Horizontal Pod Autoscaler (HPA) can automatically scale the number of Pods for services according to the average CPU utilization of target Pods and other metrics. This document describes how to implement Pod autoscaling via Tencent Cloud TKE console.
How it Works
The HPA backend components pull monitoring metrics of containers and Pods from Tencent Cloud’s Cloud Monitor every 15 seconds and calculate the desired number of replicas based on the current monitoring data, the current number of replicas, and the desired value of the metrics. When there is a gap between the desired number and the actual number of replicas, HPA will trigger a Deployment to adjust the number of Pod replicas, thereby achieving auto-scaling.
Take CPU utilization as an example. Suppose there are two Pods with an average CPU utilization of 90%, and the target CPU utilization is set to 60% for autoscaling. Then the number of Pods will be automatically adjusted as follows: 90% × 2 / 60% = 3 Pods.
Note:
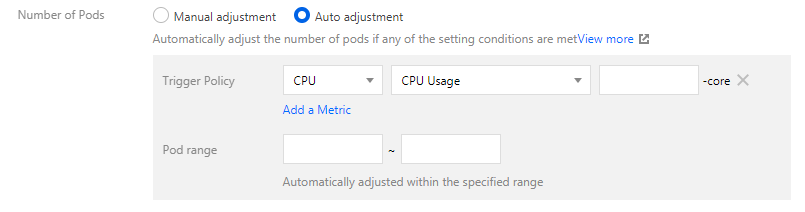
