TKE DNSベストプラクティス
Download
フォーカスモード
フォントサイズ
まとめ
DNSはKubernetesクラスター内のサービスアクセスの第一部分として、その安定性およびパフォーマンスが極めて重要です。どのようにしてより優れた方法でDNSを設定および使用するかは、さまざまな側面があります。このドキュメントではこれらのベストプラクティスをまとめます。
最適なCoreDNSバージョンを選択する
以下の表では各バージョンのTKEクラスターと共にデフォルトでデプロイされるCoreDNSバージョンを示しています。
履歴的原因により、バージョンv1.18以上のクラスターにv1.6.2バージョンのCoreDNSがデプロイされている可能性があります。現在のCoreDNS バージョンがニーズを満たさない場合、以下のガイドに従って手動でアップグレードできます。
適切なCoreDNSレプリカ数を設定する
1. TKEはデフォルトでCoreDNSレプリカ数が2に設定され、かつ
podAntiAffinityを設定して2つのレプリカが異なるノードにデプロイされます。2. ノード数が80以上のクラスターに対して、NodeLocal DNSCacheをインストールすることをお勧めします。詳細はTKEクラスター内でNodeLocal DNS Cacheを使用するをご参照ください
3. 一般的にクラスター内の業務がDNSにアクセスするQPSによってCoreDNSの合理的なレプリカ数を確定します。ノード数および総コア数によって確定することもできます。NodeLocal DNSCacheをインストールした後、CoreDNSの最大レプリカ数を10にすることをお勧めします。以下の方法に従って設定することができます。
レプリカ数=min( max(ceil(QPS/10000)、ceil(クラスターノード数/8))、10)
事例:
クラスターノード数が10、DNSサービスリクエストQPSが 22000の場合、レプリカ数は3です
クラスターノード数が30、DNSサービスリクエストQPSが15000の場合、レプリカ数は4です
クラスターノード数が100、DNSサービスリクエストQPSが50000の場合、レプリカ数は10です(NodeLocal DNSCacheをデプロイ済み)
4. コンソールでDNSAutoScalerコンポーネントをインストールすることによって、CoreDNSレプリカ数(事前にスムーズアップグレードを設定するように注意してください)の自動調整を実現することができます。コンポーネントのデフォルト設定は次のとおりです。
data:ladder: |-{"coresToReplicas":[[ 1, 1 ],[ 128, 3 ],[ 512,4 ],],"nodesToReplicas":[[ 1, 1 ],[ 2, 2 ]]}
NodeLocal DNSCacheを使用する
TKEクラスター内にNodeLocal DNSCacheをデプロイすると、サービスが検出する安定性およびパフォーマンスを向上させることができます。それはノード上でDaemonSetとしてDNSキャッシュプロキシを実行することによってクラスターDNSのパフォーマンスを向上させます。
その他のNodeLocal DNSCacheの紹介およびTKEクラスター内でNodeLocal DNSCacheをデプロイする具体的なステップについては、以下をご参照ください。TKEクラスター内でNodeLocal DNS Cacheを使用する
CoreDNSのスムーズアップグレードを設定する
ノードの再起動またはCoreDNSをアップグレードする時に、CoreDNSの一部のレプリカが一定時間使用できなくなる可能性があります。以下の設定によって、DNSサービスの可用性を最大限保証し、スムーズなアップグレードを実現します。
kube-proxyはiptablesモードです。設定する必要はありません
iptablesモードでは、kube-proxyはiptablesルールを同期した後タイムリーに保持されているconntrackエントリーをクリーンアップするため、セッション維持の問題は存在せず、設定の必要がありません。
kube-proxyはIPVSモードです。IPVS UDPプロトコルのセッション維持タイムアウト時間を設定します
IPVSモードでは、業務自身にUDPサービスがない場合、IPVS UDPプロトコルのセッション維持タイムアウト時間を低下させることによってサービスが利用できなくなる時間を可能な限り減少させます。
1. クラスターバージョンが1.18以上の場合、kube-proxyはパラメータ
