CHDFS 생성
권한 그룹 생성
권한 규칙 생성
마운트 포인트 생성
CHDFS 마운트
CAM 라이선스로 액세스
Java 코드로 CHDFS 액세스
파일 시스템 삭제
모듈 이름 | CHDFS 빅 데이터 모듈 지원 현황 | 서비스 모듈 재시작 필요 여부 |
Yarn | 지원 | NodeManager 재시작 |
Yarn | 지원 | NodeManager 재시작 |
Hive | 지원 | HiveServer 및 HiveMetastore 재시작 |
Spark | 지원 | NodeManager 재시작 |
Sqoop | 지원 | NodeManager 재시작 |
Presto | 지원 | HiveServer, HiveMetastore, Presto 재시작 |
Flink | 지원 | 필요 없음 |
Impala | 지원 | 필요 없음 |
EMR | 지원 | 필요 없음 |
자체구축 모듈 | 향후 지원 | 없음 |
HBase | 권장하지 않음 | 없음 |

<property><name>fs.AbstractFileSystem.ofs.impl</name><value>com.qcloud.chdfs.fs.CHDFSDelegateFSAdapter</value></property><property><name>fs.ofs.impl</name><value>com.qcloud.chdfs.fs.CHDFSHadoopFileSystemAdapter</value></property><!--로컬 cache의 임시 디렉터리로, 데이터 읽기/쓰기의 경우 메모리 cache가 부족할 때는 로컬 디스크에 쓰기 하고 관련 경로가 없을 때는 자동 생성합니다.--><property><name>fs.ofs.tmp.cache.dir</name><value>/data/emr/hdfs/tmp/chdfs/</value></property><!--appId--><property><name>fs.ofs.user.appid</name><value>1250000000</value></property>
CHDFS 설정 항목 | 값 | 의미 |
fs.ofs.user.appid | 1250000000 | 사용자 appid |
fs.ofs.tmp.cache.dir | /data/emr/hdfs/tmp/chdfs/ | 로컬 cache 의 임시 디렉터리 |
fs.ofs.impl | com.qcloud.chdfs.fs.CHDFSHadoopFileSystemAdapter | FileSystem에 대한 chdfs의 구현 클래스, com.qcloud.chdfs.fs.CHDFSHadoopFileSystemAdapter으로 고정 |
fs.AbstractFileSystem.ofs.impl | com.qcloud.chdfs.fs.CHDFSDelegateFSAdapter | AbstractFileSystem에 대한 chdfs의 구현 클래스, com.qcloud.chdfs.fs.CHDFSDelegateFSAdapter으로 고정 |
cp chdfs_hadoop_plugin_network-2.0.jar /opt/cloudera/parcels/CDH-5.16.1-1.cdh5.16.1.p0.3/lib/hadoop-hdfs/
hadoop jar ./hadoop-mapreduce-examples-2.7.3.jar teragen -Dmapred.map.tasks=4 1099 cosn://examplebucket-1250000000/teragen_5/hadoop jar ./hadoop-mapreduce-examples-2.7.3.jar terasort -Dmapred.map.tasks=4 cosn://examplebucket-1250000000/teragen_5/ cosn://examplebucket-1250000000/result14
