Distributed Transaction Model: Read/Write Phase
Distributed transaction design aims to ensure both correctness and efficiency. As business scale continues to expand, higher demands are placed on the load capacity of database systems. To address such high-concurrency scenarios, thorough optimization of transaction read/write and commit processes is essential.
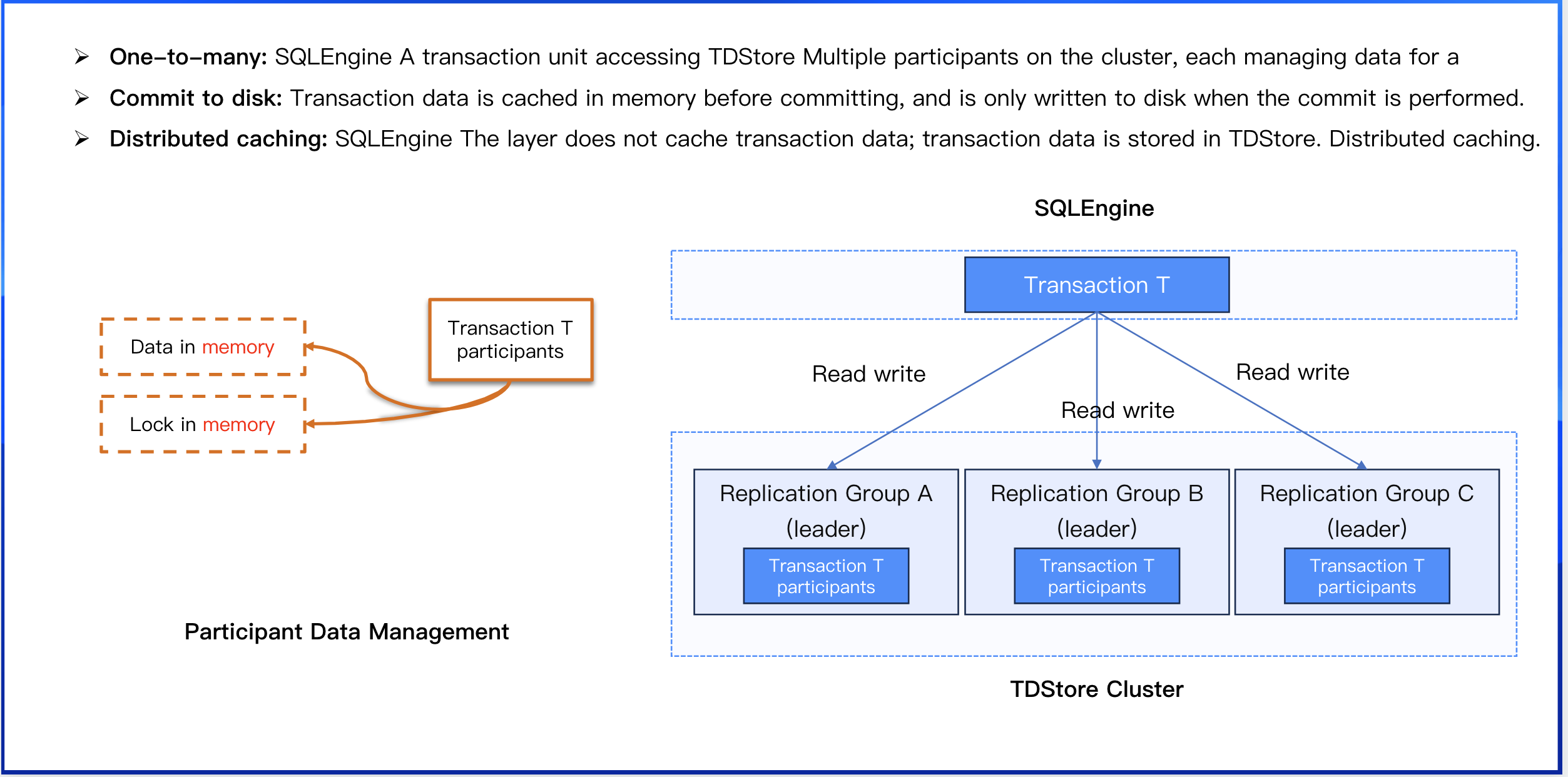
Participant Management: Manages transaction participants with the replication group (RG) as the basic unit. When a transaction needs to access data of a specific replication group, it automatically creates the corresponding participant context. A transaction unit of SQLEngine accesses multiple participants on the TDStore cluster, with each participant managing the data of one Replication Group.