--ipvs-udp-timeoutを提供します。デフォルトは0sですが、システムのデフォルト値:300sを使用し、--ipvs-udp-timeout=10sに設定することを推奨します。以下の方法に従ってkube-proxy DaemonSetを設定します。spec:containers:- args:- --kubeconfig=/var/lib/kube-proxy/config- --hostname-override=$(NODE_NAME)- --v=2- --proxy-mode=ipvs- --ipvs-scheduler=rr- --nodeport-addresses=$(HOST_IP)/32- --ipvs-udp-timeout=10scommand:- kube-proxyname: kube-proxy
2. クラスターバージョンが1.16以下の場合、kube-proxyはこのパラメータをサポートしません。
ipvsadmツールを使用してノード側で一括変更することができます:yum install -y ipvsadmipvsadm --set 900 120 10
3. 設定が完了したら、以下の方法で検証します。
ipvsadm -L --timeoutTimeout (tcp tcpfin udp): 900 120 10
注意
CoreDNSのグレースフルシャットダウンを設定する
終了信号を受信したレプリカは、lameduckを設定することにより一定時間内でサービスの提供を継続します。以下の方法に従ってCoreDNSのconfigmapを設定します(CoreDNSバージョン1.6.2の一部の設定のみを表示します。その他のバージョンの設定はCoreDNSの手動アップグレード をご参照ください)。
.:53 {health {lameduck 30s}kubernetes cluster.local. in-addr.arpa ip6.arpa {pods insecureupstreamfallthrough in-addr.arpa ip6.arpa}}
CoreDNS サービス準備の確認を設定する
新しいレプリカを起動した後、そのサービスの準備を確認し、さらにDNSサービスのバックエンドリストを追加する必要があります。
1. readyプラグインを開き、以下の方法に従ってCoreDNSのconfigmapを設定します(CoreDNS 1.6.2バージョンの一部の設定のみを表示します。その他のバージョン設定はCoreDNSの手動アップグレードをご参照ください)。
.:53 {readykubernetes cluster.local. in-addr.arpa ip6.arpa {pods insecureupstreamfallthrough in-addr.arpa ip6.arpa}}
2. CoreDNSにReadinessProbeを追加設定する:
readinessProbe:failureThreshold: 5httpGet:path: /readyport: 8181scheme: HTTPinitialDelaySeconds: 30periodSeconds: 10successThreshold: 1timeoutSeconds: 5
CoreDNSがUDPを使用してアップストリームDNSにアクセスする設定
CoreDNSがアップストリームDNS Serverと通信する必要がある場合、デフォルトでクライアントがリクエストしたプロトコル(UDPまたはTCP)を使用します。TKE内のCoreDNSのアップストリームはデフォルトではVPC内のDNSサービスです。このサービスのTCPに対するサポートはパフォーマンスの制限があるため、以下のように設定し、指定UDPを表示することを推奨します(特にNodeLocal DNSCacheをインストールした場合)。
.:53 {forward . /etc/resolv.conf {prefer_udp}}
CoreDNSを設定してINFOリクエストをフィルタリングする
VPC内のDNSサービスはHINFOタイプのDNSリクエストをサポートしていないため、以下のように設定し、CoreDNS側でこのタイプのリクエストをフィルタリングすることを推奨します(特にNodeLocal DNSCacheをインストールした場合)。
.:53 {template ANY HINFO . {rcode NXDOMAIN}}
CoreDNSを設定してIPv6タイプのAAAA記録に対してドメイン名が存在しないことが返ってくることを確認する
業務がIPv6のドメイン名解決をする必要がない場合、この設定によって通信コストを削減することができます。
.:53 {template ANY AAAA {rcode NXDOMAIN}}
注意
IPv4/IPv6デュアルスタッククラスターはこの設定ができません。
