概念紹介
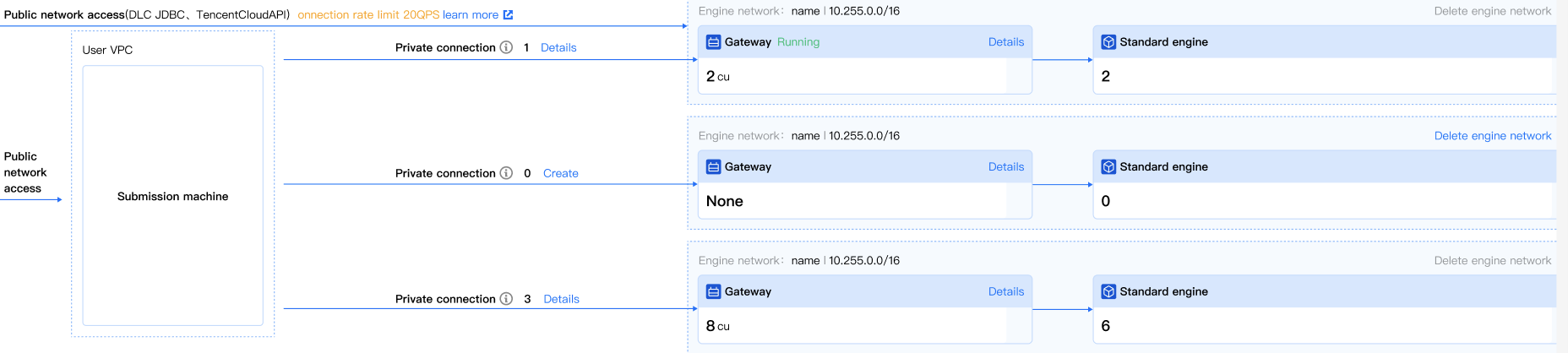
エンジンネットワークは VPC に基づいて構築され、計算エンジン(標準sparkエンジン、標準prestoエンジン)に固定ネットワークアドレス(例:10.255.0.0/16)を割り当てます。各エンジンネットワークにはゲートウェイが提供され、外部からエンジンネットワーク内の標準エンジンにアクセスするために使用されます。例えば、JDBCを通じて社内ネットワーク(VPC)または公衆ネットワークから計算エンジンにアクセスできます。 注意:
異なるVPCのリソースにアクセスする必要がある場合、例えばDLCエンジンを通じてEMR HDFSデータにアクセスしたい場合、IP数が十分で他の製品との使用に衝突しないネットワークセグメントを選択してください。同じエンジンネットワークの下で複数の計算エンジンを購入し、ゲートウェイを通じて一括管理することができます。
利用制限
注意:
ネットワークセグメントの設定要件はvpcセグメントの設定と一致させる必要があり、自身で作成する必要があります。また、作成後は変更がサポートされません。
1. 以下のプライベートネットワークセグメントのいずれかを使用できます:
10.0.0.0 - 10.255.255.255(マスク範囲は12~28の間で設定する必要があります)
172.16.0.0 - 172.31.255.255(マスク範囲は12~28の間で設定する必要があります)
192.168.0.0 - 192.168.255.255(マスク範囲は16~28の間で設定する必要があります)
2. エンジンネットワークに十分なIPを持つサブネットを割り当て、大規模なワークロード作成時にIPリソース不足でPodが作成できない事態を防いでください。規模が不確定な場合はデフォルト構成の使用を推奨します。
3. 連邦クエリを使用する場合、エンジンセグメントがデータソースセグメントと重複しないようにしてください。
4. エンジンネットワーク設定:初回購入時にカスタムネットワーク設定が可能です。後で変更が必要な場合は、チケットを提出してください。 ネットワーク分割
各エンジンネットワークはゲートウェイによって管理され、その下の標準エンジンを制御します。適切なネットワーク分割により、ゲートウェイの負荷を効果的に分散させ、単一障害点を防ぐことができます。業務部門ごと、またはタスクタイプごとに分割することをお勧めします。
業務ごとに分割
業務部門ごとに分割することをお勧めします。例:1つの業務部門につき少なくとも1つのエンジンネットワーク。
タスクごとに分割
当社はタスクタイプに基づいて分割することをお勧めします。例:BI分析、データガバナンス、データ分析などの異なるタスクタイプごとに、別々のエンジンネットワークを作成します。
説明:
上記のエンジンネットワークの分割提案は、経験に基づいて提供された参考例です。実際の状況に応じて分割することも可能です。例えば、タスクの規模に応じて、超大規模タスクセットを処理するための専用エンジンネットワークを個別に分割することもできます。
社内ネットワークアクセス
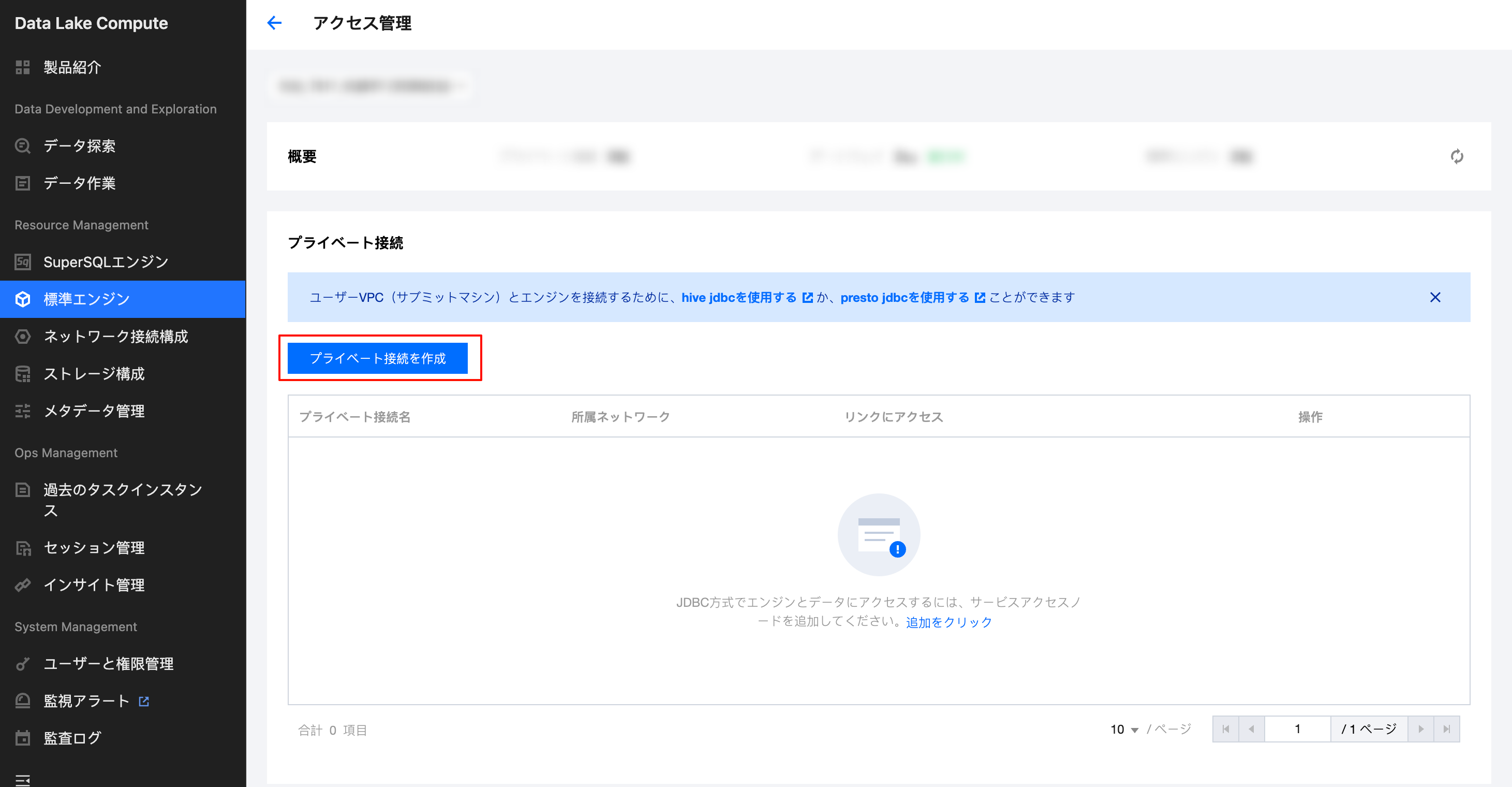