Transaction Model Characteristics
When a transaction executes its first statement, it obtains a timestamp from MC as a read snapshot. During execution of read/write requests, the transaction accesses the Leader replica of the corresponding Replication Group for the data and creates a participant context on that replica. The participant context resides in memory, caching data written by the transaction on that Replication Group and holding pessimistic locks. Upon commit, one participant is selected as the coordinator, to which a commit request is sent containing the IDs of all Replication Groups accessed by the transaction. Upon receiving the request, the coordinator ensures atomicity of data commits across all participants following the 2PC protocol. Before starting the commit phase of 2PC, the coordinator obtains another timestamp from MC as commit_ts. This commit_ts is propagated to all participants via the 2PC commit request and serves as the sequence number for data writes in RocksDB. For visibility determination, the read timestamp of an operation is compared with the sequence number of each version. All versions with sequence numbers lower than the read timestamp are considered, and the version with the largest sequence number is selected for reading.
Data Caching
Transaction data is completely cached in memory before commit.
The SQLEngine layer does not cache transaction data; distributed caching is implemented by TDStore.
Operations for data persistence are performed only during the transaction commit phase.
Memory Management
The size of transaction data in memory (including uncommitted data and pessimistic lock information) is strictly restricted.
Developing the feature of early persistence for large transaction data to alleviate memory pressure and address the root cause.
Distributed Transaction Model: Commit Phase
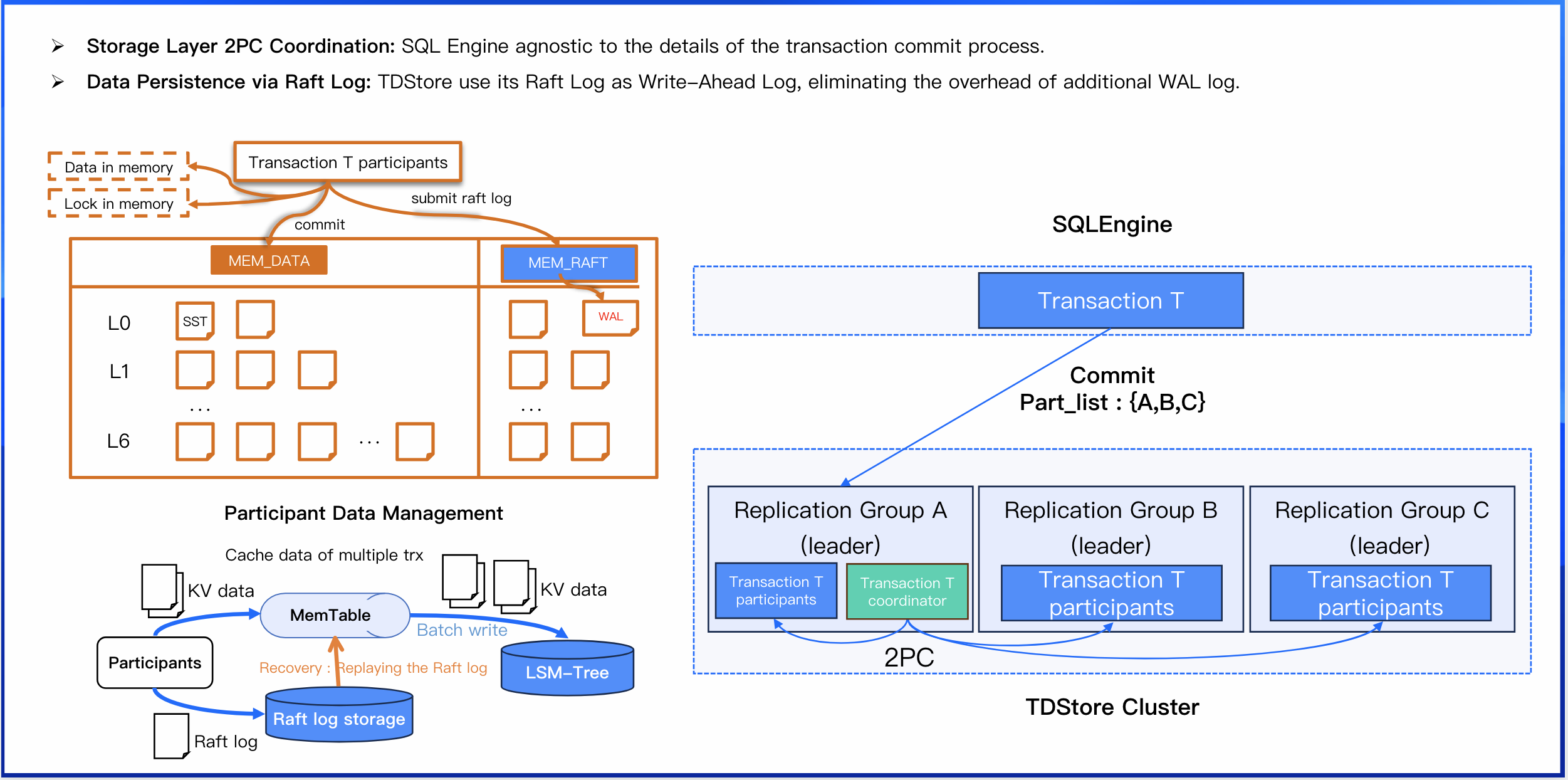
Storage Layer 2PC Coordination
SQL Engine agnostic to the details of the transaction commit process.