If you set multiple auto scaling metrics, HPA will separately calculate the target numbers of replicas according to each metric and then take the maximum number to use for auto scaling.
Notes
If you choose CPU utilization (by request) as the metric type, a CPU request must be set for the container.
Set reasonable targets for the policy metrics. For example, set 70% for containers and applications and leave 30%.
Keep Pods and nodes healthy; avoid frequently recreating Pods.
Ensure that the load balancer works stably.
If the gap between the actual number and desired number of replicas is smaller than 10%, HPA will not adjust the number of replicas.
If the value of Deployment.spec.replicas corresponding to the service is 0, HPA will not work.
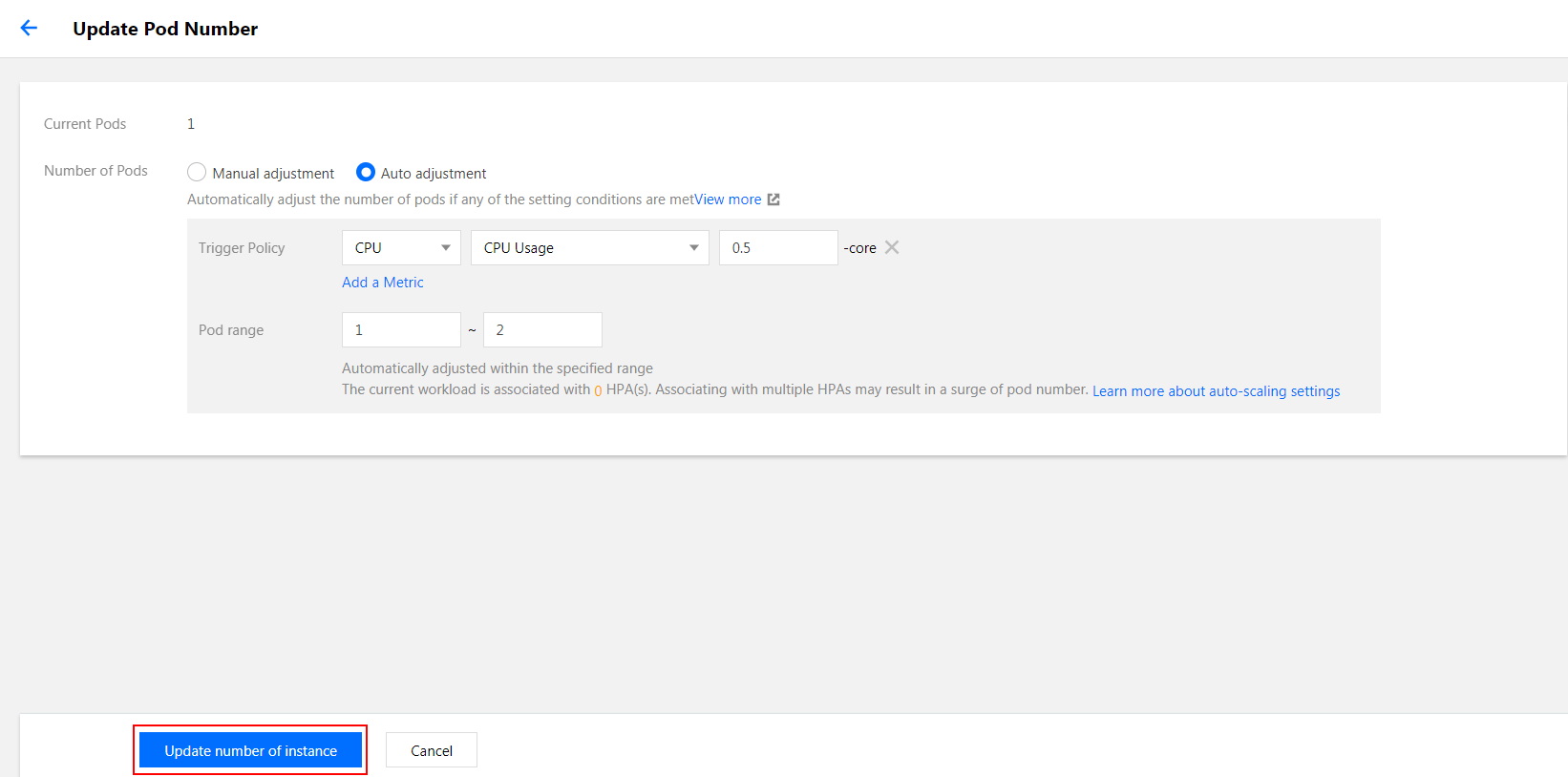
If multiple HPAs are bound to a single Deployment, the HPAs will take effect simultaneously, which will cause workload replicas to be repeatedly scaled.
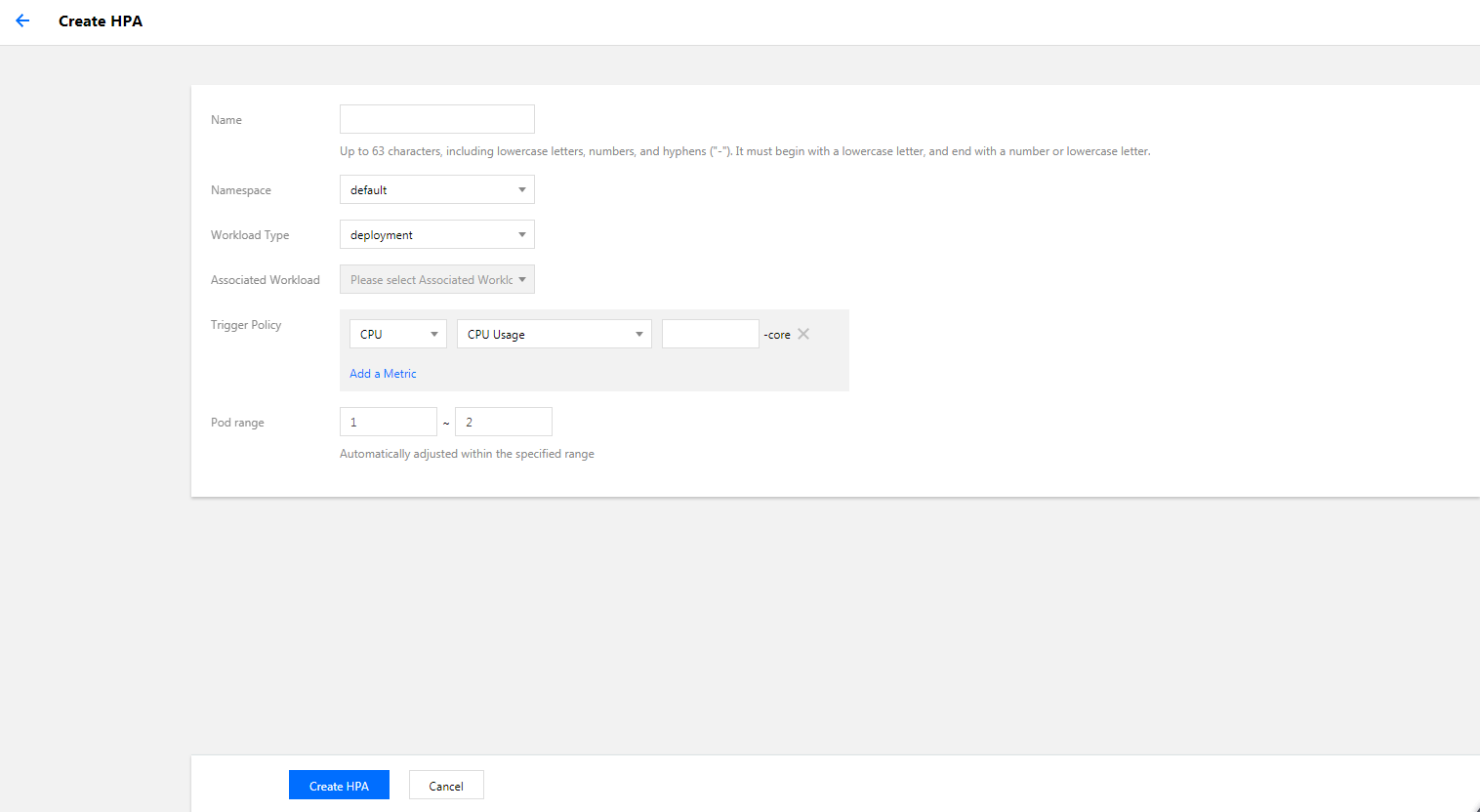
2. Select Workload > Deployment to enter the Deployment page and click Update Pod Number.
