TKE Serverless 클러스터의 컨테이너 네트워크를 생성 또는 수정하려면 어떻게 해야 합니까?
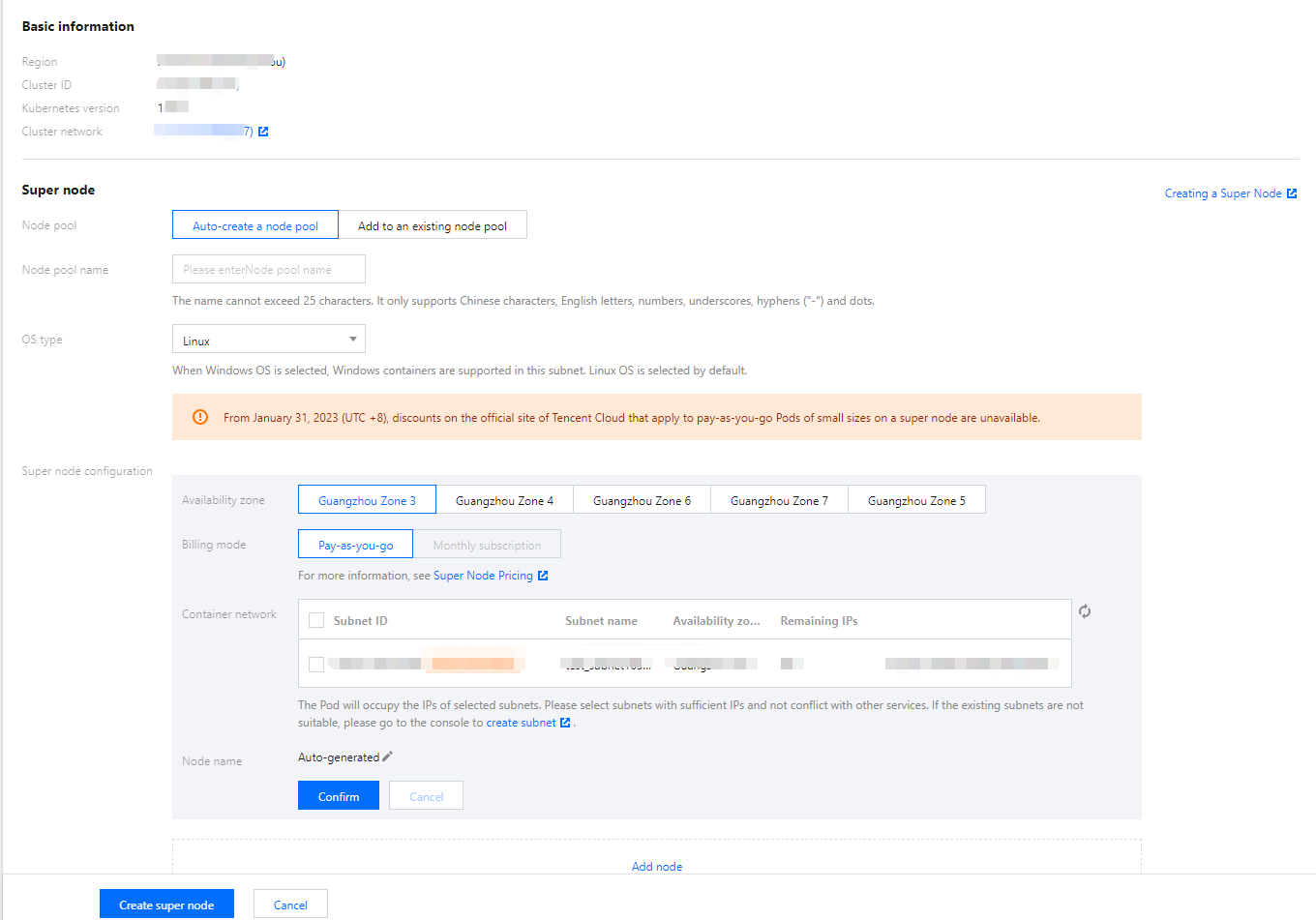
클러스터를 생성할 때 VPC를 클러스터 네트워크로 선택하고 서브넷을 컨테이너 네트워크로 지정해야 합니다. 자세한 내용은 컨테이너 네트워크 설명을 참고하십시오. Serverless의 Pod는 컨테이너 네트워크 서브넷의 IP 주소를 직접 점유합니다. 클러스터를 사용할 때 슈퍼 노드 생성 또는 삭제를 통해 컨테이너 네트워크를 생성하거나 수정할 수 있습니다. 자세한 지침은 아래와 같습니다.
