df = spark.sql("SELECT * FROM WeData_demo_db.user_demo")
count = df.count()
print("The number of rows in the dataframe is:", count)
Parameter Description
Parameter
Description
Python version
Supports Python 2 and Python 3.
Use the Python Environment Of the Scheduling Resource Group In a PySpark Task
Install Python Libraries In the Scheduling Resource Group
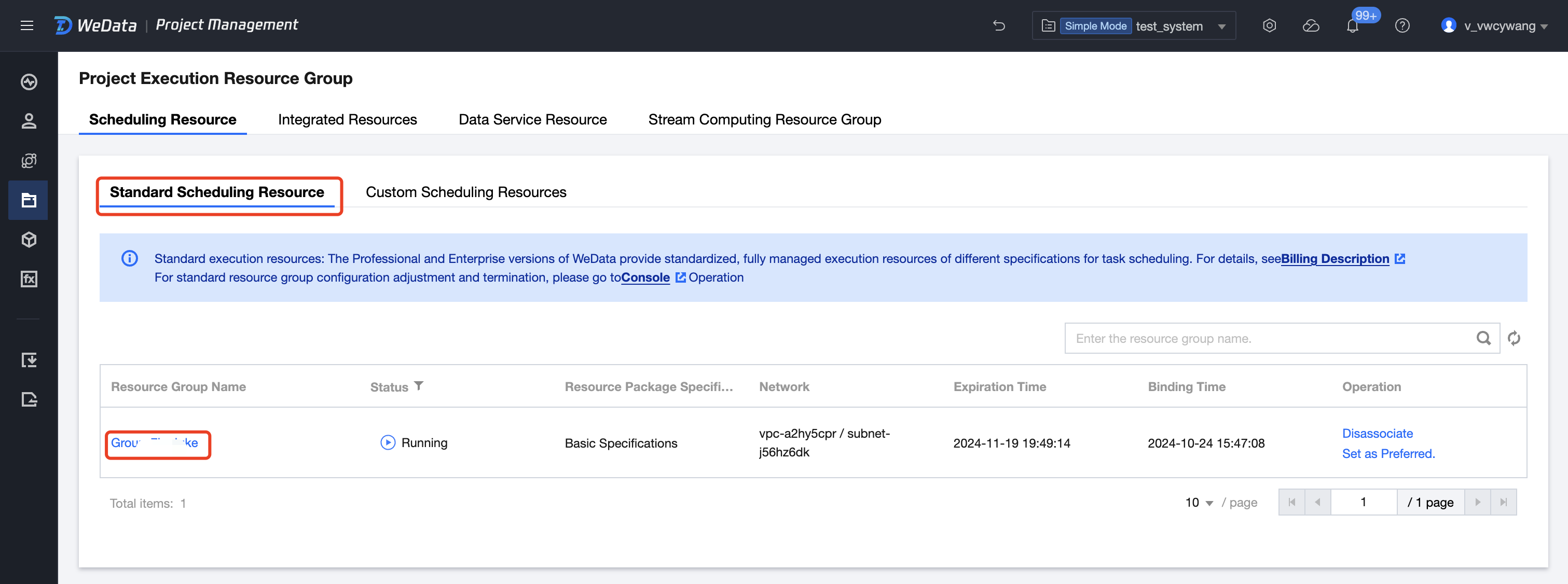
1. Go to Project Management > Execution Resource Group > Standard Scheduling Resource Group interface, click Resource Detail to enter the resource operation and maintenance interface.
