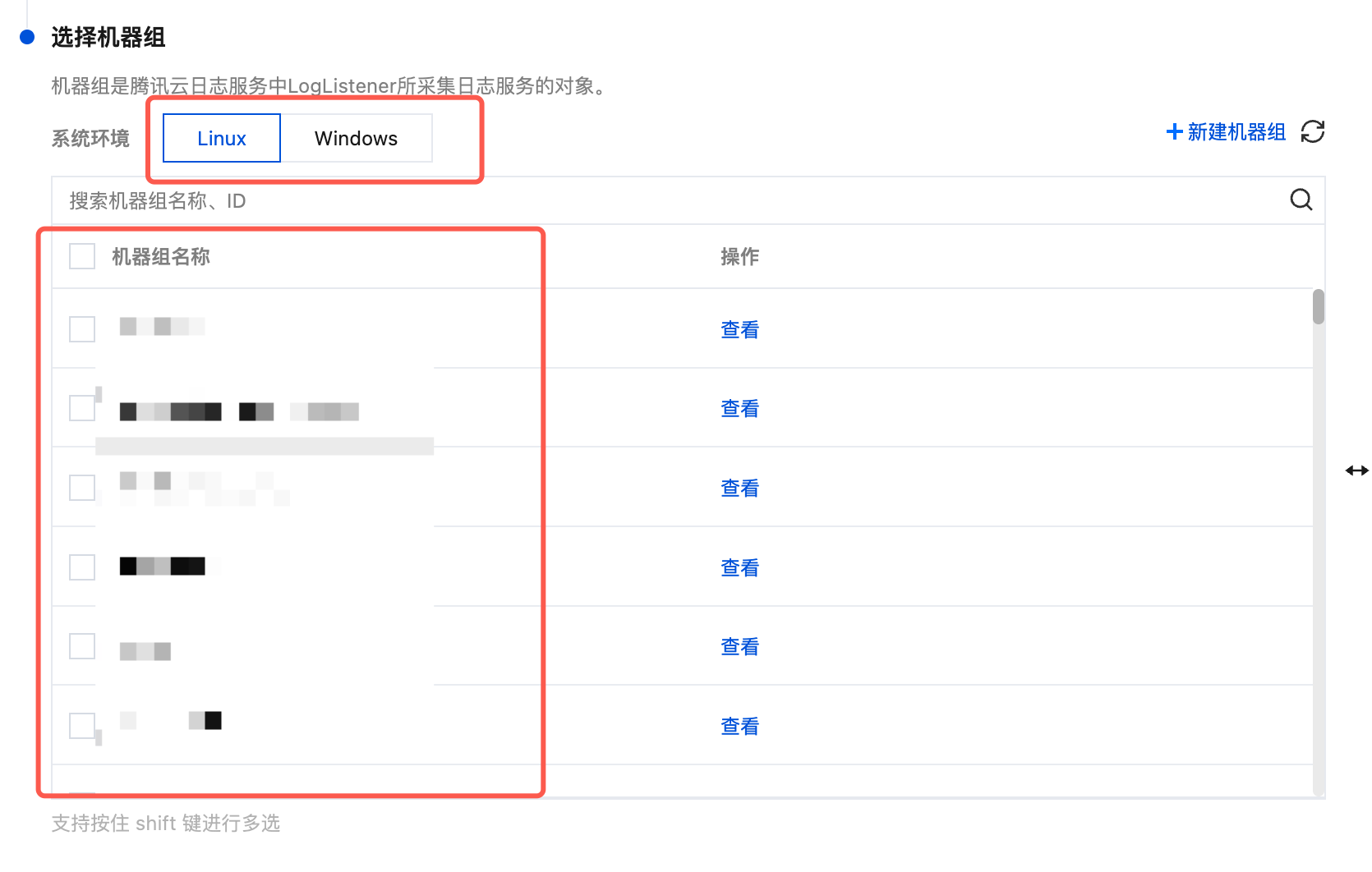
3. 完成创建后,在 Tab 选项中选择您创建的机器组的系统环境,在列表中勾选您的目标机器组,并单击下一步。
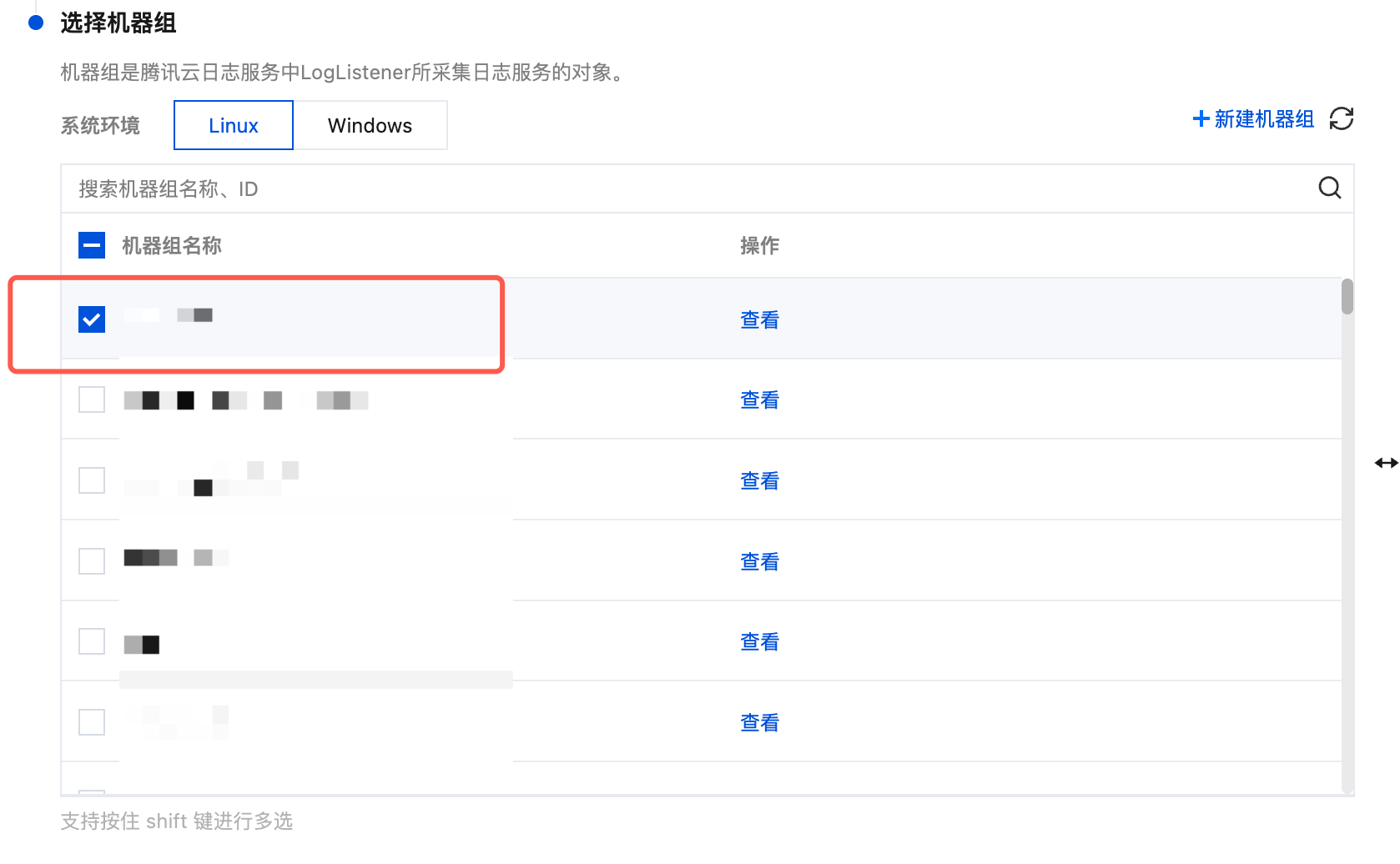
如果您想选择已有的机器组,可在 Tab 选项中选择您创建的机器组的系统环境,在列表中勾选您的目标机器组,并单击下一步。
步骤3:采集配置
配置日志文件采集路径
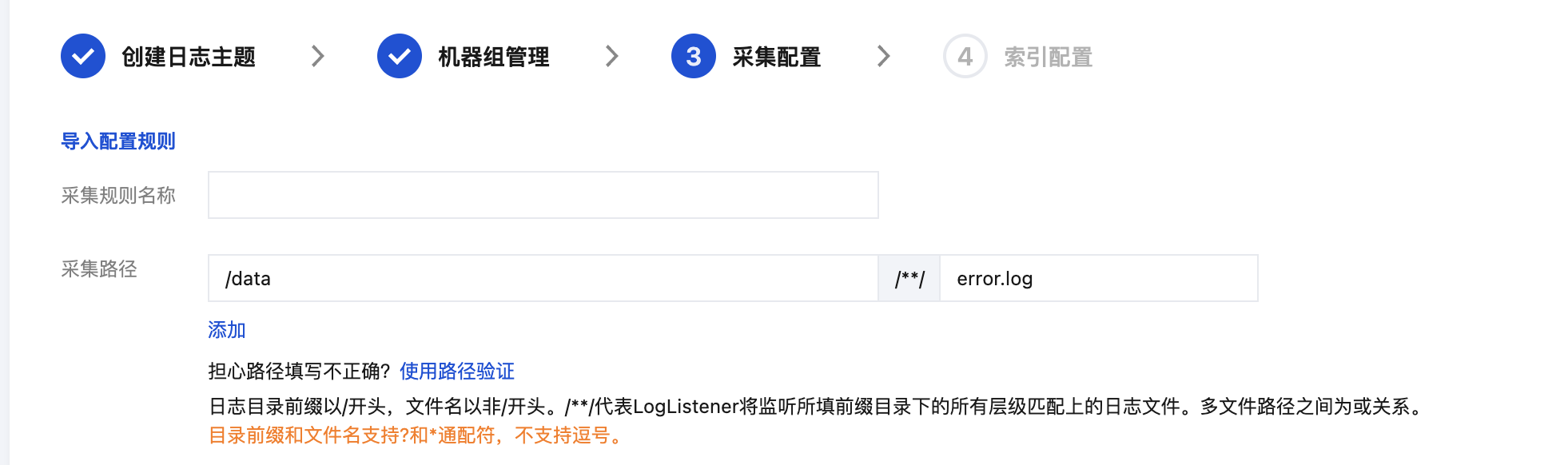
在采集配置页面,填写采集规则名称,并根据日志采集路径格式填写采集路径。日志采集路径格式参考如下:
注意:
Linux 日志路径必须以
/开头。Windows文件路径必须以盘符开头,如C:\\。Linux 系统中的日志路径:
/[目录前缀表达式]/**/[文件名表达式],例如:/data/log/**/*.log。Windows 系统中的日志路径
:[盘符]:\\[目录前缀表达式]\\**\\[文件名表达式],例如:C:\\Program Files\\Tencent\\...\\*.log。填写日志采集路径后,LogListener 会按照[目录前缀表达式]匹配所有符合规则的公共前缀路径,并监听这些目录(包含子层目录)下所有符合[文件名表达式]规则的日志文件。其参数详细说明如下:
序号 | 目录前缀表达式 | 文件名表达式 | 说明 |
1 | /var/log/nginx | access.log | 此例中,日志路径配置为 /var/log/nginx/**/access.log,LogListener 将会监听/var/log/nginx前缀路径下所有子目录中以access.log命名的日志文件 |
2 | /var/log/nginx | *.log | 此例中,日志路径配置为 /var/log/nginx/**/*.log,LogListener 将会监听/var/log/nginx前缀路径下所有子目录中以 .log 结尾的日志文件 |
3 | /var/log/nginx | error* | 此例中,日志路径配置为 /var/log/nginx/**/error*,LogListener 将会监听/var/log/nginx前缀路径下所有子目录中以error开头命名的日志文件 |
注意:
Windows 系统环境暂不支持软链采集。
LogListener 2.3.9及以上版本才可以添加多个采集路径。
建议配置采集路径为
log/*.log,rename 日志轮转后的老文件命名为 log/*.log.xxxx。默认情况下,一个日志文件只能被一个日志主题采集。如果一个文件需要对应多个采集配置,且文件所在系统环境为 Linux,请给源文件添加一个软链接,并将其加到另一组采集配置中。
配置采集路径黑名单
开启采集路径黑名单,可在采集时忽略指定的目录前缀或完整的文件路径。目录路径和文件路径可以是完全匹配,也支持通配符模式匹配。
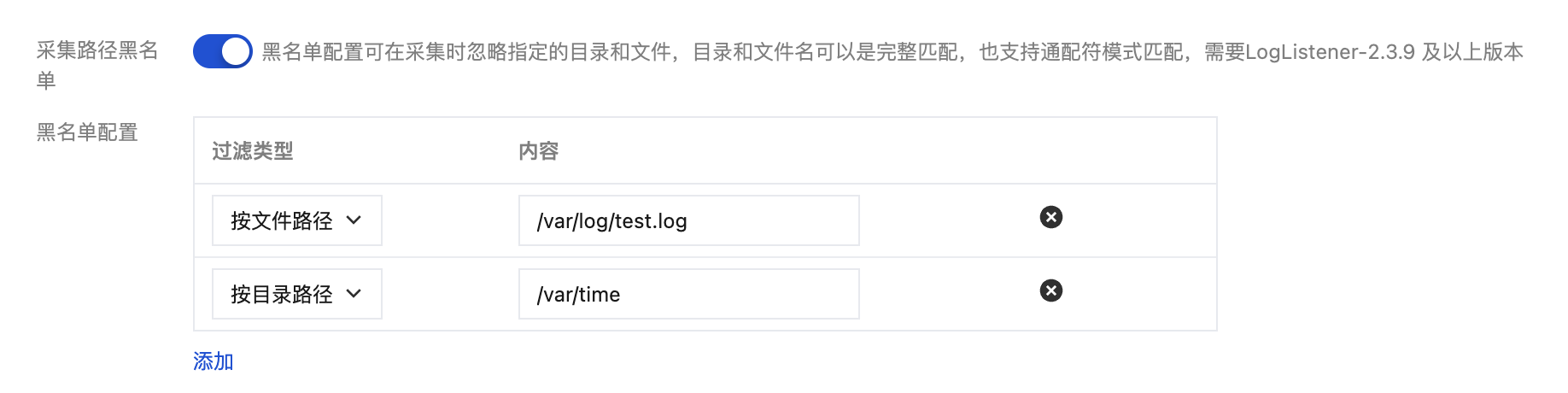
采集黑名单分为两类过滤类型,且可以同时使用:
文件路径:采集路径下,需要忽略采集的完整文件路径,支持通配符*或?,支持**路径模糊匹配。
目录路径:采集路径下,需要忽略采集的目录前缀,支持通配符*或?,支持**路径模糊匹配。
注意:
需要 LogListener 2.3.9及以上版本。
采集黑名单是在采集路径下进行排除,因此无论是文件路径模式,还是目录路径模式,其指定路径要求为采集路径的子集。
配置采集策略
全量采集:LogListener 采集文件时,从文件的开头开始读。
增量采集:LogListener 采集文件时,只采集文件内新增的内容。
配置回溯采集

当采集策略选择为增量采集时,您可以进一步在此设置回溯采集的起始点,指定 LogListener 启动时是否从最新位置往前偏移您指定字节数开始采集。
注意:
Windows 系统环境暂不支持。
编码模式
UTF-8:若您的日志文件编码模式为 UTF-8,请选择该选项。
GBK:若您的日志文件编码模式为 GBK,请选择该选项。
配置单行-完全正则模式
1. 在采集配置页面,将“提取模式”设置为单行-完全正则,并在“日志样例”文本框中,输入日志样例。如下图所示:
2.