2. 컨테이너 네트워크 수정이 필요한 클러스터 ID를 클릭하여 클러스터 기본 정보 페이지로 이동합니다.
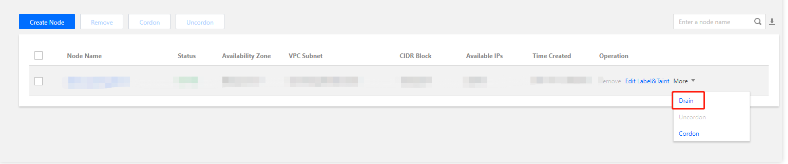
3. 왼쪽의 슈퍼 노드를 선택하고 슈퍼 노드 페이지에서 노드 이름 오른쪽의 더보기 > 드레이닝을 아래 이미지와 같이 선택합니다.
4. 드레인 노드 페이지에서 노드 정보를 확인하고 확인을 클릭합니다. 드레이닝 후 ‘차단됨’ 상태가 되며 더 이상 Pod를 스케쥴링할 수 없습니다.
참고
노드가 드레이닝되면 Pod가 다시 빌드됩니다.
5. 슈퍼 노드 페이지에서 노드 이름 오른쪽에 있는 삭제를 선택합니다.
6. 노드 삭제 페이지에서 확인을 클릭하면 노드 삭제 작업이 완료됩니다.
서브넷 IP 주소가 부족하여 Pod 스케쥴링에 실패하면 어떻게 해야 하나요?
서브넷 IP 주소가 부족하여 Pod 스케쥴링에 실패하면 노드 로그에서 두 개의 이벤트를 찾을 수 있습니다.
이벤트1:
이벤트2:
TKE 콘솔 또는 명령 라인 툴에서 다음 명령을 실행하여 슈퍼 노드의 YAML을 쿼리할 수 있습니다.
kubectl get nodes -oyaml
반환 결과는 다음과 같습니다.
spec:
taints:
-effect: NoSchedule
key: node.kubernetes.io/network-unavailable
timeAdded:"2021-04-20T07:00:16Z"
-lastHeartbeatTime:"2021-04-20T07:55:28Z"
lastTransitionTime:"2021-04-20T07:00:16Z"
message: eklet node has insufficient IP available of subnet subnet-bok73g4c
reason: EKLetHasInsufficientSubnetIP
status:"True"
type: NetworkUnavailable
컨테이너 네트워크의 서브넷 IP 주소가 부족하여 Pod 스케쥴링에 실패했음을 보여줍니다. 이 경우 서브넷과 사용 가능한 IP 범위를 추가하기 위해 슈퍼 노드를 생성해야 합니다. 슈퍼 노드 생성 방법은 슈퍼 노드 생성을 참고하십시오.
TKE Serverless 보안 그룹을 어떻게 사용합니까?
Serverless 클러스터 Pod 생성 시 보안 그룹을 지정하지 않으면 default 보안 그룹이 사용됩니다. Annotation eks.tke.cloud.tencent.com/security-group-id : 보안 그룹 ID를 통해서도 Pod에 대한 보안 그룹을 지정할 수 있습니다. 워크로드가 있는 리전에 보안 그룹 ID가 이미 있는지 확인하십시오. 이 Annotation에 대한 자세한 내용은 Annotation을 참고하십시오.