ofs://schema 뒷부분을 사용자 CHDFS의 마운트 포인트 경로로 변경하십시오.CREATE TABLE `report.report_o2o_pid_credit_detail_grant_daily`(`cal_dt` string,`change_time` string,`merchant_id` bigint,`store_id` bigint,`store_name` string,`wid` string,`member_id` bigint,`meber_card` string,`nickname` string,`name` string,`gender` string,`birthday` string,`city` string,`mobile` string,`credit_grant` bigint,`change_reason` string,`available_point` bigint,`date_time` string,`channel_type` bigint,`point_flow_id` bigint)PARTITIONED BY (`topicdate` string)ROW FORMAT SERDE'org.apache.hadoop.hive.ql.io.orc.OrcSerde'STORED AS INPUTFORMAT'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'OUTPUTFORMAT'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'LOCATION'cosn://examplebucket-1250000000/user/hive/warehouse/report.db/report_o2o_pid_credit_detail_grant_daily'TBLPROPERTIES ('last_modified_by'='work','last_modified_time'='1589310646','transient_lastDdlTime'='1589310646')
select count(1) from report.report_o2o_pid_credit_detail_grant_daily;
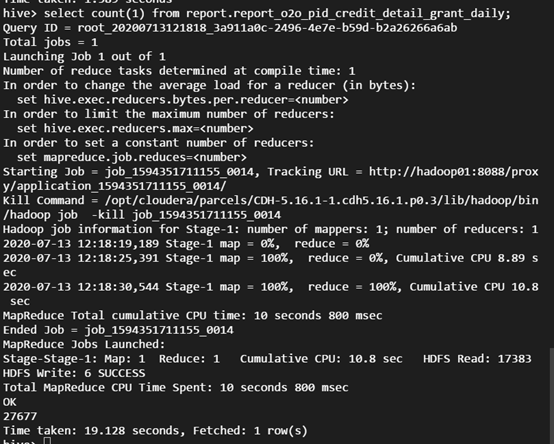
spark-submit --class org.apache.spark.examples.JavaWordCount --executor-memory 4g --executor-cores 4 ./spark-examples-1.6.0-cdh5.16.1-hadoop2.6.0-cdh5.16.1.jar cosn://examplebucket-1250000000/wordcount
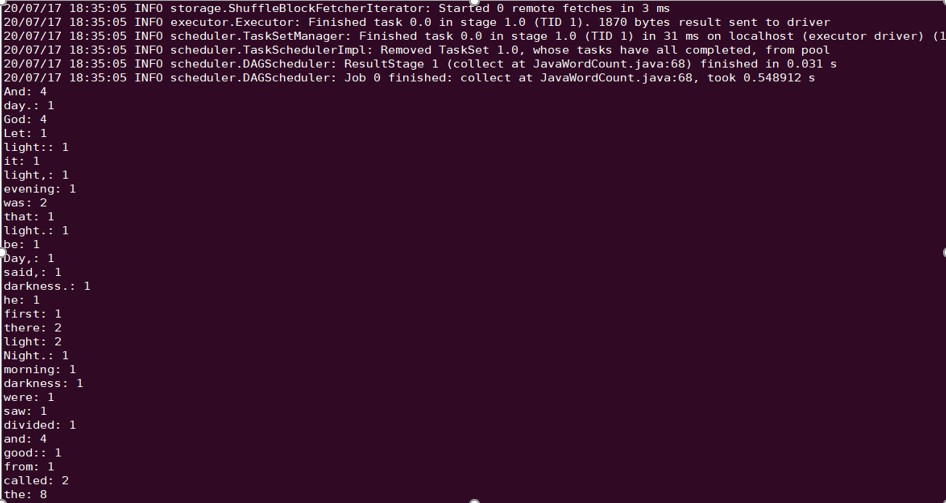
sqoop import --connect "jdbc:mysql://IP:PORT/mysql" --table sqoop_test --username root --password 123 --target-dir cosn://examplebucket-1250000000/sqoop_test
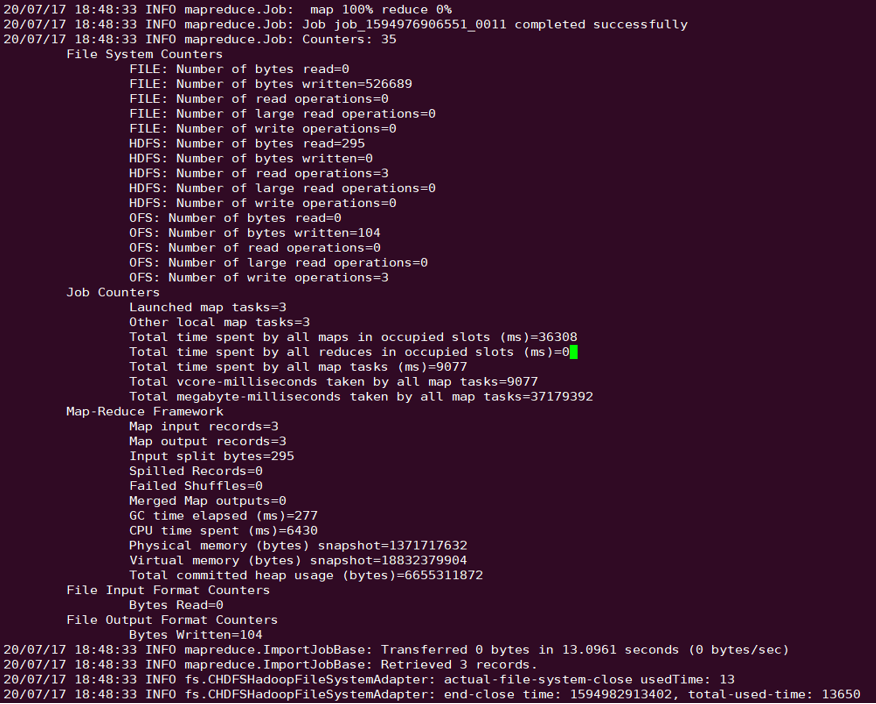
select * from chdfs_test_table where bucket is not null limit 1;

피드백