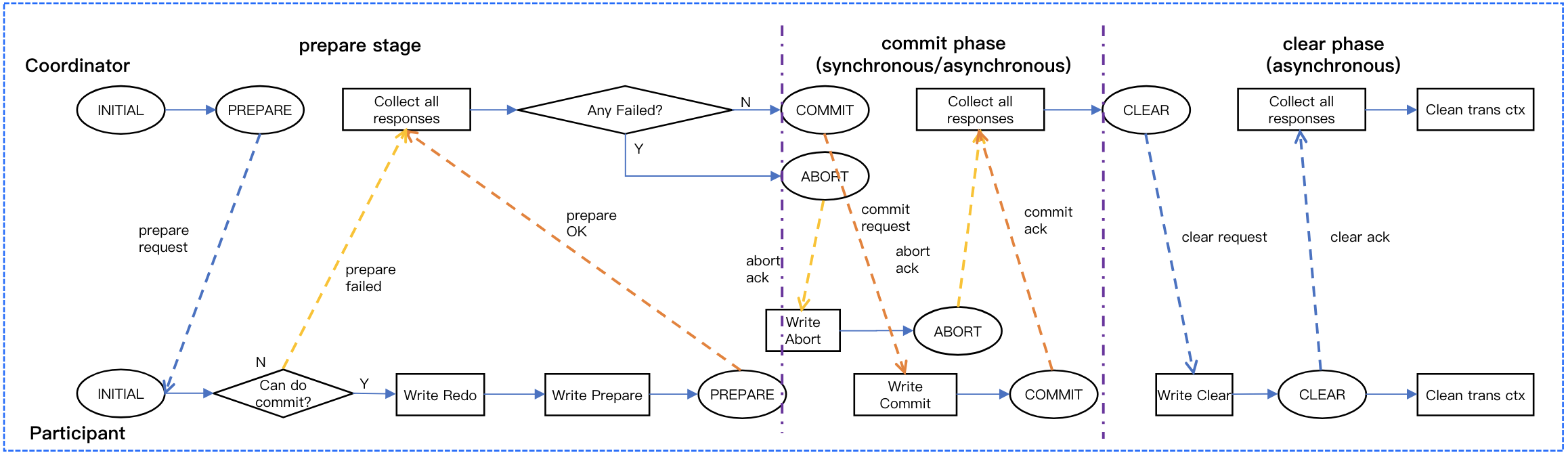
1. When submitting a distributed transaction, the SQLEngine selects one of the participants as the coordinator.
2. It sends a commit request to this designated coordinator, which includes a list of all other participants.
3. The node receiving the request creates a coordinator context within its own Replication Group.
4. This coordinator then orchestrates the entire 2PC process by sending prepare and commit requests to the other participants.
Data Persistence via Raft Log
TDStore use its Raft Log as Write-Ahead Log, eliminating the overhead of additional WAL log:
1. On restart, TDStore replays its Raft log from the last known checkpoint.
2. After data is flushed to disk (persisted), the log checkpoint is advanced. This reduces the amount of log data that needs to be replayed after a crash.
3. This single log serves a dual purpose: synchronizing data to replicas (via Raft) and enabling failure recovery. This design effectively eliminates a separate WAL write, reducing total disk I/O.
Distributed Transaction Commit Principles
The Bottleneck of Traditional 2PC: In a traditional two-phase commit(2PC) implementation, both the coordinator and the participants must perform synchronous logging. This results in five synchronous log writes across the entire process, which poses a significant performance bottleneck.
TDSQL Boundless Core Optimization: Distributed transaction across replication groups is guaranteed by TDSQL Boundless's negotiation-based 2PC. This approach eliminates the coordinator's logging overhead, ensuring atomicity for transactions across Replication Groups without the performance penalty of traditional 2PC.
|
RPC rounds | 2 rounds: prepare, commit | 3 rounds: prepare, commit, and an asynchronous clear phase |
Durable Log Writes | 5 writes = 2 writes on each participant + 3 writes on the coordinator | 3 writes on each participant (one of which is asynchronous). The coodinator is stateless and does not persistent any logs. |
Failure Handling & Recovery | After a crash restart, both the participants and coordinator can independently determine the transaction's final state by replaying their local logs. | After a crash restart, participants recover their state from their local logs, while the coordinator must query participants to reconstruct the transaction state. Participants are required to periodically send messages to the coordinator to report their status. |