弹性 MapReduce(EMR)结合云技术和 Hadoop、Hive、Spark、Hbase、Presto、Storm 等社区开源技术,提供安全、低成本、高可靠、可弹性伸缩的云端托管 Hadoop 服务。您可以在数分钟内创建安全可靠的专属 Hadoop 集群,以分析位于集群内数据节点或对象存储 COS 上的 PB 级海量数据。

特性

开源
提供高性能、企业级且可靠的开源大数据生态系统(包括 Hive、Spark、Presto、HBase、Flink、Iceberg、Alluxio 等),并支持按需组件编排。

高效的运维
云原生统一可观测性和关键事件快照回滚功能可简化故障排除流程,并提高运维效率。

弹性资源扩展
根据预设时间表或工作负载,自动无缝扩展集群计算资源,只需几分钟即可适应动态业务场景。

费用优化
按需付费的资源分配、简化的部署/维护以及对计算存储分离的支持。
功能
快速部署
通过控制台点选的方式,只需三步即可获得独立专属的大数据集群。弹性 MapReduce 提供了多种大数据开源组件,您可以在创建时自由组合勾选,包括但不限于 Hive、Spark、Hbase、Presto、Flink、Storm 等,提供安全、低成本、高可靠、可弹性伸缩的云端托管 Hadoop 服务。您也可以通过 API 的方式,保留创建参数,即可反复的创建并销毁集群。
弹性 MapReduce 支持多种机型部署集群,您可以根据不同业务场景来配置集群的 CPU、内存、存储的类型和数量。
弹性
通过控制台页面或 API 的方式,轻松的操作集群规模,只需要数分钟,即可将新的节点添加进集群中,以适应业务的快速变化。新扩容的节点将对集群组件进行自动部署,组件的配置将自动同步。弹性 MapReduce 提供了只用于计算不存储数据的 Task 节点类型,利用该节点对集群的规模进行快速缩容,而无需担心数据丢失的风险隐患。
