GPU Manager is an all-in-one GPU manager. It is implemented based on the Kubernetes Device Plugin system. This manager provides features such as assigning shared GPU, querying GPU metrics, and preparing GPU-related devices before running a container. It supports your use of GPU devices in Kubernetes clusters.
Add-on features
Topology assignment: provides an assignment feature based on GPU topology. When you assign an application with more than one GPU card, it can select the fastest topology link method to assign the GPU device.
GPU sharing: allows you to submit tasks with less than one GPU card, and supplies QoS assurance.
Querying application GPU metrics: You can access the /metric path of the CVM port (by default this is 5678) to provide GPU metrics collection feature for Prometheus, and can access the /usage path to perform state querying of readable containers.
Kubernetes objects deployed in a cluster
Kubernetes Object Name
Type
Recommended Resource Reservation
Namespaces
gpu-manager-daemonset
DaemonSet
Each node: 1-core CPU, 1 Gi memory
kube-system
gpu-quota-admission
Deployment
Each node: 1-core CPU, 1 Gi memory
kube-system
Use Cases
When the GPU application is running in a Kubernetes cluster, it can prevent the waste of resources caused by requesting a whole card in scenarios such as AI training, allowing full utilization of resources.
Limits
This add-on is implemented through Kubernetes Device Plugin. It can be directly used on clusters of Kubernetes version 1.10 and above.
Each GPU card is split into 100 shares. The usage of GPU can only be a between 0.1 to 0.9, or an integer. VRAM resources are assigned memory with 256MiB as the smallest unit.
To use GPU-Manager, the cluster must contain GPU model nodes.
Directions
Installing the add-on
1. Log in to the TKE console and select Cluster in the left sidebar.
2. On the Cluster Management page, click the ID of the target cluster to go to the cluster details page.
3. In the left sidebar, click Add-on Management to go to the Add-on List page.
4. On the "Add-On List" page, click Create. On the "Create an Add-On" page that appears, select GpuManager.
5. Click Done to complete the process.
Creating fine-grained GPU workloads
After the GpuManager add-on is successfully installed, you can use the following two methods to create fine-grained GPU workloads.
Method 1: creating through the TKE Console
1. Log in to the TKE console and select Clusters in the left sidebar.
2. Select the cluster for which you want to create the GPU application to go to the workload management page, and click Create.
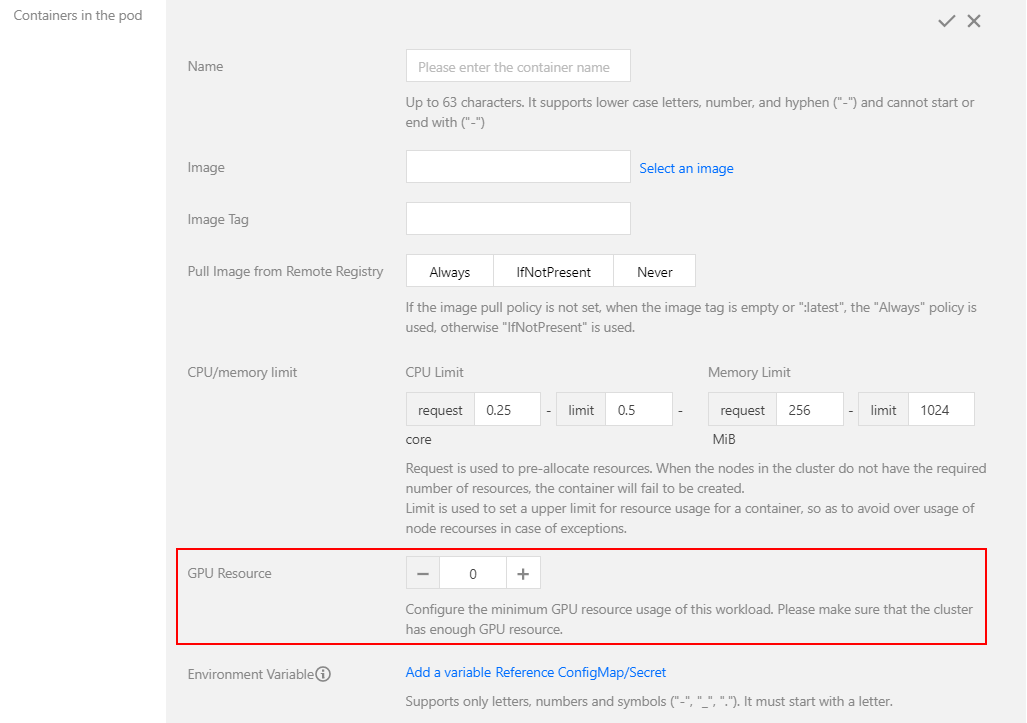
3. On the Create a Workload page, set the configuration as needed. You can configure a fine-grained GPU workload in GPU Resource, as shown below:
Method 2: creating through YAML
Note:
When submitting, use YAML to set the GPU resource usage for the container. The core resources must have tencent.com/vcuda-core entered in "resource". The VRAM resources must have tencent.com/vcuda-memory entered in "resource".