识别效果问题排查
Download
聚焦模式
字号
如您在使用语音识别时,发现转写的结果与您预期有一些差距,可根据本篇文档进行问题排查。
问题排查步骤
分为如下几种常见情况:
1. 本身音频内容靠正常的人耳听不清楚或者听不懂,这类情况建议对于前端的采音环境进行改造,如采音距离由远场改为近场,采音环境的噪音尽量控制和减少,口音、方言尽量控制在带口音的普通话(即非本地人可听懂)以及改善语速过快造成的吞音。
2. 本身音频内容可以听懂,但识别结果与听到的内容相差很大。这类情况一般是音频信息不满足语音识别服务要求导致的。
通过 cooledit、Adobe Audition 或者 FFmpeg 查看音频的详细信息,包括采样率、声道数和位深。语音识别服务目前仅支持8000Hz或者16000Hz采样率、16bits位深,实时语音识别仅支持单声道。注:如果您使用的是实时语音识别,音频属性必须严格符合上述要求。
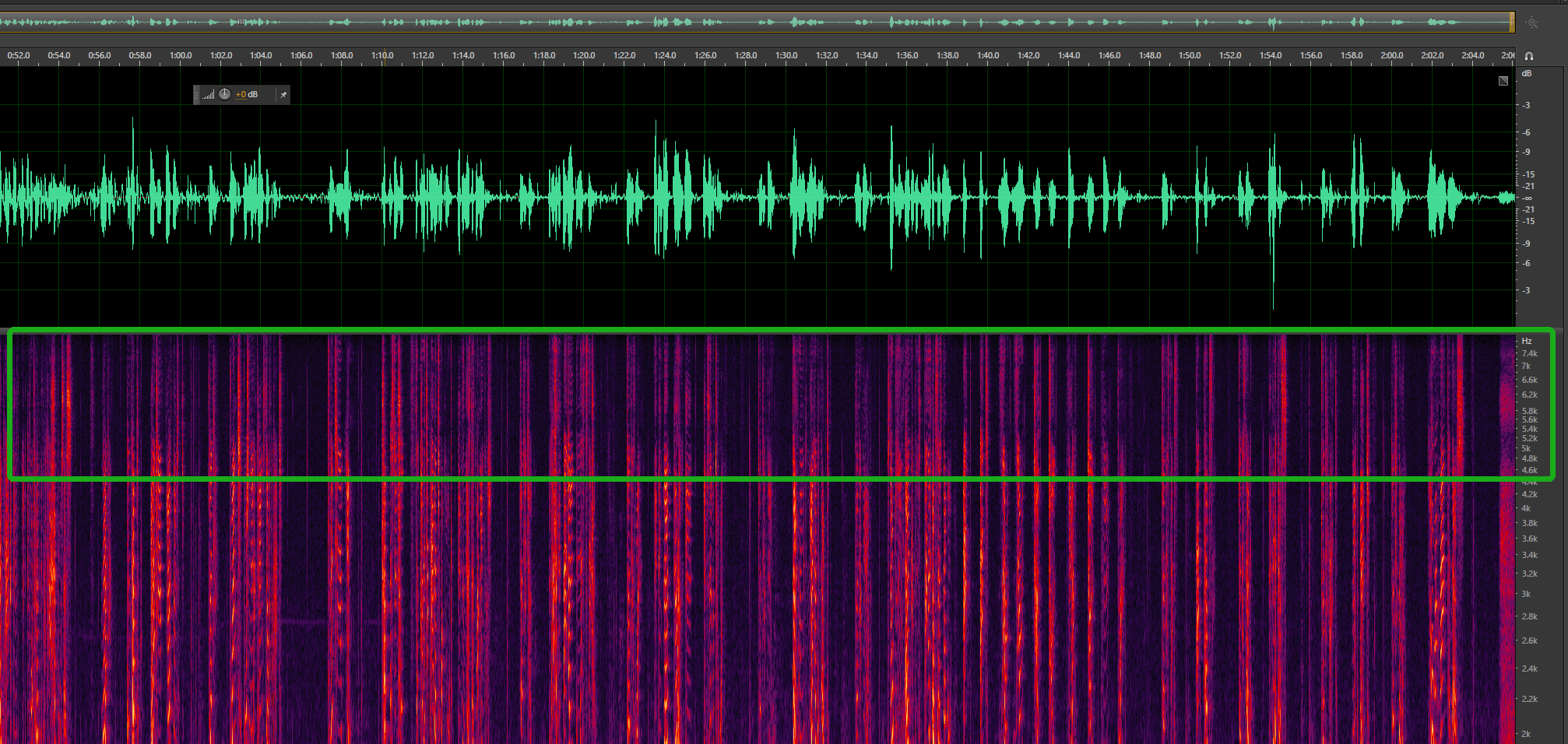