ユーザー側のVPCとゲートウェイ間にプライベート接続を作成することで、安全で安定した接続を確立し、標準エンジンにアクセスできます。標準エンジンのアクセス管理ページで新しいプライベートリンクを作成し、アクセス元のVPCとサブネットを選択します。作成が成功すると、アクセスリンクが取得でき、ソースVPC下の任意のマシンからこのエンジンネットワーク下の標準エンジンに直接アクセスできます。 公衆ネットワークアクセス
公衆ネットワークを介してエンジンネットワーク下の標準エンジンにアクセスすることも可能です。例えば、公衆ネットワークに展開されている一部のBIが公衆ネットワークを介してエンジンに接続する必要がある場合などです。
1. 社内ネットワークアクセスを参考に、プライベートリンクを作成します。例:社内ネットワークアクセス JDBC 接続文字列。
jdbc:hive2://172.22.0.202:10009/?spark.engine={DataEngineName};spark.resourcegroup={ResourceGroupName};secretkey={SecretKey};secretid={SecretId};region=ap-singapore;kyuubi.engine.type=SPARK_SQL;kyuubi.engine.share.level=ENGINE
2. ロードバランサーに移動し、新しいパブリックアクセスインスタンスを作成して、「リスナーを設定」を選択します。 3. 「リスナー設定」画面に入り、「リスナー管理」を選択し、「TCPリスナーを作成」をクリックします。ポートはデフォルトでプライベートリンクポートと同じです。10009(標準sparkにアクセスするため)または10999(標準prestoにアクセスするため)。
4. 作成済みのリスナーにバックエンドサービスをバインドします:IPタイプを選択し、上記で作成したプライベートリンクIPアドレス(例:172.22.0.202)を入力します。ポートは10009(標準sparkにアクセスするため)または10999(標準prestoにアクセスするため)です。
5. CLBが提供するパブリックVIPとポート10009または10999を介してエンジンリソースにアクセスでき、アクセスリンクはパブリックネットワークアクセスに変わります。
jdbc:hive2://{パブリックVIP}:10009/?spark.engine={DataEngineName};spark.resourcegroup={ResourceGroupName};secretkey={SecretKey};secretid={SecretId};region=ap-singapore;kyuubi.engine.type=SPARK_SQL;kyuubi.engine.share.level=ENGINE
エンジン内でのパブリックネットワークアクセス
標準エンジンはデフォルトでパブリックネットワークアクセスをサポートしていません。パブリックネットワークへのアクセスが必要な場合、例えばnotebookでmagic %pipを使用してPythonパッケージをインストールする必要がある場合は、チケットを提出して申請してください。