TKE DNS 모범 사례
다운로드
포커스 모드
폰트 크기
개요
DNS는 Kubernetes 클러스터에서 서비스 액세스의 첫 번째 단계이므로 안정성과 성능이 매우 중요합니다. DNS를 더 나은 방식으로 구성하고 사용하는 방법에는 여러 측면이 포함됩니다. 본 문서는 DNS의 모범 사례를 소개합니다.
가장 적합한 CoreDNS 버전 선택
다음 표에는 다양한 버전의 TKE 클러스터에 배포된 기본 CoreDNS 버전이 나열되어 있습니다.
기존 이유로 CoreDNS v1.6.2는 v1.18 이상의 클러스터에 계속 배포될 수 있습니다. 현재 CoreDNS 버전이 요구 사항을 충족하지 않는 경우 다음과 같이 수동으로 업그레이드할 수 있습니다.
적절한 수의 CoreDNS 복제본 구성
1. TKE의 기본 CoreDNS 복제본 수는 2개이며 podAntiAffinity는 서로 다른 노드에 두 개의 복제본을 배포하도록 구성되었습니다.
2. 클러스터에 80개가 넘는 노드가 있는 경우 TKE 클러스터에서 NodeLocal DNSCache 사용에 따라 NodeLocal DNSCache를 설치하는 것이 좋습니다.
3. 일반적으로 DNS에 대한 비즈니스 액세스의 QPS, 노드 수 또는 총 CPU 코어 수를 기반으로 CoreDNS 복제본 수를 결정할 수 있습니다. NodeLocal DNSCache를 설치한 후 최대 10개의 CoreDNS 복제본을 사용하는 것이 좋습니다. 다음과 같이 복제본 수를 구성할 수 있습니다.
복제본 수 = min ( max ( ceil (QPS/10000), ceil (클러스터 노드 수/8) ), 10 )
예시:
클러스터에 10개의 노드가 있고 DNS 서비스 요청의 QPS가 22000인 경우 복제본 수를 3으로 구성합니다
클러스터에 30개의 노드가 있고 DNS 서비스 요청의 QPS가 15000인 경우 복제본 수를 4로 구성합니다
클러스터에 100개의 노드가 있고 DNS 서비스 요청의 QPS가 50000인 경우 복제본 수를 10으로 구성합니다(NodeLocal DNSCache가 배포됨)
4. 콘솔에 DNSAutoScaler 애드온을 설치하여 CoreDNS 복제본 수를 자동으로 조정할 수 있습니다(원활한 업그레이드는 사전에 구성해야 함). 다음은 기본 구성입니다.
data:ladder: |-{"coresToReplicas":[[ 1, 1 ],[ 128, 3 ],[ 512,4 ],],"nodesToReplicas":[[ 1, 1 ],[ 2, 2 ]]}
NodeLocal DNSCache 사용
NodeLocal DNSCache를 TKE 클러스터에 배포하면 서비스 검색 안정성 및 성능을 개선할 수 있습니다. 클러스터 노드에서 DaemonSet으로 DNS 캐시 에이전트를 실행하여 클러스터 DNS 성능을 향상시킵니다.
NodeLocal DNSCache 및 TKE 클러스터에서 NodeLocal DNSCache를 배포하는 방법에 대한 자세한 내용은 TKE 클러스터에서 NodeLocal DNS Cache 사용을 참고하십시오.
CoreDNS 원활한 업그레이드 구성
노드를 다시 시작하거나 CoreDNS를 업그레이드하는 동안 일정 기간 동안 일부 CoreDNS 복제본을 사용하지 못할 수 있습니다. 다음 항목을 구성하여 DNS 서비스 가용성을 최대화하고 원활한 업그레이드를 구현할 수 있습니다.
kube-proxy는 iptables 모드, 구성할 필요 없음
iptables 모드에서 kube-proxy는 iptables 규칙을 동기화한 후 남아 있는 conntrack 항목을 즉시 정리합니다. 세션 유지 문제가 없으며 구성이 필요하지 않습니다.
kube-proxy는 IPVS 모드. IPVS UDP 프로토콜의 세션 지속성 제한 시간 구성
IPVS 모드에서는 비즈니스 자체에 UDP 서비스가 없는 경우 IPVS UDP 프로토콜의 세션 유지 시간 제한을 줄여 서비스 이용 불가 시간을 최소화할 수 있습니다.