컨테이너 종료 메시지는 어떻게 설정합니까?
Kubernetes는 terminationMessagePath를 통해 컨테이너 종료의 메시지 소스를 설정할 수 있습니다. 즉, 컨테이너가 종료되면 Kubernetes는 컨테이너의 terminationMessagePath 필드에 지정된 종료 메시지 파일에서 종료 메시지를 검색하고 메시지를 사용하여 컨테이너 종료 메시지를 채웁니다. 메시지의 기본값은 /dev/termination-log입니다.
또한 컨테이너의 terminationMessagePolicy 필드를 설정하여 종료 메시지를 사용자 지정할 수 있습니다. 이 필드의 기본값은 File이며, 이는 종료 메시지가 종료 메시지 파일에서만 검색됨을 의미합니다. 필요에 따라 FallbackToLogsOnError로 설정할 수 있습니다. 이는 컨테이너가 오류와 함께 종료되고 종료 메시지 파일이 비어 있는 경우 컨테이너 로그 출력의 마지막 청크가 종료 메시지로 사용됨을 의미합니다.
예시 코드는 다음과 같습니다.
apiVersion: apps/v1beta2
kind: Deployment
metadata:
name: nginx
spec:
containers:
-image: nginx
imagePullPolicy: Always
name: nginx
resources:
limits:
cpu: 500m
memory: 1Gi
requests:
cpu: 250m
memory: 256Mi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: FallbackToLogsOnError
상기 구성에서 컨테이너가 오류와 함께 종료되고 종료 메시지 파일이 비어 있는 경우 Get Pod는 stderr의 출력이 containerStatuses에 표시되는 것을 찾습니다.
Host 매개변수는 어떻게 사용합니까?
Serverless 클러스터를 사용할 때 다음 사항에 유의하십시오.
Serverless 클러스터에는 노드가 없지만 Hostpath, Hostnetwork: true 및 DnsPolicy: ClusterFirstWithHostNet과 같은 Host 매개변수와 호환됩니다. 노드가 없기 때문에 이러한 매개변수는 k8s의 전체 기능을 제공할 수 없습니다.
예를 들어, Hostpath를 사용하여 데이터를 공유할 수 있지만 동일한 슈퍼 노드에 예약된 두 Pod는 서로 다른 호스트의 Hostpath를 보게 됩니다. 또한 Pod가 재구축되면 Hostpath 파일도 동시에 삭제됩니다.
CFS/NFS를 어떻게 마운트합니까?
Serverless 클러스터에서는 Tencent Cloud의 Cloud File Storage(CFS)를 사용하거나 외부 NFS를 Volume으로 Pod에 마운트하여 데이터를 영구 저장할 수 있습니다. Pod에 CFS/NFS를 마운트하는 YAML 예시는 다음과 같습니다.
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
-image: k8s.gcr.io/test-webserver
name: test-container
volumeMounts:
-mountPath: /cache
name: cache-volume
volumes:
-name: nfs
nfs:
path: /dir
server: 127.0.0.1
---
spec.volumes: 볼륨의 이름, 유형 및 매개변수를 설정합니다.
spec.volumes.nfs: NFS/CFS 디스크를 설정합니다.
spec.containers.volumeMounts: Pod에서 볼륨의 마운트 포인트를 설정합니다.
TKE Serverless는 컨테이너 이미지 캐시를 지원하여 동일한 이미지로 컨테이너의 다음 실행 속도를 높입니다.
재사용 조건:
1. 워크로드가 동일한 Pod의 경우 캐시 시간 내에 동일한 가용존(Zone)에서 Pod가 생성되고 종료되면 새 Pod는 기본적으로 동일한 이미지를 풀링하지 않습니다.