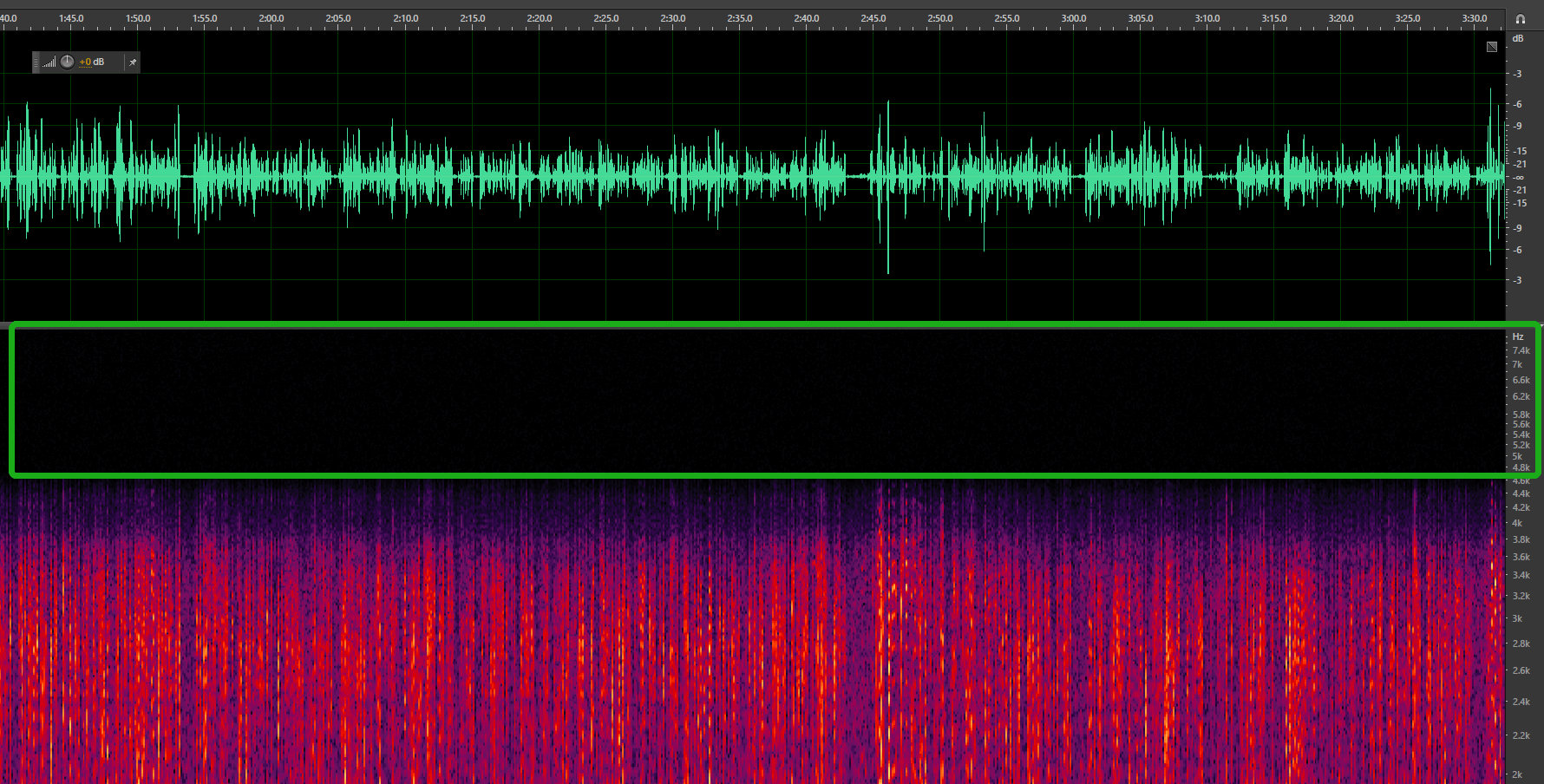
查看音频的波形和频谱(Adobe Audition 在视图选项中)来判断实际音频真实的采样率,建议真实采样率要满足语音识别的要求(8k电话引擎模型对应8000kHz采样率,16k非电话引擎模型对应16000kHz采样率)。
真实16000Hz(真实采样率 = 框出来的右侧数值的最高值 × 2,即8kHz × 2=16kHz)音频的波形和频谱如下:
3. 本身音频内容可以听懂,并且识别结果与听到的内容相差不大,但有一些特有的名词或者句子识别不好,可通过如下步骤提升识别效果:
4. 本身音频内容可以听懂,并且识别结果与听到的内容相差不大,但会多出来一些识别结果。这类一般是因为噪声造成的,噪声分为两种,一种是非人声的噪音,一种是人声的噪音。本身 ASR 算法对于第一类噪音做过一定的适配和优化,这一类可以提供具体的 badcase 给到腾讯来分析优化,但对于第二类人声噪音较难解决,因为会对于真正需要识别出来的人声的造成误伤。
文档反馈