全新的自动扩缩容功能即将上线,可以大幅降低您的运维成本,集群将根据监控数据进行自动的扩容与缩容,时刻保证集群资源利用率最大化。
计算存储分离
结合腾讯云提供的高持久的对象存储 COS 服务,弹性 MapReduce 让您的大数据存储成本降低高达85%。开启对象存储访问后,弹性 MapReduce 将自动适配 COS 的文件系统,您可以像操作 HDFS 一样,操作 COS 中的数据,而无需花费大量的精力来适应这种转变。由于计算存储的分离实现了数据与集群的生命周期解耦,您可以在需要计算任务时再创建弹性 MapReduce 集群,在计算完成时完全销毁集群,在此期间只需要按照使用时长付费。
集群管控
弹性 MapReduce 已对开源 Hadoop 及组件进行了针对性优化,这将减少您用于监控运维集群的时间。同时我们提供了丰富的集群管控工具,您可以在弹性 MapReduce 的控制台可视化地进行监控的查看、告警的设置、组件进程的重启或维护、参数配置修改等操作。您也可以使用我们提供的高级管理工具,自由度更高的管理您的集群。
应用场景
云迁移
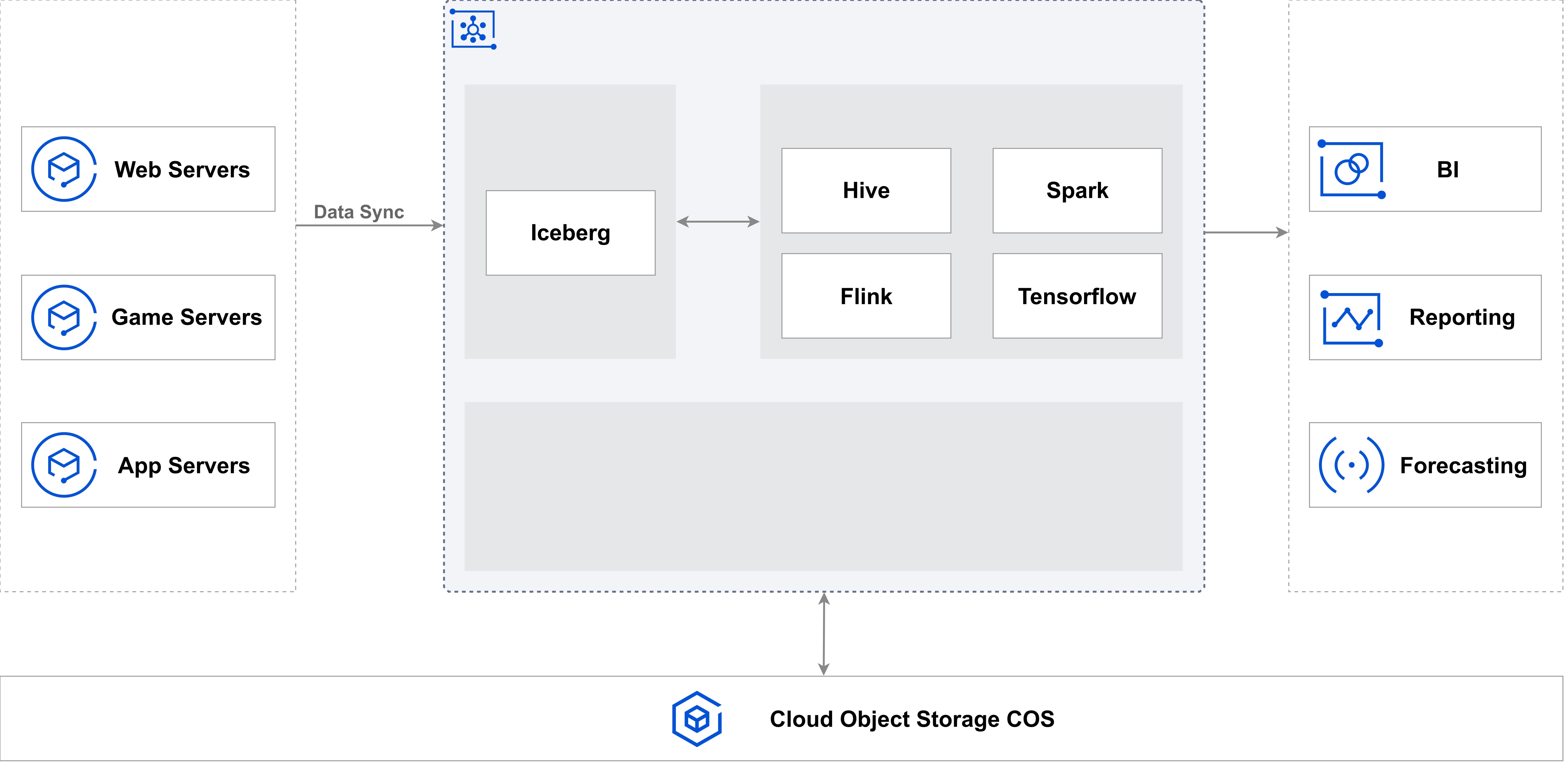
云原生数据湖
离线数据分析
交互式业务查询
流数据处理
基于自建数据中心或开源 Hadoop 发行版构建的自管组件通常存在技术栈复杂、组件版本过时、运维成本高以及技术支持有限等问题。EMR 提供全面的迁移工具套件,可实现无缝迁移,从而快速部署先进、稳定、高性能且经济高效的云原生大数据平台。
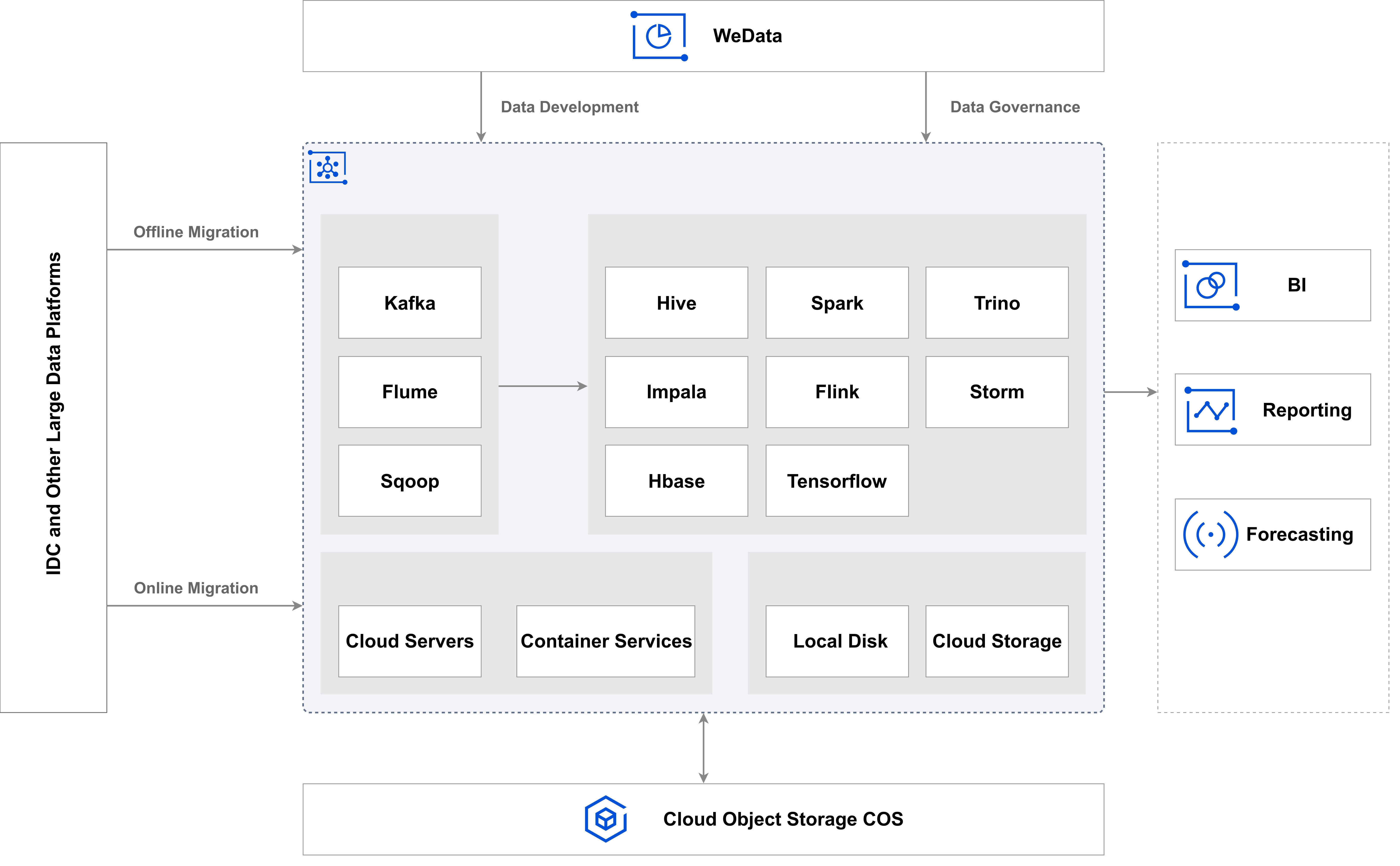
随着企业不断挖掘海量数据的价值,传统架构已无法满足经济高效、统一的数据存储和管理需求,也无法灵活支持跨多种场景的数据分析任务。基于 EMR 构建的云原生数据湖能够有效解决这些挑战。
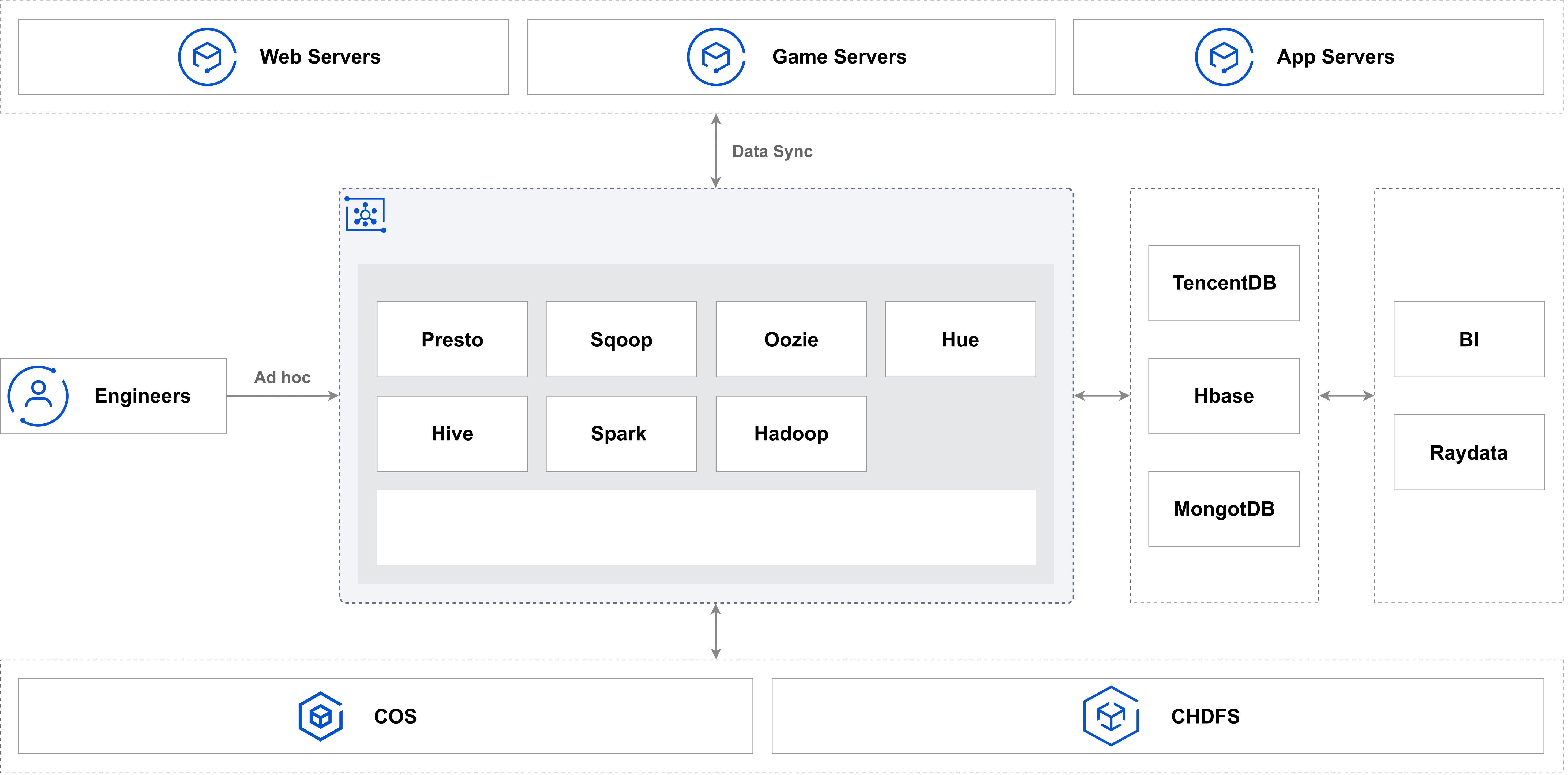