1. 클러스터가 v1.18 이상인 경우 kube-proxy는
--ipvs-udp-timeout 매개변수에 기본값 0s를 제공하거나 시스템 기본값 300s를 사용할 수 있습니다. --ipvs-udp-timeout=10s를 구성하는 것이 좋습니다. 다음과 같이 kube-proxy DaemonSet를 구성합니다.spec:containers:- args:- --kubeconfig=/var/lib/kube-proxy/config- --hostname-override=$(NODE_NAME)- --v=2- --proxy-mode=ipvs- --ipvs-scheduler=rr- --nodeport-addresses=$(HOST_IP)/32- --ipvs-udp-timeout=10scommand:- kube-proxyname: kube-proxy
2. 클러스터가 v1.16 이하인 경우 kube-proxy는 이 매개변수를 지원하지 않으며
ipvsadm 툴을 사용하여 다음과 같이 노드의 정보를 일괄 수정할 수 있습니다.yum install -y ipvsadmipvsadm --set 900 120 10
3. 구성을 완료한 후 다음과 같이 결과를 확인합니다.
ipvsadm -L --timeoutTimeout (tcp tcpfin udp): 900 120 10
주의사항
CoreDNS에 대한 정상 종료 구성
이미 종료 신호를 받은 복제본이 일정 시간 동안 서비스를 계속 제공하도록 lameduck을 구성할 수 있습니다. 다음과 같이 CoreDNS ConfigMap을 구성합니다(아래는 CoreDNS 1.6.2 구성의 일부일 뿐입니다. 다른 버전의 구성은 CoreDNS 수동 업그레이드를 참고하십시오).
.:53 {health {lameduck 30s}kubernetes cluster.local. in-addr.arpa ip6.arpa {pods insecureupstreamfallthrough in-addr.arpa ip6.arpa}}
CoreDNS 서비스 준비 확인 구성
새 복제본이 시작된 후 서비스 준비 상태를 확인하고 DNS 서비스의 백엔드 목록에 추가해야 합니다.
1. ready 플러그인을 열고 CoreDNS configmap을 다음과 같이 구성합니다(아래는 CoreDNS 1.6.2 구성의 일부일 뿐입니다. 다른 버전의 구성은 CoreDNS 수동 업그레이드를 참고하십시오).
.:53 {readykubernetes cluster.local. in-addr.arpa ip6.arpa {pods insecureupstreamfallthrough in-addr.arpa ip6.arpa}}
2. CoreDNS에 대한 ReadinessProbe 구성 추가:
readinessProbe:failureThreshold: 5httpGet:path: /readyport: 8181scheme: HTTPinitialDelaySeconds: 30periodSeconds: 10successThreshold: 1timeoutSeconds: 5
UDP를 통해 업스트림 DNS에 액세스하도록 CoreDNS 구성
CoreDNS가 DNS Server와 통신해야 하는 경우 기본적으로 클라이언트 요청 프로토콜(UDP 또는 TCP)을 사용합니다. 그러나 TKE에서 CoreDNS의 업스트림 서비스는 기본적으로 TCP에 대한 제한된 지원을 제공하는 VPC의 DNS 서비스입니다. 따라서 다음과 같이 UDP를 사용하여 구성하는 것이 좋습니다(특히 NodeLocal DNSCache가 설치된 경우).
.:53 {forward . /etc/resolv.conf {prefer_udp}}
HINFO 요청을 필터링하도록 CoreDNS 구성
VPC의 DNS 서비스는 HINFO 유형의 DNS 요청을 지원하지 않으므로 CoreDNS 측(특히 NodeLocal DNSCache가 설치된 경우)에서 이러한 요청을 필터링하도록 다음과 같이 구성하는 것이 좋습니다.
.:53 {template ANY HINFO . {rcode NXDOMAIN}}
IPv6 AAAA 레코드 쿼리에 대해 도메인 이름이 존재하지 않음을 반환하도록 CoreDNS 구성
비즈니스에서 IPv6 도메인 이름을 확인할 필요가 없는 경우 통신 비용을 줄이기 위해 다음과 같이 구성할 수 있습니다.
.:53 {template ANY AAAA {rcode NXDOMAIN}}
주의사항
IPv4/IPv6 이중 스택 클러스터에서는 이 구성을 사용하지 마십시오.
사용자 지정 도메인 이름 확인 구성
수동 업그레이드
v1.7.0으로 업그레이드
1. coredns configmap 편집
kubectl edit cm coredns -n kube-system
다음과 같이 내용을 수정합니다.