根据如下规则,定义正则表达式:
系统提供三种定义正则表达式的方式:AI 划词模式、自动模式和手动模式。
AI 划词模式:单击正则表达式中的划词生成表达式,然后再单击 AI 一键划词即可进入 AI 划词模式。
自动模式:单击划词生成表达式即可切换为自动模式。
手动模式:直接手动输入表达式,提取并验证 key-value。
系统会根据您选择的模式和定义好的正则表达式,自动提取并验证对应的 key-value。
1. 单击划词生成表达式工具。

2. 在弹出的“
正则表达式自动生成
”模态视图中,单击 AI 一键划词工具。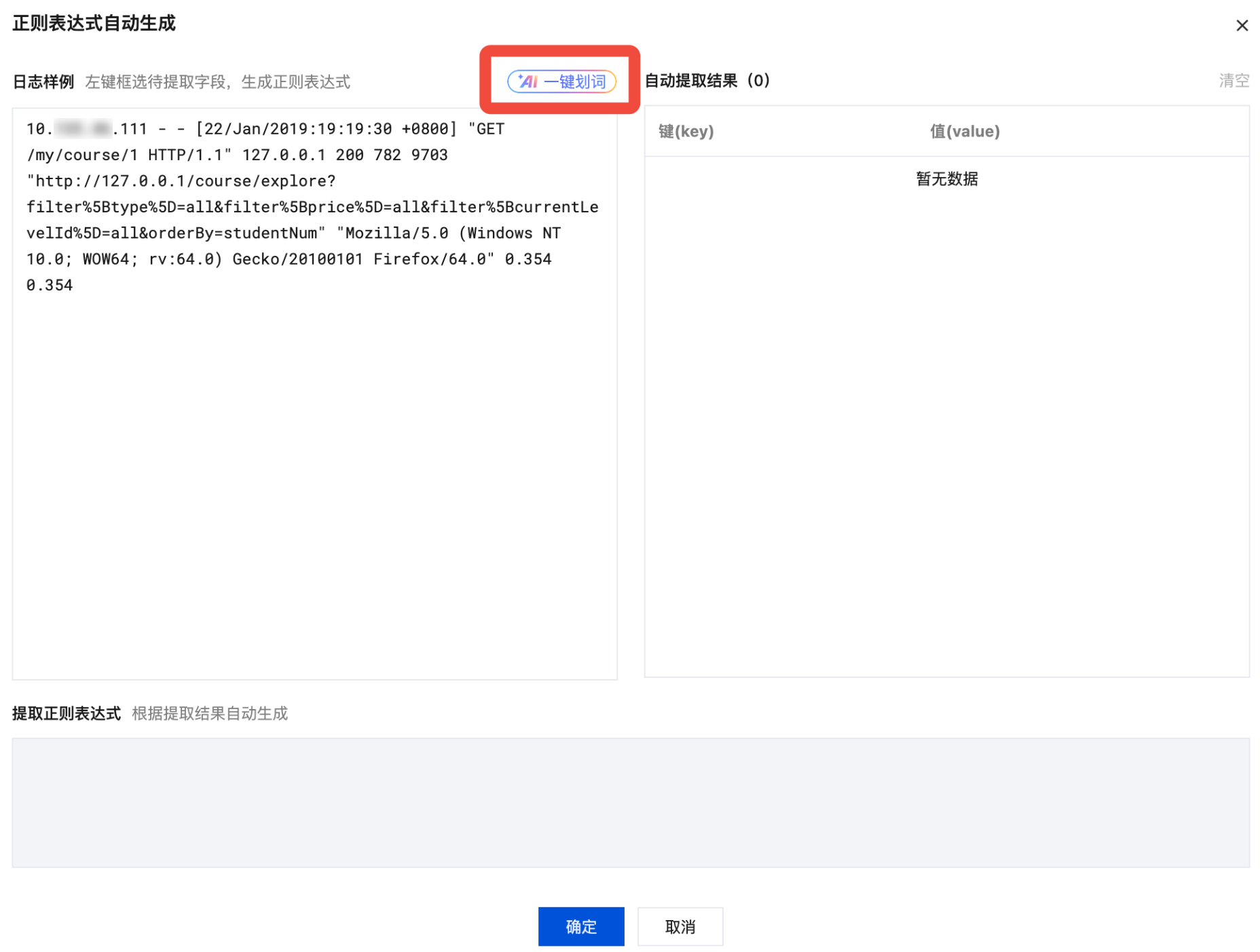
3. AI 将对您的日志进行智能划词,识别出对应的 key-value 结构,并根据值(value),自动生成键( key)。划词结果会在右侧的自动提取结果表格中展示,您可在此对键(key)进行修改。同时系统会根据划词结果自动生成提取正则表达式并显示在下侧表格中。如下图所示:
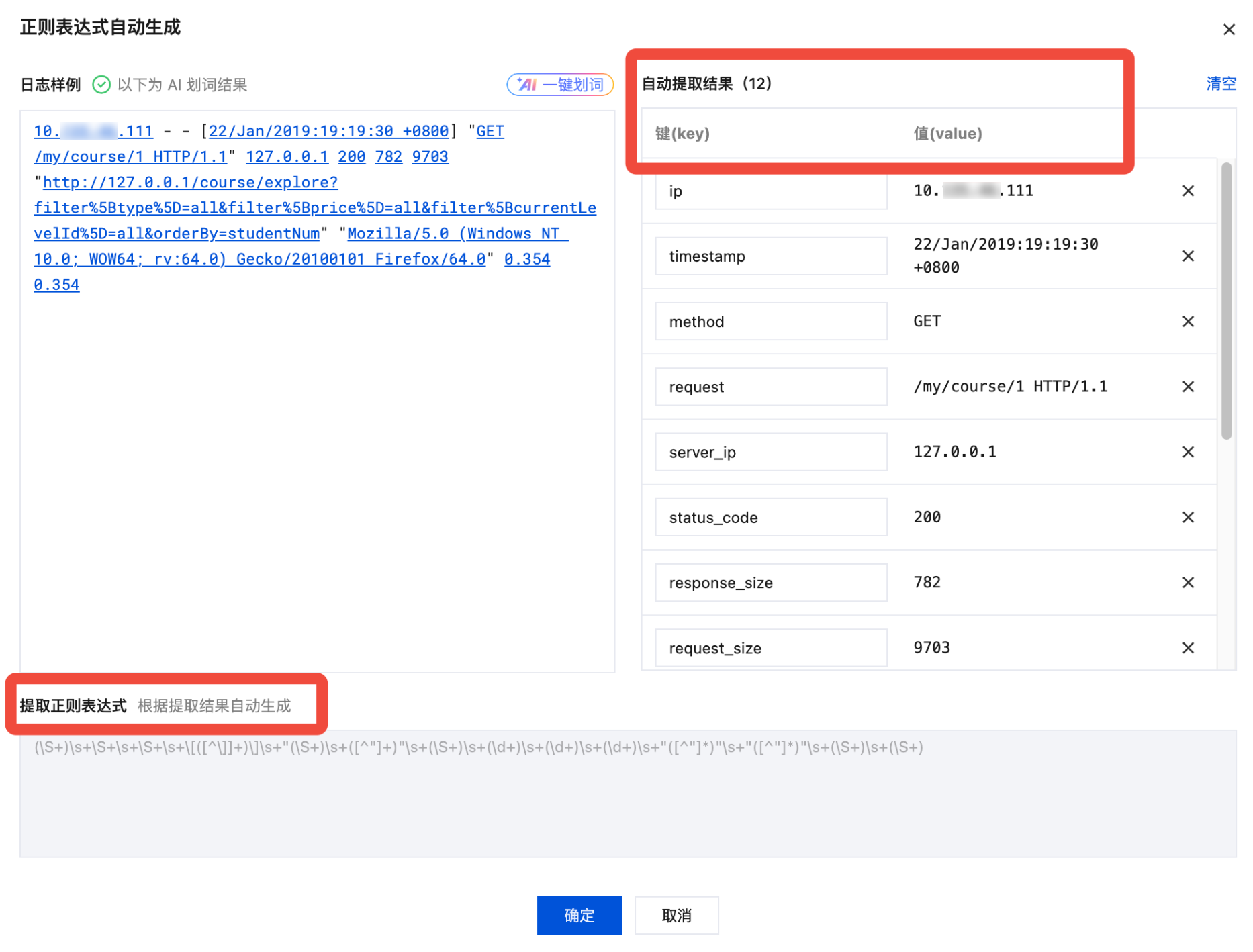
4. 单击确定。
1. 单击划词生成表达式工具。

2. 在弹出的“
正则表达式自动生成