基于 Hadoop 的离线数据仓库可以利用 Hue 等工具访问主流计算框架(包括 Hive、Spark 和 Presto),从而快速获取可操作的数据洞察。
在互联网金融、游戏和O2O等行业,迫切需要对结构化和半结构化数据(例如用户行为、系统日志和订单)进行高效分析。EMR凭借其丰富的计算组件、分钟级的集群配置和横向扩展能力,支持实时交互式业务查询,并提高业务响应速度。
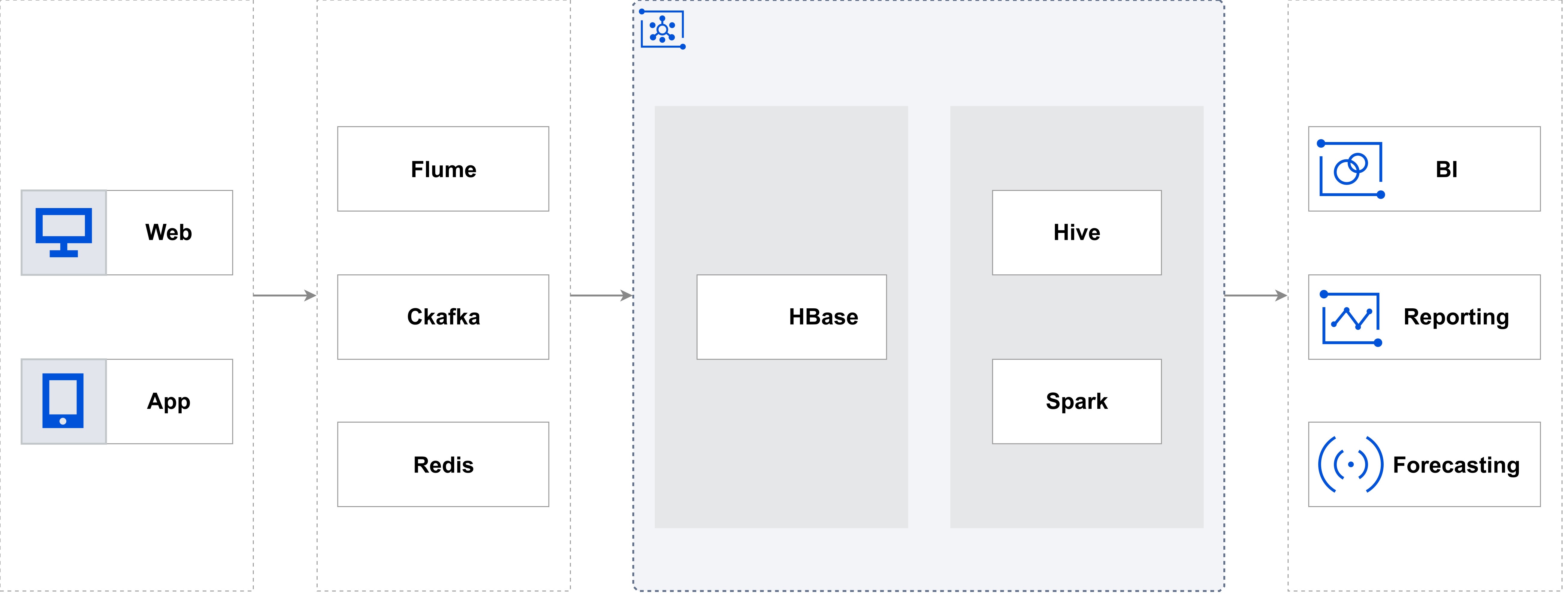
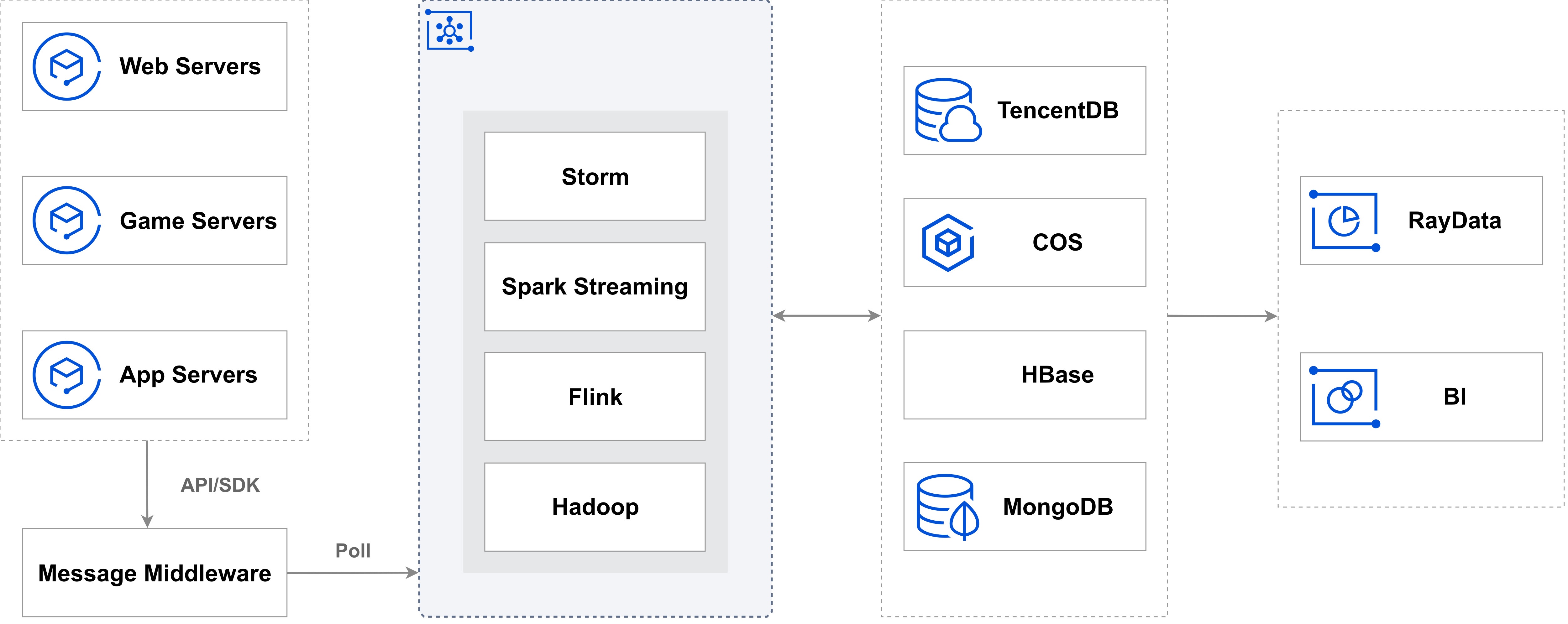
通过应用程序或工具中的API和SDK将业务服务器生成的实时数据推送至消息中间件后,您可以在EMR中选择合适的流数据处理引擎来分析数据,从而实现实时数据计算和决策。
定价
腾讯云弹性MapReduce (EMR) 提供灵活的部署和计费选项。计费精确到节点级别——您可以选择不同规格的节点组成集群,并根据业务波动进行动态扩缩容。更多详情,请参阅计费概述。