大模型视频摘要接入
Download
聚焦模式
字号
免费体验
说明:
体验馆功能较简单,仅用于体验基础效果,测试完整效果请使用 API 接入。
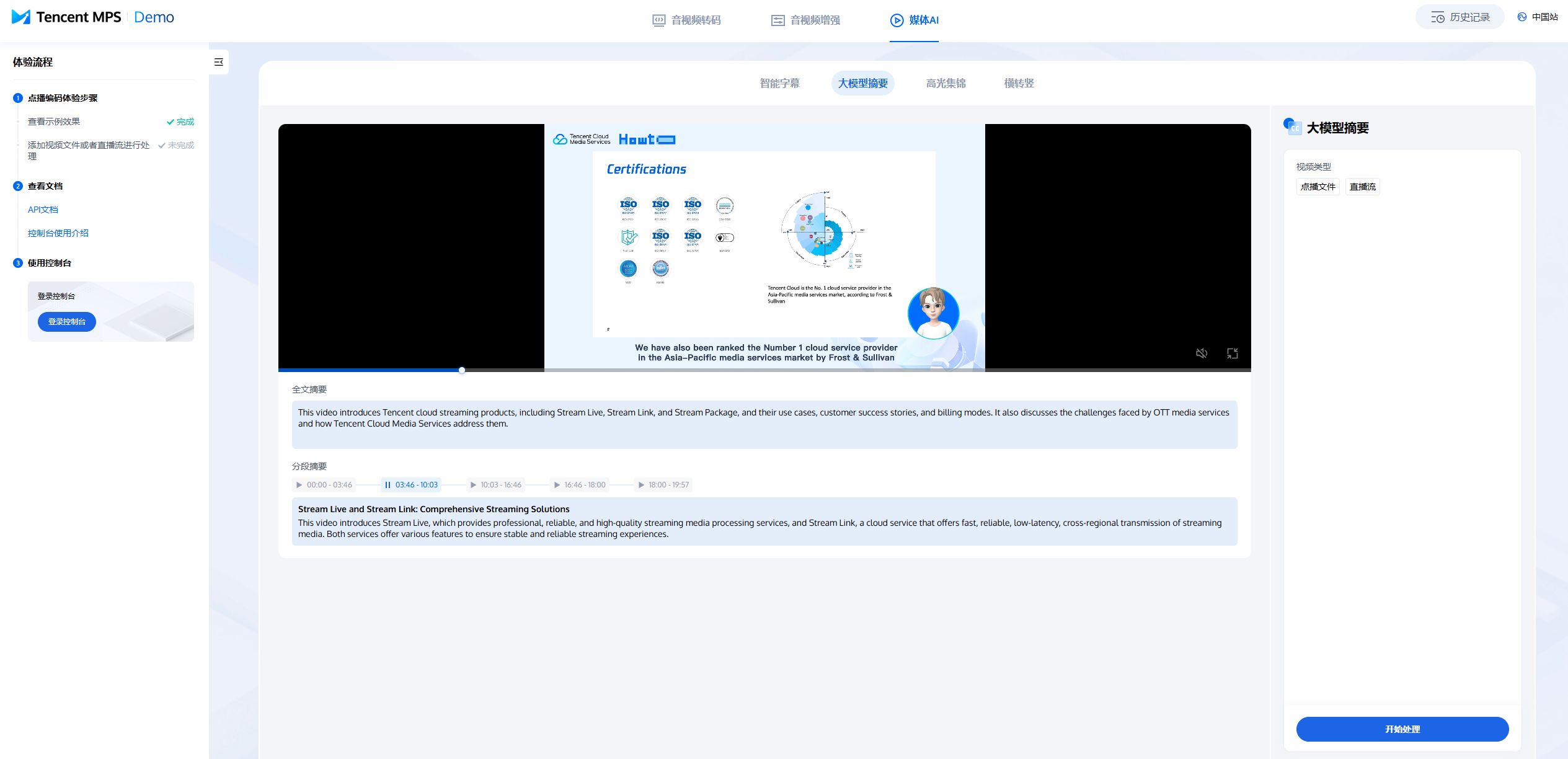
1. 打开 体验馆,进入 LLM Summarize 体验页,选择离线视频(Offline File)或直播流(Live Streaming),单击开始处理(One-Click Processing)。
2. 等待处理完成后即可查看结果。
API 接入
发起摘要任务
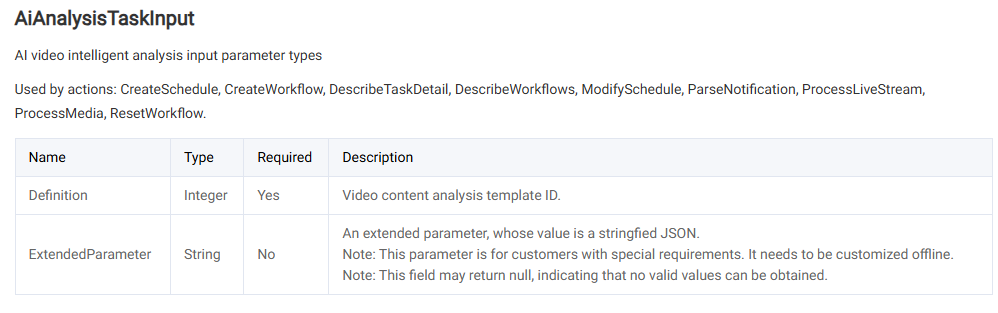
调用 媒体处理接口 ,选择 AiAnalysisTask 任务,将 Definition 设置为 22(预设大模型视频摘要模板)。ExtendedParameter 填额外的扩展参数,通过该参数实现特定的能力,取值详情见下文 扩展参数说明。
示例:
{"InputInfo": {"Type": "URL","UrlInputInfo": {"Url": "https://facedetectioncos-1251132611.cos.ap-guangzhou.myqcloud.com/video/xxx.mp4" // 替换成需要摘要的视频 URL}},"AiAnalysisTask": {"Definition": 22, //预设大模型视频摘要模板 ID"ExtendedParameter": "{\\"des\\":{\\"split\\":{\\"method\\":\\"llm\\",\\"model\\":\\"deepseek-v3\\"}}}"},"OutputStorage": {"CosOutputStorage": {"Bucket": "test-mps-123456789","Region": "ap-guangzhou"},"Type": "COS"},"OutputDir": "/output/","TaskNotifyConfig": {"NotifyType": "URL","NotifyUrl": "http://qq.com/callback/qtatest/?token=xxxxxx"},"Action": "ProcessMedia","Version": "2019-06-12"}
API Explorer 快速验证
扩展参数说明
ExtendedParameter 用于对摘要任务进行个性设置,可先不填,结合默认效果,对需要改进方向按需使用。
注意:
API Explorer 会自动转换,ExtendedParameter 填写对应 json 即可,不用转换成字符串。如果是直接调用 API,那么需要对 json 字符串转义。
ExtendedParameter全部可选参数及其说明参考下表:
{"des": {"split": {"method": "llm","model": "deepseek-v3","max_split_time_sec": 100,"extend_prompt": "本视频为医疗场景视频,按照医疗相关知识点对视频进行分段"},"need_ocr": true,"ocr_type": "ppt","only_segment": 0,"text_requirement": "摘要在40字以内","dstlang": "zh"}}
参数 | 是否必填 | 类型 | 说明 |
split.method | No | string | 视频分段方法,llm 表示大模型分段,nlp 表示传统 nlp 分段,默认为 llm。 |
split.model | No | string | 分段大模型,可选 hunyuan,deepseek-v3,deepseek-r1,默认为 deepseek-v3。 |
split.max_split_time_sec | No | int | 强制指定最大分段时间,单位秒。建议必要情况下再使用,可能影响分段效果。默认3600。 |
