TCInsight Overview
Download
フォーカスモード
フォントサイズ
Elastic MapReduce (EMR) TCInsight is a comprehensive automated governance product for EMR. Its purpose is to combine advanced AI technology to implement data collection, exception identification and prediction, root cause analysis, cluster governance, and cost optimization during the operation of the EMR big data cluster system. The goal is to replace high labor costs with increasingly mature intelligent AI capabilities, shorten issue discovery and exception handling time efficiency through continuous, iterative, high-speed algorithm computation, thereby enabling cluster stability.
Introduction to TCInsight Capabilities
Resource Insights: Helps users fully understand the system's resource usage. Through storage insights and queue resource insights, users can optimize resource usage, improve resource utilization, and enhance query engine execution efficiency.
Exception Center: Covers exception issues across multiple dimensions, including basic diagnosis and resource insights. This feature presents exception message, diagnosis results, and processing suggestions in a unified, time-ordered manner. Additionally, by leveraging analysis and prediction technologies on historical and current monitoring data, it predicts potential exceptions, enabling alerts and interventions.
Policy Center: Offers various engine alert configuration policies. Users can flexibly adjust policy diagnostic thresholds, cold/hot time for stored files and tables, and insight parameters for computing jobs based on business attribute requirements and cluster resource status.
Root Cause Analysis: Helps users quickly identify surface-level issues in the cluster. Through multi-dimensional analysis, this feature identifies the underlying root causes and provides targeted handling solutions based on expert experience, enhancing system stability and improving Ops time efficiency.
TCInsight Architecture Diagram
The product structure diagram of the TCInsight is as follows:
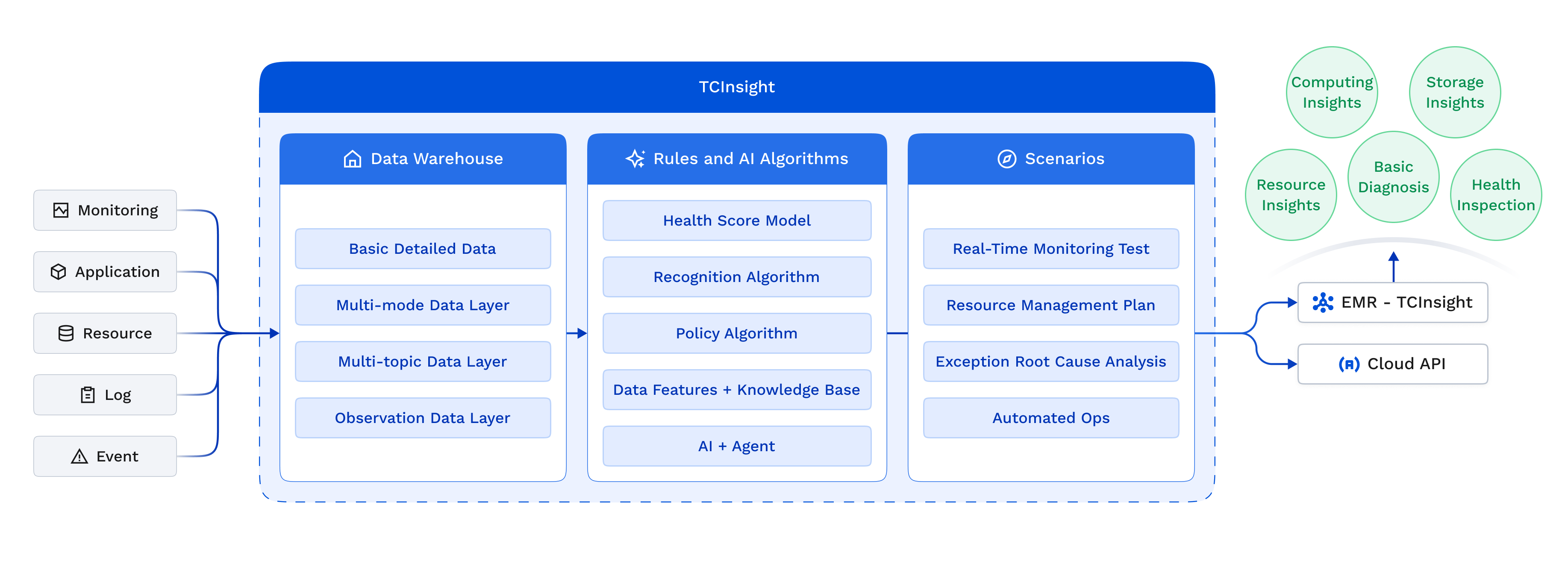
TCInsight consists of 3 components: an Ops data warehouse, rules and AI algorithms, and application capabilities tailored to specific scenarios.
Data Warehouse: Centralized collection of massive multi-dimensional data from clusters, including basic monitoring metrics, query applications, computing and storage resources, system business logs, and customization events. After cleaning, integration, and modeling, this feature provides a high-quality, unified data foundation for upper-layer applications.
Rules and AI Algorithms: This feature leverages preset business policy rules and AI algorithms to identify exceptions, perform root cause analysis and fault prediction using multi-dimensional data, and generate insight optimization policies and decision-making solutions.
Scenarios: This feature converts data and algorithm capabilities into actual business solutions, covering diverse scenarios, including real-time detection, intelligent recommendation, exception detection, and automated decision-making to drive business optimization and easy-to-use Ops.
TCInsight as an Online Manager for Open-Source Big Data Clusters: Feature Objectives
Big Data TCInsight integrates AI capabilities and efficient algorithms to achieve full-chain automation governance of big data products, improving Ops efficiency and reducing Ops costs.
Through comprehensive inspections at all levels, it provides optimization suggestions for key engines, continuously ensuring the long-term stability of cluster resources and engines.
Through offering full insights into key engines, including resources and storage, this feature provides effective governance suggestions for storage and reasonable allocation policies for resources, ensuring efficient utilization of cluster resources.
By fully analyzing multi-dimensional data on the query execution engine, it proposes actionable SQL optimization policies and parameter tuning policies, supports task chain scheduling and homologous task identification, and ensures smooth operation of data processing and computation topology.
Cluster Ops Feature Usage Notes
Cluster Stability: This feature includes basic diagnosis, big data health status diagnosis (focusing on offline engines), and bad query identification, supporting YARN, HDFS, Hive, Spark, Trino, and other engines.
Cluster Efficiency: This feature ensures the efficient use of cluster storage and computing resources, efficient operation of query tasks, and timely handling of identified exception queries and bad SQL.
Feature Enablement Description: The TCInsight is currently in grayscale release. If you need this feature, submit a ticket to request enablement.
フィードバック