”模态视图中,根据实际的检索分析需求,鼠标左键选中需要提取 key-value 的日志内容,并在弹出的文本框中,输入键(key)名,单击确认提取。如下图所示: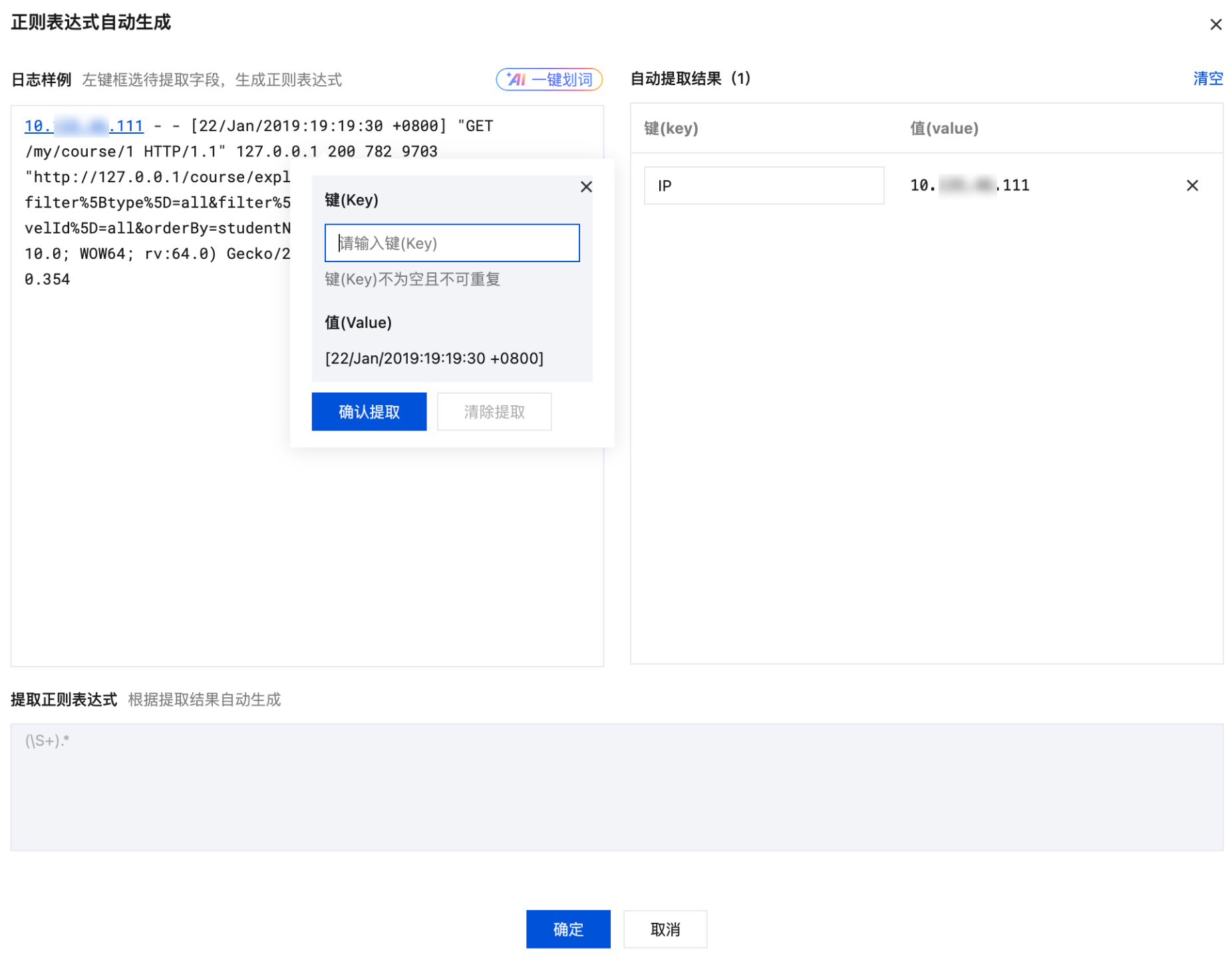
系统将自动对该部分内容提取一个正则表达式,自动提取结果会出现在右侧 key-value 表格中,根据自动提取结果自动生成的提取正则表达式会出现在下侧表格中。如下图所示:
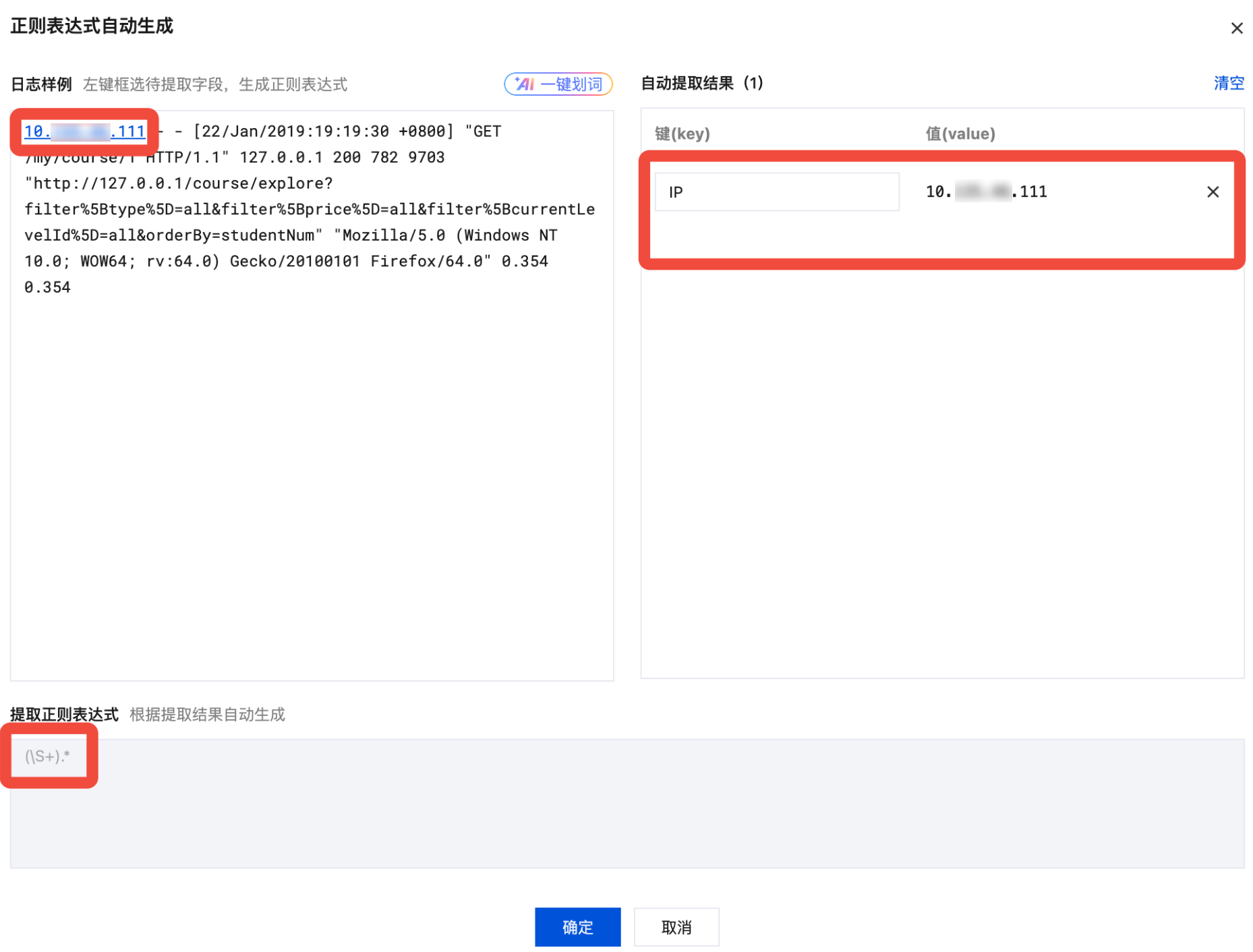
3. 重复 自动模式的步骤2,直到提取完所有的 key-value 对。
4. 单击确定,系统将根据提取好的 key-value 对自动生成完整的正则表达式。
1. 在正则表达式的文本框中,输入正则表达式。
2. 单击提取验证,系统将判断日志样例与正则表达式是否匹配。

说明:
无论您使用 AI 划词模式、自动模式还是手动模式,在完成定义并验证通过后,提取结果都将展示在“提取结果”中。若结果不符合预期,可返回 定义正则表达式 重新编辑,并再次验证。
您只需定义每一组 key-value 对的键(key)名称,即可将该名称用于日志检索分析。
更多日志验证
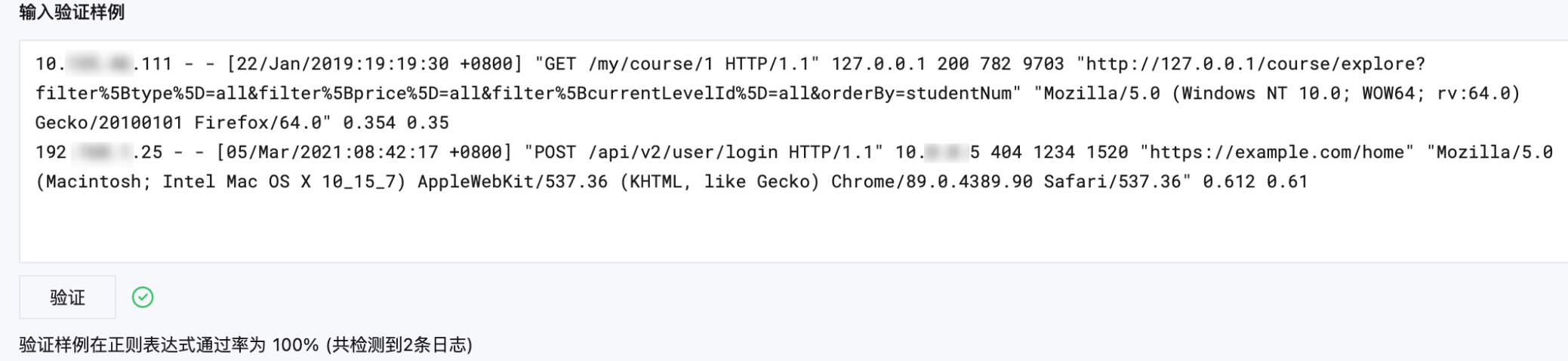
1. 当您有多条复杂日志样例数据时,可以将匹配更多日志设置为开启