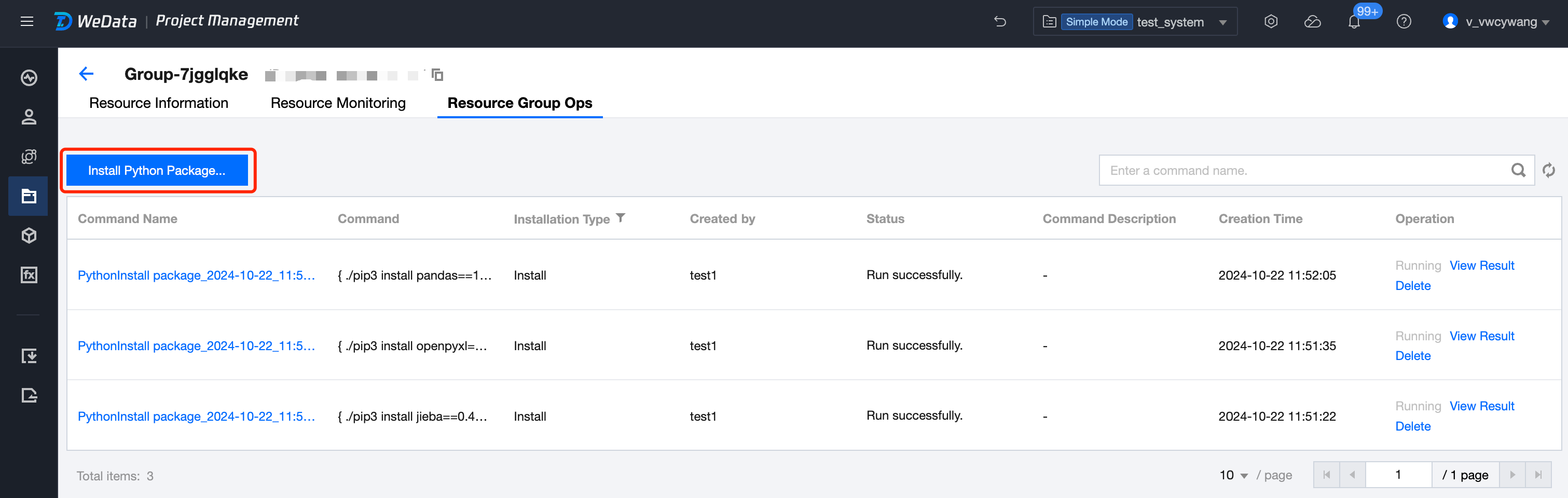
2. In the resource operation and maintenance interface, click Python Package Installation to install built-in Python libraries. It is recommended to install the Python 3 version.
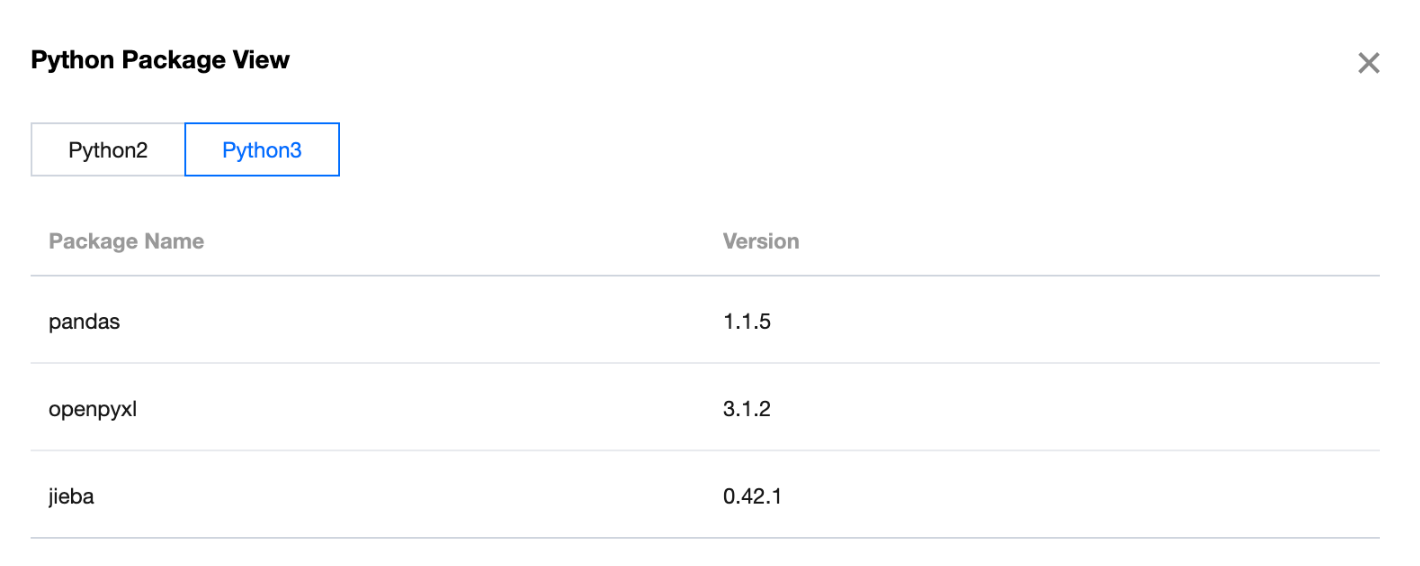
3. Currently, the platform only supports the installation of built-in libraries. Here, install the sklearn and pandas libraries. After the installation is complete, you can use the Python Package View feature to view the installed Python libraries.