3. On the Update Pod Number page, select Auto adjustment and set parameters as needed.
4. Click Update number of instance.
Modifying HPA Configuration
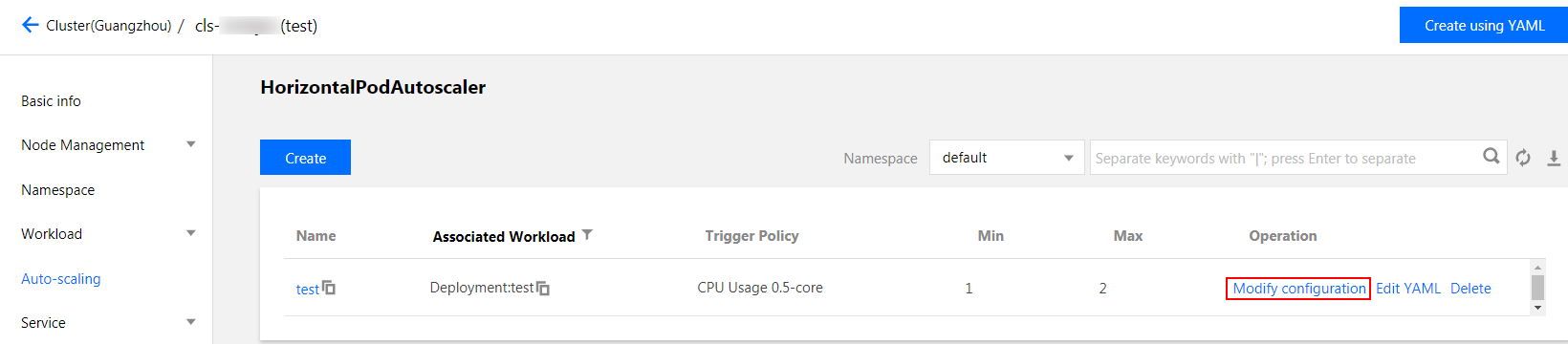
1. On the Cluster Management page, click the cluster ID for which a scaling group is to be created.
2. Select Auto Scaling > HorizontalPodAutoscaler. On the HorizontalPodAutoscaler page, click Modify configuration in the Operation column of the HPA whose configuration is to be updated.
3. On the Update Configuration page, change the settings according to your needs and click Update HPA.
Editing YAML
1. On the Cluster Management page, click the cluster ID for which a scaling group is to be created.
2. Select Auto Scaling > HorizontalPodAutoscaler. On the HorizontalPodAutoscaler page, click Edit YAML in the Operation column of the HPA whose configuration is to be updated.
3. On the Edit YAML page, edit parameters as needed and click Complete.
Metric Type
For more information on metrics and types, see HPA Metrics.