.:53 {template ANY HINFO . {rcode NXDOMAIN}errorshealth {lameduck 30s}readykubernetes cluster.local. in-addr.arpa ip6.arpa {pods insecurefallthrough in-addr.arpa ip6.arpa}prometheus :9153forward . /etc/resolv.conf {prefer_udp}cache 30reloadloadbalance}
2. coredns deployment 편집
kubectl edit deployment coredns -n kube-system
다음과 같이 이미지를 바꿉니다
image: ccr.ccs.tencentyun.com/tkeimages/coredns:1.7.0
v1.8.4로 업그레이드
1. coredns clusterrole 편집
kubectl edit clusterrole system:coredns
다음과 같이 내용을 수정합니다.
rules:- apiGroups:- '*'resources:- endpoints- services- pods- namespacesverbs:- list- watch- apiGroups:- discovery.k8s.ioresources:- endpointslicesverbs:- list- watch
2. coredns configmap 편집
kubectl edit cm coredns -n kube-system
다음과 같이 내용을 수정합니다.
.:53 {template ANY HINFO . {rcode NXDOMAIN}errorshealth {lameduck 30s}readykubernetes cluster.local. in-addr.arpa ip6.arpa {pods insecurefallthrough in-addr.arpa ip6.arpa}prometheus :9153forward . /etc/resolv.conf {prefer_udp}cache 30reloadloadbalance}
3. coredns deployment 편집
kubectl edit deployment coredns -n kube-system
다음과 같이 이미지를 바꿉니다
image: ccr.ccs.tencentyun.com/tkeimages/coredns:1.8.4
비즈니스 구성에 대한 제안
DNS 서비스의 모범 사례 외에도 비즈니스 측면에서 적절한 최적화 구성을 수행하여 DNS 사용자 경험을 개선할 수 있습니다.
1. 기본적으로 Kubernetes 클러스터의 도메인 이름은 일반적으로 여러 확인 요청 후에 확인할 수 있습니다. pod에서
/etc/resolv.conf 를 보면 ndots 의 기본값이 5임을 알 수 있습니다. 예를 들어, debug 네임스페이스의 kubernetes.default.svc.cluster.local service가 쿼리되는 경우:도메인 이름에
. 이 4개 있으므로 시스템에서 쿼리에 kubernetes.default.svc.cluster.local.debug.svc.cluster.local 을 사용하기 위해 첫 번째 search를 추가하려고 시도하지만 도메인 이름을 찾을 수 없습니다.시스템은 쿼리에
kubernetes.default.svc.cluster.local.svc.cluster.local 을 계속 사용하지만 여전히 도메인 이름을 찾을 수 없습니다.시스템은 쿼리에
kubernetes.default.svc.cluster.local.cluster.local l을 계속 사용하지만 여전히 도메인 이름을 찾을 수 없습니다.시스템은 확장을 추가하지 않고
kubernetes.default.svc.cluster.local 을 사용하려고 시도합니다. 쿼리가 성공하고 응답하는 ClusterIP가 반환됩니다.2. 상기 간단한 service 도메인 이름은 네 가지 확인 후 성공적으로 레졸루션할 수 있으며 클러스터에는 쓸모없는 DNS 요청이 많이 있습니다. 따라서 쿼리 수를 줄이기 위해 비즈니스에 대해 구성된 액세스 유형을 기반으로 적절한 ndots 값을 설정해야 합니다.
spec:dnsConfig:options:- name: ndotsvalue: "2"containers:- image: nginximagePullPolicy: IfNotPresentname: diagnosis
3. 또한 비즈니스에서 서비스에 액세스할 수 있도록 도메인 이름 구성을 최적화할 수 있습니다.