split.extend_prompt | No | string | 补充大模型分段任务提示词,如“本视频为教学视频,按照相关知识点对视频进行分段”。建议先不填进行测试,效果不达预期时再补充。 |
need_ocr | No | bool | 是否使用 ocr 辅助分段,true 表示开启,默认为 false。 不开启,系统仅识别视频语音内容辅助视频分段;开启,还会识别视频画面上的文字内容辅助视频分段。 |
ocr_type | No | string | ocr 辅助类型,ppt 表示将画面作为 ppt,按 ppt 翻页进行视频分段,other 表示其他,默认为 ppt。 |
only_segment | No | int | 是否只分段,不生成摘要,默认为0。 1:只分段,不生成摘要。 0:分段且生成摘要。 |
text_requirement | No | string | 补充大模型摘要任务提示词。例如限制字数"摘要在40字以内"。 |
dstlang | No | string | 视频语言,用于视频语音识别与摘要相关结果语言指定,默认为"zh"。 "zh":中文 "en":英文 |
查询任务结果
任务回调:在使用 ProcessMedia 发起媒体处理任务时,可以通过 TaskNotifyConfig 参数设置回调信息。当任务处理完成后,会通过配置的回调信息回调任务结果,您可以通过 ParseNotification 解析事件通知结果。
使用 ProcessMedia 返回的 TaskId 调用 查询任务详情 接口查询任务处理结果。解析 WorkflowTask > AiAnalysisResultSet > DescriptionTask > Output > DescriptionSet > MediaAiAnalysisDescriptionItem 即可。
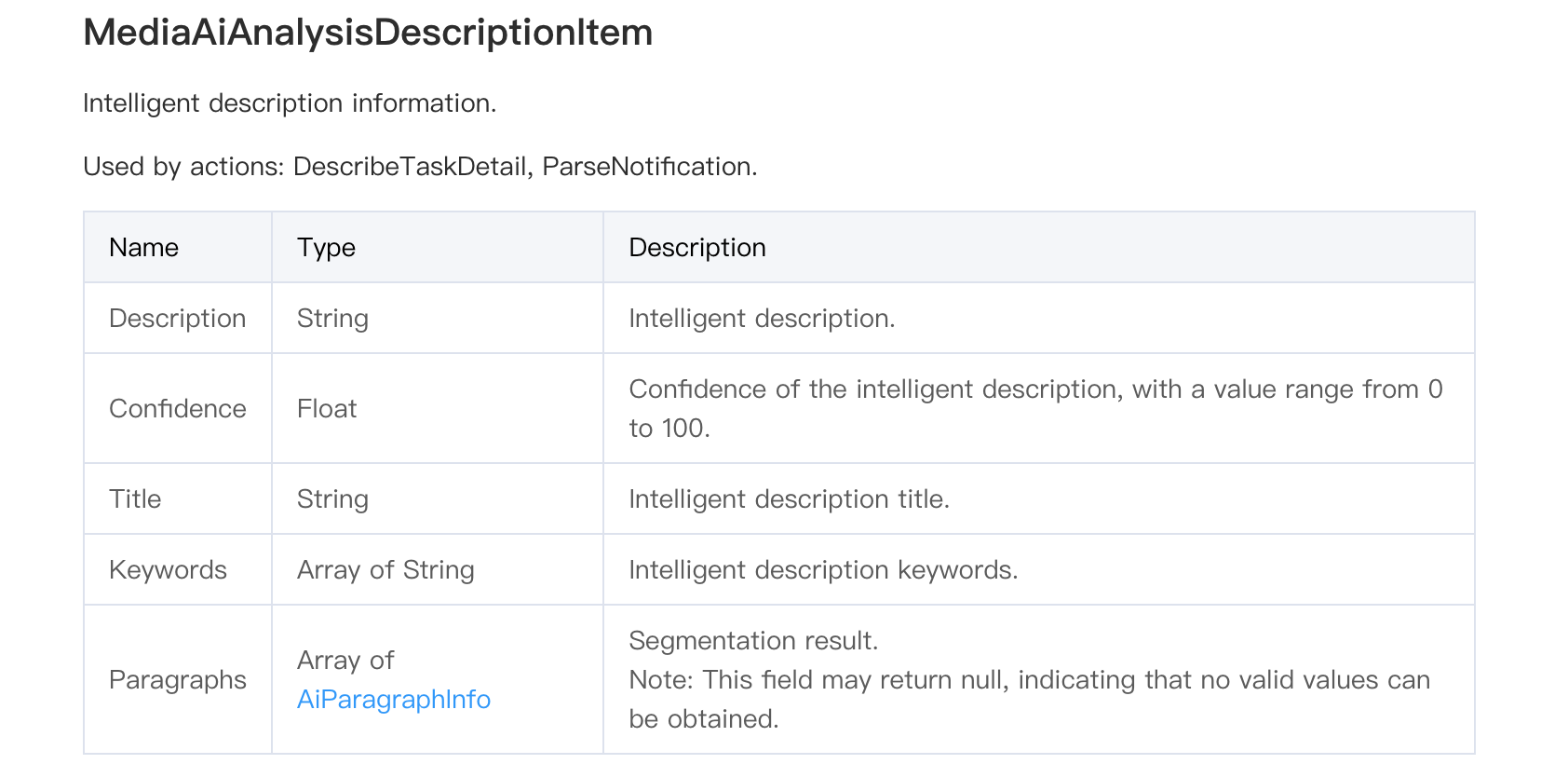
Description 对应整个视频摘要,Paragraphs 对应整个视频的智能分段结果以及每个分段的摘要。
文档反馈