采样分析
Download
聚焦模式
字号
操作场景
日志服务通过随机采样的方式对原始日志进行采样,根据统计学相关原理,在合理的采样率及较大的样本数下,采样后的统计结果相比全量精确统计误差较低,能够满足大多数海量数据的统计分析需求。
采样方式
统计分析默认为“精确分析”,即不采样。需要采样时,可选择如下两类采样方式:
自动采样:根据原始日志条数多少自动决定采样率,使得样本数约为100万,以该样本进行统计分析。例如原始日志为100亿条时,使用自动采样获取100万样本,对应的采样率为1:10,000。
固定采样率采样:人工设定采样率,根据该采样率从原始日志中获取样本。例如原始日志为100亿条时,按照1:100,000采样,样本数为10万。采样率最大为1(即不采样),最小为1:1000,000。
无论采用哪种采样方式,在统计分析结果中均可查看最终实际的采样率。
估算真实值
采样分析结果能够很大程度上反应真实值,根据值的计算方式,可参见如下方法估算实际值:
平均值相关的计算方式:例如
avg、geometric_mean等,直接以样本统计结果代表真实值。和值相关的计算方式:例如
count(*)、sum、count_if等,以样本统计结果除以采样率代表真实值。例如,按照1:10,000的采样率统计接口 pv(count(*)),样本统计结果为232,则真实值约为232 / (1:10000) = 2320000。例如按照1:10,000采样时,检索分析语句为:
* | select count(*)/(1.0/10000) as pv,avg(response_time) as response_time_avg
pv 计算:
count(*)为统计日志条数,属于和值计算,需以样本统计结果除以采样率代表真实值。其中,(1.0/10000)即为采样率,计算获得的 pv 为真实 pv 的估算值。response_time_avg 计算:
avg(response_time)为计算响应时间response_time的平均值,属于平均值计算,可直接作为真实 response_time_avg 的估算值。采样分析准确度
统计学上使用置信水平和置信区间衡量采样结果的准确度,置信水平代表采样结果的可信度,置信区间代表指定置信水平下真实值所在的区间。例如某一样本统计结果置信水平为95%,置信区间为[212,478],则真实值有95%的概率位于212 - 478之间。
置信水平越高,置信区间越大。常用置信水平为95%(统计学中一般认为概率低于5%为小概率事件),对应的置信区间计算方式为:
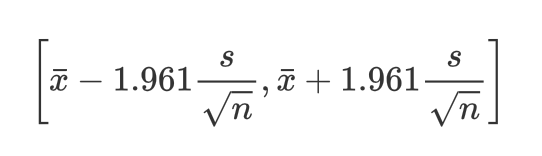
其中,x̅ 为样本平均值,s 为样本标准差,n 为样本数。
例如使用自动采样进行统计分析:
* | select avg(response_time) as x,count(response_time) as n,stddev_samp(response_time) as s