カスタムドメイン名解決の設定
詳細は以下をご参照ください。TKE内でカスタムドメイン名解決を実現する
手動アップグレード
1.7.0にアップグレード
1. coredns configmapの編集
kubectl edit cm coredns -n kube-system
以下の内容に変更します。
.:53 {template ANY HINFO . {rcode NXDOMAIN}errorshealth {lameduck 30s}readykubernetes cluster.local. in-addr.arpa ip6.arpa {pods insecurefallthrough in-addr.arpa ip6.arpa}prometheus :9153forward . /etc/resolv.conf {prefer_udp}cache 30reloadloadbalance}
2. coredns deploymentの編集
kubectl edit deployment coredns -n kube-system
イメージを変換
image: ccr.ccs.tencentyun.com/tkeimages/coredns:1.7.0
1.8.4にアップグレード
1. coredns clusterroleの編集
kubectl edit clusterrole system:coredns
以下の内容に変更します。
rules:- apiGroups:- '*'resources:- endpoints- services- pods- namespacesverbs:- list- watch- apiGroups:- discovery.k8s.ioresources:- endpointslicesverbs:- list- watch
2. coredns configmapの編集
kubectl edit cm coredns -n kube-system
以下の内容に変更します。
.:53 {template ANY HINFO . {rcode NXDOMAIN}errorshealth {lameduck 30s}readykubernetes cluster.local. in-addr.arpa ip6.arpa {pods insecurefallthrough in-addr.arpa ip6.arpa}prometheus :9153forward . /etc/resolv.conf {prefer_udp}cache 30reloadloadbalance}
3. coredns deploymentの編集
kubectl edit deployment coredns -n kube-system
イメージを変換
image: ccr.ccs.tencentyun.com/tkeimages/coredns:1.8.4
業務提案の設定
DNSサービスのベストプラクティス以外に、業務側で、適切な最適化設定をすることでも、DNSの使用体験を向上させることができます。
1. デフォルト状態では、Kubernetesクラスター内のドメイン名解決は多くの場合、複数回のリクエストによって解決する必要があります。pod内の
/etc/resolv.confを確認するとndotsオプションがデフォルトで5であることがわかります。例えば、debugネームスペースで kubernetes.default.svc.cluster.localというserviceを照会します。ドメイン名に4つの
.があり、5未満の場合、スプライシングを試みて最初のsearchの照会を行います。すなわちkubernetes.default.svc.cluster.local.debug.svc.cluster.localで、このドメイン名は見つかりません。継続して
kubernetes.default.svc.cluster.local.svc.cluster.localを試みても、このドメイン名は見つかりません。継続して
kubernetes.default.svc.cluster.local.cluster.localを試みても、依然としてこのドメイン名は見つかりません。拡張子、すなわち
kubernetes.default.svc.cluster.localを追加せずに試み、照会に成功すると、対応するClusterIPを返します。2. 上記の簡単なserviceドメイン名解決は4回の解決に成功する必要があり、クラスター内には大量の不要なDNSリクエストに溢れています。そのため業務設定のアクセス方法に基づいてその合理的なndotsを設定することによって照会回数を低下させます。