2. 다른 워크로드(Deployment, Statefulset 및 Job 포함)가 있는 Pod의 이미지를 재사용하려면 다음 annotation을 사용하십시오.
eks.tke.cloud.tencent.com/cbs-reuse-key
동일한 사용자 계정에서 동일한 annotation value를 가진 Pod의 경우, 시작 이미지는 캐시 시간 내에서 가능한 한 재사용됩니다. annntation value의 이미지 이름을 입력하는 것이 좋습니다: eks.tke.cloud.tencent.com/cbs-reuse-key: "image-name".
캐시 시간: 2시간.
예외적인 이미지 재사용 문제를 해결하는 방법은 무엇입니까?
이미지 재사용 기능이 활성화되고 Pod가 생성되면 $kubectl describe pod에서 다음 오류가 발생할 수 있습니다.
no space left on device: unknown
Warning FreeDiskSpaceFailed 26m eklet, eklet-subnet-xxx failed to garbage collect required amount of images. Wanted to free 4220828057 bytes, but freed 3889267064 bytes
솔루션:
작업이 필요하지 않습니다. 몇 분 정도 기다리면 Pod가 자동으로 running됩니다.
원인:
no space left on device: unknown
Pod가 기본적으로 시스템 디스크를 재사용하는 경우, 시스템 디스크의 원본 이미지가 모든 공간을 차지하고 디스크에 새 이미지를 다운로드할 공간이 부족하여 ‘no space left on device: unknown’ 오류가 보고됩니다. TKE Serverless는 전체 공간이 점유되면 시스템 디스크의 기존 중복 이미지를 자동으로 삭제하여 현재 디스크를 확보하는 일반적인 이미지 회수 메커니즘을 지원합니다.(몇 분 소요됨)
Warning FreeDiskSpaceFailed 26m eklet, eklet-subnet-xxx failed to garbage collect required amount of images. Wanted to free 4220828057 bytes, but freed 3889267064 bytes
이 로그는 현재 Pod가 이미지를 다운로드하는 데 4220828057바이트가 필요하지만 현재는 3889267064바이트만 사용할 수 있음을 보여줍니다. 이 event 원인은 디스크에 여러 이미지가 있고 일부 이미지만 해제되었기 때문입니다. TKE Serverless의 일반 이미지 회수 메커니즘은 새 이미지를 성공적으로 가져올 수 있을 때까지 계속 해제됩니다.
외부 nfs를 마운트할 때 Operation not permitted가 보고되면 어떻게 해야 합니까?
영구 스토리지에 외부 nfs를 사용하는 경우 연결이 설정되면 Operation not permitted 이벤트가 보고됩니다. nfs의 /etc/exports 파일을 수정하고 /<path><ip-range>(rw,insecure) 매개변수를 추가해야 합니다. 아래 예시를 참고하십시오.
/data/ 10.0.0.0/16(rw,insecure)
Pod 디스크가 가득 찬 경우(ImageGCFailed) 어떻게 해야 하나요?
TKE Serverless의 Pod는 기본적으로 20GB의 여유 시스템 디스크 공간을 제공합니다. 디스크가 꽉 찬 경우 다음과 같은 방법으로 디스크를 비울 수 있습니다.
1. 사용하지 않는 컨테이너 이미지 정리
공간의 80%가 사용된 경우 TKE Serverless 백엔드는 컨테이너 이미지 재소유 프로세스를 트리거하여 사용하지 않는 이미지를 복구하고 공간을 확보합니다. 이것이 실패하면 ImageGCFailed: failed to garbage collect required amount of images가 보고되어 디스크 공간이 부족함을 알려줍니다.
디스크 공간 부족의 일반적인 원인은 다음과 같습니다.
비즈니스에는 많은 임시 출력이 있습니다. du 명령으로 이를 확인할 수 있습니다.
비즈니스는 삭제된 파일 설명자를 보유하므로 디스크 공간이 확보되지 않습니다. lsof 명령으로 이를 확인할 수 있습니다.