Edit PySpark Task
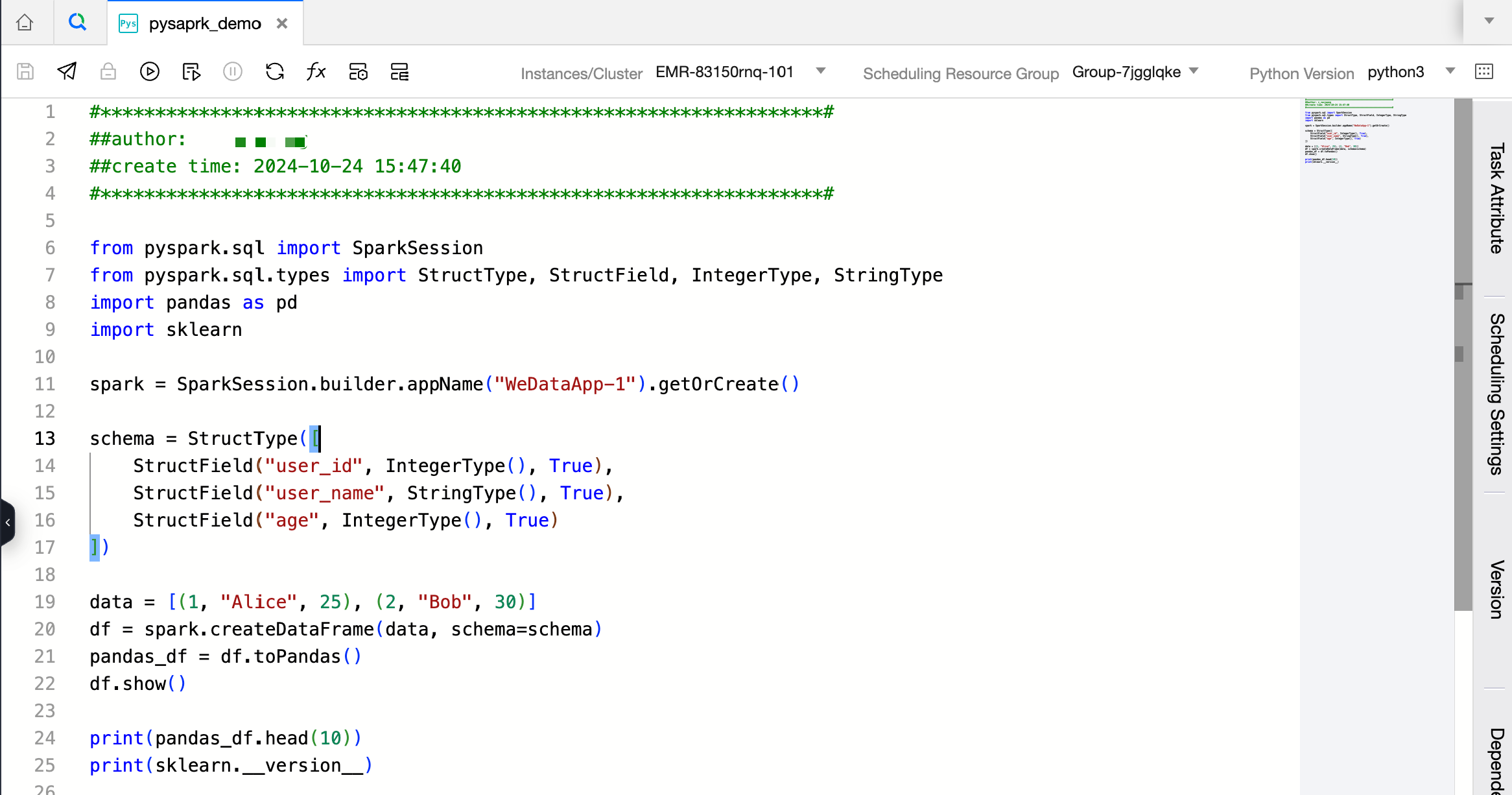
1. Create a task and select a scheduling resource group that has Python packages installed.
2. Write PySpark code using Python libraries, including pandas and sklearn here.
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, IntegerType, StringType
import pandas as pd
import sklearn
spark = SparkSession.builder.appName("WeDataApp-1").getOrCreate()
schema = StructType([
StructField("user_id", IntegerType(),True),
StructField("user_name", StringType(),True),
StructField("age", IntegerType(),True)])
data =[(1,"Alice",25),(2,"Bob",30)]
df = spark.createDataFrame(data, schema=schema)
pandas_df = df.toPandas()
df.show()print(pandas_df.head(10))print(sklearn.__version__)
Debug PySpark Task
1. Click debugging and running to view the logs and results of debugging and running.
Example: In the logs, you can see that the Python environment using the scheduling resource group is used as the environment for task execution.
2. By viewing the log results, you can see that the installed pandas library is used and the version of the installed scikit-learn library is correctly printed.
Periodic Scheduling Of PySpark Tasks
Perform periodic scheduling runs and view the logs and results of the debugging runs. In the logs, you can see that the Python environment using the scheduling resource group is used as the environment for task execution.