spec:dnsConfig:options:- name: ndotsvalue: "2"containers:- image: nginximagePullPolicy: IfNotPresentname: diagnosis
3. 同時に、業務アクセスサービスのドメイン名設定を最適化することができます。
PodはこのネームスペースのServiceにアクセスし、
<service-name>を使用してアクセスします。Podはその他のネームスペースの Serviceにアクセスし、
<service-name>.<namespace-name>を使用してアクセスします。Podは外部ドメイン名にアクセスし、 FQDNタイプのドメイン名を使用してアクセスします。ドメイン名の最後に
.を追加することによって無効な検索を減少させます。関連する内容
設定紹介
errors
エラー情報を出力します。
health
健康状態を報告し、ヘルスチェックの設定に使用します。例えば、
livenessProbeは、デフォルトのリスナーは8080ポートで、パスはhttp://localhost:8080/healthです注意
複数のServerブロックがある場合、healthは1回だけ、または異なるポートで設定できます。
com {whoamihealth :8080}net {erratichealth :8081}
lameduck
グレースフルシャットダウンの時間を設定するために使用されます。実現方法はhookがCoreDNSで終了信号を受信した時に、その中でsleepを実行することによって、制限時間内に継続してサービスを提供することを保証します。
ready
プラグイン状態を報告し、サービス準備チェックの設定に使用します。例えば
readinessProbeは、デフォルトのリスナーが8181ポートで、パスはhttp://localhost:8181/readyですkubernetes
Kubernetesプラグインは、クラスター内のサービス解析をサポートしています。
prometheus
metricsデータインターフェースは、監視データの取得に使用されます。パスは
http://localhost:9153/metricsですforward(proxy)
処理できないリクエストをアップストリームDNSサーバーに転送します。デフォルトはホストの
/etc/resolv.confを使用して設定します。forward aaa bbbの設定に基づいて、内部にudnsのリスト[aaa,bbb]が保持されます
リクエストが届いた時、プリセットポリシー(random|round_robin|sequential、デフォルトではrandom)に基づき、リスト [aaa,bbb]内でudnsが送信するリクエストを見つけます。失敗した場合、次のudnsで試し、同時に失敗したudnsに対して定期的なヘルスチェックを開始し、正常になるまで、ヘルスチェックを行います。
ヘルスチェックのプロセスで、連続数回(デフォルトでは2回)監視に失敗した場合、そのudnsステータスをdownに設定します。その後リストからudnsを選択する時にステータスがdownのudnsをスキップします。
すべてのudnsがdownの場合、ランダムに1つのudnsを選択して転送します。
このため、corednsには複数のupstream間のインテリジェント切り替えの機能があると考えることができ、forwardリスト内に利用可能なudnsが1つあれば、リクエストは成功します。
cache
DNSキャッシュです。
reload
Corefileをホットリロードし、ConfigMapを変更した後、2分以内に新しい設定をロードします。
loadbalance
DNSに基づくCLB機能を提供し、ランダムにレコードの順序に応答します。
CoreDNSリソース占有
主にクラスター内のPod数およびService数によって決まります。
開いているキャッシュサイズの影響を受けます。
QPSの影響を受けます。
以下のデータはCoreDNS公式からのものです。
MB required (default settings) = (Pods + Services) / 1000 + 54
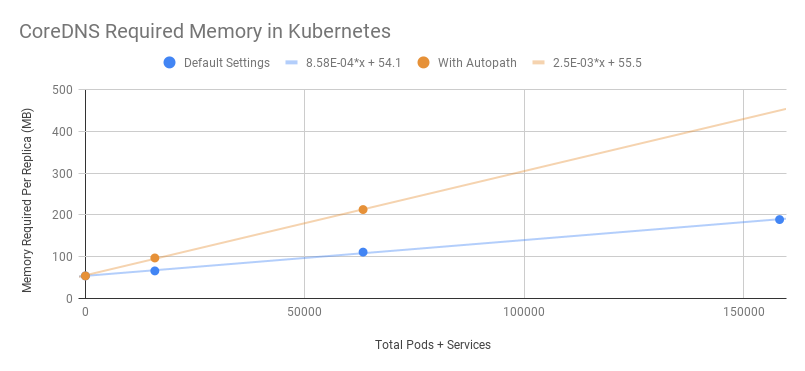
主にQPSの影響を受けます。
以下のデータはCoreDNS公式からのものです。
単一レプリカのCoreDNS、実行ノード仕様:2 vCPUs、7.5 GB memory
Query Type | QPS | Avg Latency (ms) | Memory Delta (MB) |
external | 6733 | 12.02 | +5 |
internal | 33669 | 2.608 | +5 |
フィードバック