2. 输入待验证日志样例,以换行符分开多条数据,单击验证,系统将验证样例通过率。出现
配置自定义元数据
机器组元数据:使用机器组元数据
采集路径:通过正则提取采集路径中的值作为元数据
自定义:自定义键值作为元数据
注意:
仅 LogListener 2.8.7及以上版本支持配置自定义元数据。
配置日志时间戳来源
您可选择以日志采集时间或者指定日志字段两种时间作为日志的时间戳:
使用日志采集的时间作为日志时间。

使用日志中指定字段的值作为日志的时间。
1. 在日志时间字段中选择已经提取的 Value 值作为日志时间。

2. 在时间格式解析中手动输入或选择该值对应的解析表达式。例如:日志中代表时间的值为 07/Jul/2025:19:19:30 +0800,解析格式为:%d/%b/%Y :%H:%M:%S %z。更多请参见 配置时间格式。
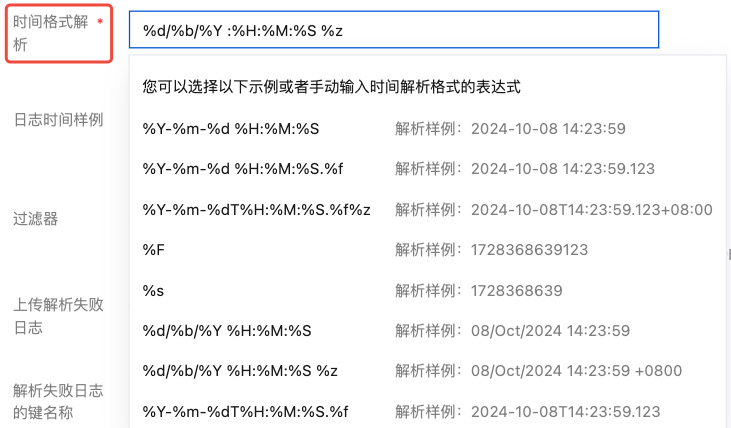
3. 单击验证。
注意:
若时间格式填写错误,日志时间将以采集时间为准。
配置过滤器条件
过滤器的目的是根据业务需要添加日志采集过滤规则,以帮助您筛选出有价值的日志数据。
完全正则采集时,需要根据所自定义的键值对来配置过滤条件。支持以下过滤规则:
等于:仅采集指定字段值匹配指定字符的日志。支持完全匹配,或正则匹配。
不等于:仅采集指定字段值不匹配指定字符的日志。支持完全匹配,或正则匹配。
字段存在:仅采集指定字段存在的日志。
字段不存在:仅采集指定字段不存在的日志。
例如,样例日志使用完全正则模式解析后,您希望 status 字段为400或500的所有日志数据被采集,那么 key 处配置 status,过滤规则选择等于,value 处配置400|500。
注意:
Windows 系统环境暂不支持。
过滤规则 “不等于”、“字段存在”以及“字段不存在” 仅在 LogListener 2.9.3及以上版本支持。
多条过滤条件之间关系是"与"逻辑,若同一 key 名配置多条过滤条件,规则会被覆盖。
配置上传解析失败日志
建议开启上传解析失败日志。开启后,LogListener 会上传各式解析失败的日志。若关闭上传解析失败日志,则会丢弃失败的日志。

开启后需要配置解析失败的 Key 值(默认为 LogParseFailure),所有解析失败的日志,均以输入内容作为键名称(Key),原始日志内容作为值(Value)进行上传。
上传原始日志
开启后 LogListener 会将原始日志与解析后的日志一起上传。所有原始日志,均以您指定的键名称,原始日志内容将作为值(Value)进行上传。