Pod는
<service-name>을 통해 현재 네임스페이스의 Service에 액세스해야 합니다.Pod는
<service-name>.<namespace-name>을 통해 다른 네임스페이스의 Service에 액세스해야 합니다.Pod는 쓸데없는 검색을 줄이기 위해 끝에
. 이 추가된 FQDN(정규화된 도메인 이름)을 통해 외부 도메인 이름에 액세스해야 합니다.관련 내용
구성 설명
errors
오류 메시지를 출력합니다.
health
상태를 리포트하고
livenessProbe와 같은 상태 확인 구성에 사용됩니다. 기본적으로 포트 8080에서 수신하고 http://localhost:8080/health 경로를 사용합니다.주의사항
여러 Server 블록이 있는 경우 health를 한 번만 구성하거나 다른 포트에 대해 구성할 수 있습니다.
com {whoamihealth :8080}net {erratichealth :8081}
lameduck
정상적인 종료 기간을 구성하는 데 사용됩니다. hook는 CoreDNS가 종료 신호를 수신할 때 sleep 모드를 실행하여 서비스가 특정 시간 동안 계속 실행될 수 있도록 하는 구현 방법입니다.
ready
플러그인 상태를 리포트하고
readinessProbe와 같은 서비스 준비 확인 구성에 사용됩니다. 기본적으로 포트 8181에서 수신하고 http://localhost:8181/ready 경로를 사용합니다.kubernetes
클러스터에서 서비스를 레졸루션할 수 있는 Kubernetes 플러그인입니다.
prometheus
모니터링 데이터를 가져오는 데 사용되는 metrics 데이터 API입니다. 해당 경로는
http://localhost:9153/metrics입니다.forward(proxy)
처리되지 않은 요청을 업스트림 DNS 서버로 포워딩하고 기본적으로 호스트의
/etc/resolv.conf 구성을 사용합니다.forward aaa bbb의 구성에 따라 업스트림 udns 서버 목록 [aaa,bbb]는 내부적으로 유지됩니다.
요청이 도착하면 사전 설정된 정책(random|round_robin|sequential, 여기서 random이 기본 정책)에 따라 요청을 포워딩하기 위해 [aaa,bbb] 목록에서 업스트림 udns 서버가 선택됩니다. 포워딩에 실패하면 포워딩을 위해 다른 서버가 선택되고 정상적인 상태가 될 때까지 실패한 서버에 대해 정기적인 상태 확인이 수행됩니다.
서버가 연속해서 여러 번(기본적으로 두 번) 상태 검사에 실패하면 해당 udns 상태가 down으로 설정되고 후속 서버 선택에서 down 상태인 udns는 건너뜁니다.
모든 udns가 down된 경우 시스템은 포워딩할 udns를 무작위로 선택합니다.
따라서 coredns는 여러 upstream 서버 간에 지능적으로 전환할 수 있습니다. forward 목록에 사용 가능한 udns 서버가 있는 한 요청이 성공할 수 있습니다.
cache
DNS 캐시입니다.
reload
Corefile을 핫로딩합니다. ConfigMap이 수정된 후 2분 안에 새 구성을 다시 로딩합니다.
loadbalance
응답의 레코드 순서를 무작위로 지정하여 DNS 기반의 로드 밸런싱 기능을 제공합니다.
CoreDNS의 리소스 사용량
클러스터의 Pod 및 Service 수에 따라 달라집니다.
활성화된 캐시 크기의 영향을 받습니다.
QPS의 영향을 받습니다.
다음은 CoreDNS의 공식 데이터입니다.
MB required (default settings) = (Pods + Services) / 1000 + 54
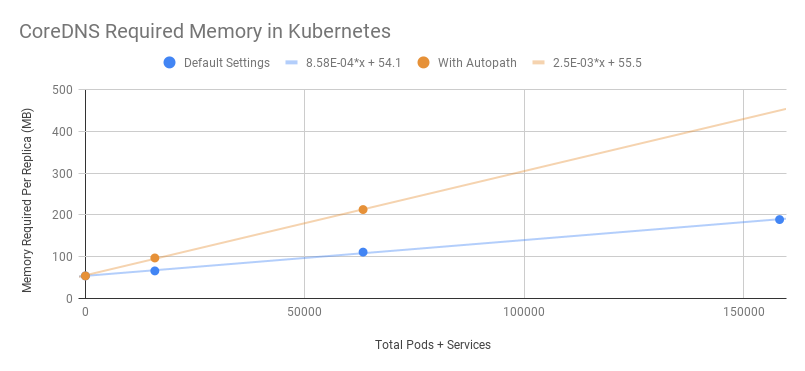
QPS의 영향을 받습니다.
다음은 CoreDNS의 공식 데이터입니다.
단일 복제 CoreDNS, 실행 중인 노드 사양: 2 vCPUs, 7.5 GB memory
Query Type | QPS | Avg Latency (ms) | Memory Delta (MB) |
external | 6733 | 12.02 | +5 |
internal | 33669 | 2.608 | +5 |
피드백