样本统计分析结果为:
x:即样本平均值,544.4656932942215;
n:即样本数,995097;
s:即样本标准差,1382.618439585749。
则置信水平为95%时,
avg(response_time)的真实值位于[541.75,547.18]内,而实际上该案例通过精确统计得到的avg(response_time)为545.16,估算值非常接近真实值。说明:
以上为严格的采样准确度衡量方式,实际使用过程中,样本数大于1000时,采样获得的结果一般具备较高的准确度。
按维度统计分析时(即group by),由于样本会按指定维度拆分为多个组,并在每个组内分别计算统计值,此时单个组内的样本数将低于总样本数,会导致样本数较少的组的统计值准确度较低。
例如使用采样进行统计分析:
* | select avg(response_time) as response_time,count(*) as sampleCount,url group by url order by count(*) desc
样本统计分析结果为:
url | response_time | sampleCount |
/user | 45.23 | 7845 |
/user/list | 78.45 | 6574 |
/user/login | 45.85 | 5235 |
/user/logout | 45.48 | 1245 |
/book/new | 125.78 | 987 |
/book/list | 17.23 | 658 |
/book/col | 10.21 | 23 |
/order | 12.13 | 2 |
其中,
/book/col和/order两个 url 的样本数过低,统计结果准确度较低,不具备参考性。如需对这两个 url 获取更加准确的统计结果,可提高整体的采样率,或单独对其进行统计分析。例如:url:"/book/col" OR url:"/order" | select avg(response_time) as response_time,count(*) as sampleCount,url group by url order by count(*) desc
操作步骤
1. 登录 日志服务控制台。
2. 在左侧导航栏中,单击检索分析,进入日志主题检索分析页面。
3. 在页面顶部,选择需要检索分析的日志主题。
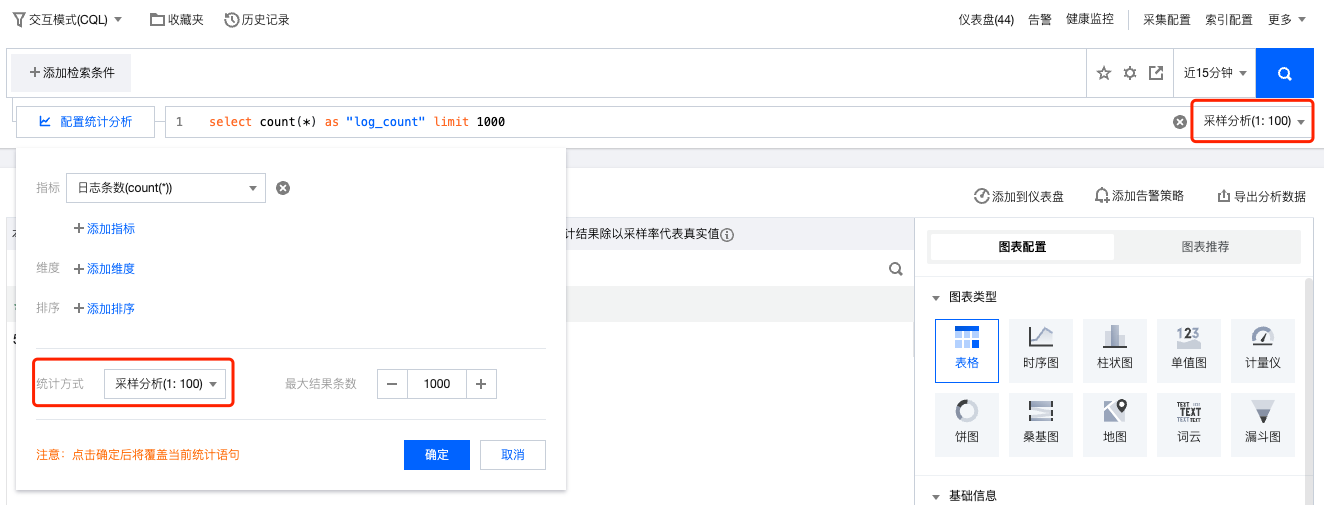
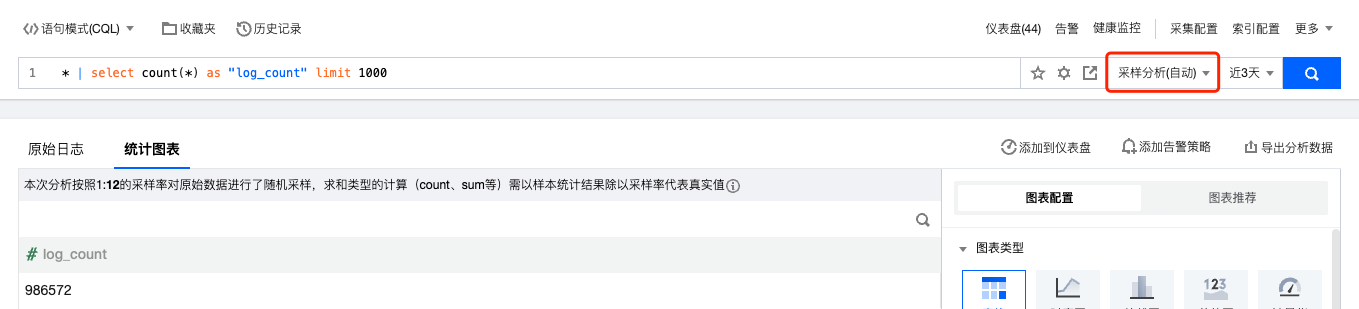
4. 输入检索分析语句(需包含 SQL)后,在右侧检索分析按钮左侧设定是否需要采样分析以及对应的采样率。
交互模式:
语句模式:
5. 单击右侧 
文档反馈