高级配置
注意:
Windows 系统环境暂不支持。
通过勾选,选择您需要定义的高级配置。

单行-完全正则提取模式下,支持配置以下高级配置。
名称 | 描述 | 配置项 |
超时属性 | 该配置控制日志文件的超时时间。如果一个日志文件在指定时间内没有任何更新,则为超时。超时的日志文件 LogListener 将不再采集。当您的日志文件数量较大时,建议降低超时时间,避免 LogListener 性能浪费。 | 不超时:日志文件永不超时 自定义:自定义日志文件的超时时间 |
最大目录深度 | 该配置控制日志采集的最大目录深度。LogListener 不会采集所在目录层级超过指定最大目录深度的日志文件。当您目标采集路径包含模糊匹配时,建议配置合适的最大目录深度,避免 LogListener 性能浪费。 | 大于0的整数。0代表不进行子目录的下钻 |
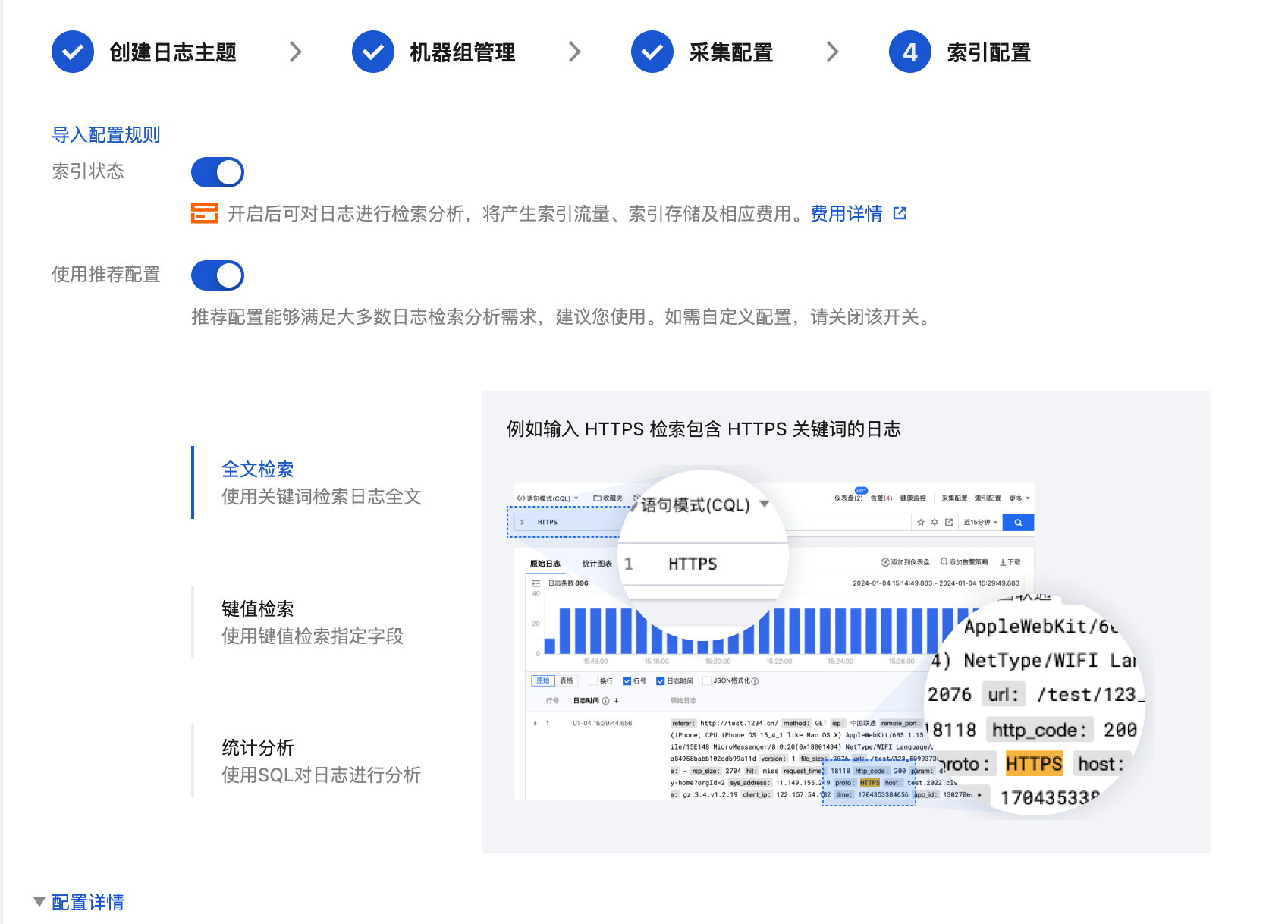
步骤4:索引配置
1. 单击下一步,进入“索引配置”页面。
2. 在“索引配置”页面,设置如下信息。配置详情请参见 索引配置。
注意:
检索必须开启索引配置,否则无法检索。
3. 单击提交,进入编辑索引配置确认页面。
4. 操作成功,完成采集配置。
相关操作
文档反馈